






2023年7月2日
AI竞赛
深度之眼7-11
主流模型:LightGBM、XGBoost、CatBoost
home_data = pd.read_csv(file_path)
y = home_data.SalePrice
features = [...,...]
X = home_data[features]
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state = 1)
gbm = LGBMRegressor(objective='regression', num_leaves=31, learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set={(X_val, y_val)}, eval_metric='l1', early_stopping_round=5)LightGBM详细解释:LightGBM回归预测模型构建 - 含GBM调参方法 - 知乎 (zhihu.com)
算法
二分查找
1.target在左闭右闭的区间里[left, right]
while (left <= right) 因为left==right是有意义的
if (nums[middle] > target)更新right = middle - 1 因为middle一定不是target
时间复杂度O(logn)
int binsearch(int nums[], int target){
int l = 0;
int r = n - 1;
while (l <= r){
int mid = (l + r) / 2;
if (nums[mid] > target) r = mid - 1;
else if (nums[mid] < target) l = mid + 1;
else return mid;
}
return -1;
}2.target在左闭右开的区间里[left, right)
while (left < right) 因为left==right在[left,right)是没有意义的。
if (nums[middle] > target) 更新 right = middle
int binsearch(int nums[], int target){
int l = 0;
int r = n
while (l <= r){
int mid = l + ((r - l) >> 1);
if (nums[mid] > target) r = mid;
else if (nums[mid] < target) l = mid + 1;
else return mid;
}
return -1;
}完成题目:
2023年7月3日
AI竞赛
深度之眼12-13
连续数据预处理:
补充缺失值:用0补充、用均值填充
剔除异常值
归一化/标准化:
Min-Max Normalization
Z-Score Normalization
Logarithmic Normalization
离散特征预处理:
补充缺失值:用-1补充
剔除异常值:出现频次太低的值
数据编码:
Label-Encoder (95条消息) LabelEncoder 的使用_爱上这个夏天的博客-CSDN博客
Count-Encoder (95条消息) 【Python学习】LabelEncoder、CountEncoder、TargetEncoder、CatBoostEncoder_LaiYoung1022的博客-CSDN博客
其他编码 11种离散型变量编码方式及效果对比 - 知乎 (zhihu.com)
模型验证:
fold out 验证
交叉验证 (用的更多):
KFold 纯随机切分 (大数据)
StratifiedKFold 保证每个fold内标签分布稳定 (小数据)
ShuffleSplit 不保证遍历所有数据
算法
双指针
完成题目:
要复习,用滑动窗口209. 长度最小的子数组 - 力扣(LeetCode)
数学建模
动态规划解决旅行商问题
2023年7月4日
大数据挑战赛
老师分享*2
算法
链表
Struct ListNode{
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};完成题目:
2023年7月5日
算法
DFS
完成题目:
BFS
queue <- 初始化
while q 不空
t <- 队头
扩展t
2023年7月6日
算法
小知识:typedef pair <int, int> PII; x = t.first, y = t.second;
sizeof是关键字,可以不加括号 例如 memset(a, -1, sizeof a);
完成题目:
图的建立
const int N = 1e5 + 10, M = 2 * N;
int h[N], e[M], ne[M], idx;
void add(a, b){
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
int main(){
memset(h, -1, sizeof h); // 邻接表 n个头结点都指向-1
}2023年7月7日
数学建模
完成Lotka-Volterra 猎食者-猎物模型
学习scipy.integrate
算法
dfs
void dfs(u){
st[u] = true;
for (int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
if (!st[j]) dfs(j);
}
}完成题目:
2023年7月8日
跟导师探讨用Caputo derivative的反向传播
数学建模
学习离散递推模型
pandas进行数据预处理:使用 pandas 进行数据预处理_使用pandas进行数据预处理_西门催学不吹雪的博客-CSDN博客
2023年7月9日
数学建模
完成Give me some credit竞赛并撰写论文大纲
2023年7月10日
审稿*1 帮老师改代码*1
AI竞赛
深度之眼课程14-
数据收集与清洗->特征提取->特征选择->模型调参训练->模型评估
特征工程:连续特征、连续特征、历史行为特征
连续型特征:
特征对的处理:特征之间的二元数学运算。
单个特征的处理:标准化、归一化、其他数学变换(log)、离散化(等频、等距)
离散化:特征离散化(分箱)综述 - 知乎 (zhihu.com) 机器学习中的特征工程(四)---- 特征离散化处理方法 - 简书 (jianshu.com)
离散型特征:
特征对的处理:特征交叉、Group特征
单个特征的处理:Label Encoding、One-Hot Encoding、Target Encoding、Count Encoding
特征交叉: 统计贡献次数、偏好比例(很重要)
Group特征:输入对象是key,value;通过对key进行groupby,然后每个group进行相应的统计操作,得到key特征对于value的统计结果;value可以是离散的也可以是连续的。
例如:统计用户购买商品的类目(电子、美食)
算法
BFS
int bfs(){
memset(d, -1, sizeof d);
q.push(1);
d[1] = 0;
while (!q.empty()){
int x = q.front();
q.pop();
for (int i = h[x]; i != -1; i = ne[i]){
int y = e[i];
if (d[y] == -1){
d[y] = d[x] + 1;
q.push(y);
}
}
}
return d[n];完成题目:AcWing 847. 图中点的层次 - AcWing
2023年7月11日
算法
拓扑序列
queue<-所有入读为0的结点入队
while q非空
t <- 对头
枚举t的所有出边j
删掉t->j ,j的入度减一
if j入读为0 j入队
写的题解:AcWing 848. 有向图的拓扑序列STL.queue+y总方法存图 - AcWing
(想摆烂了不想学数学建模了呜呜 作业好多啊)
2023年7月14日
审稿*1
数学建模
完成22c题第一问
2023年7月15日
练了一天车
2023年7月16日
数学建模
完成2022国赛C题
算法
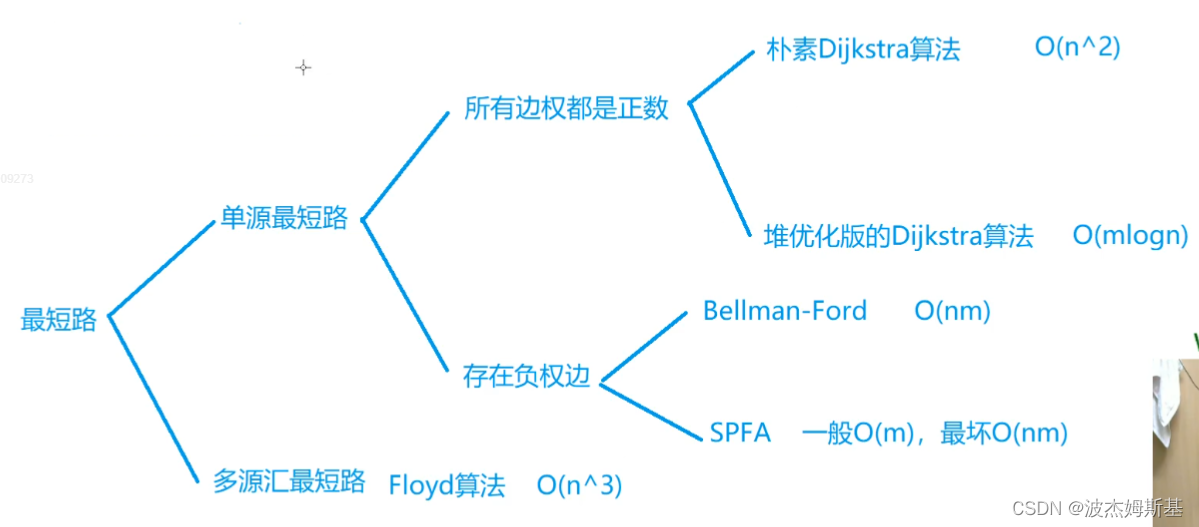
朴素dijkstra
s: 所有当前已确定最短距离点
①dis[1]=0, dis[else]=inf
②for i :0 ~ n
t <- 不在s中的最短距离点
s <- t
用t更新其他所有点的距离
稠密图用邻接矩阵存。
最短路中自环可以删除,重边可以删除长的。
2023年7月19日
审稿*1
数学建模
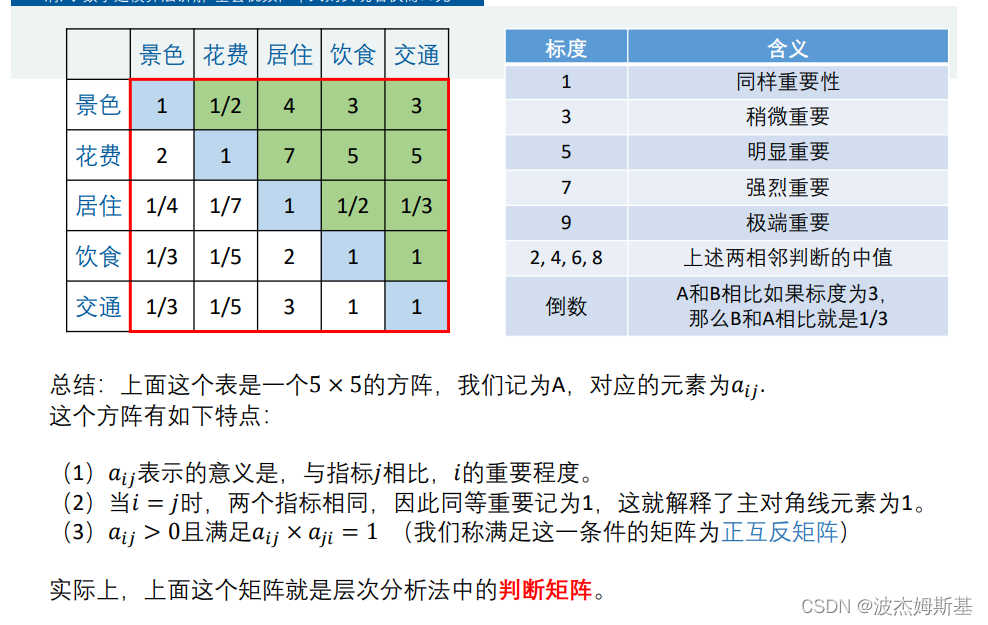
层次分析法
从论文中寻找评价指标
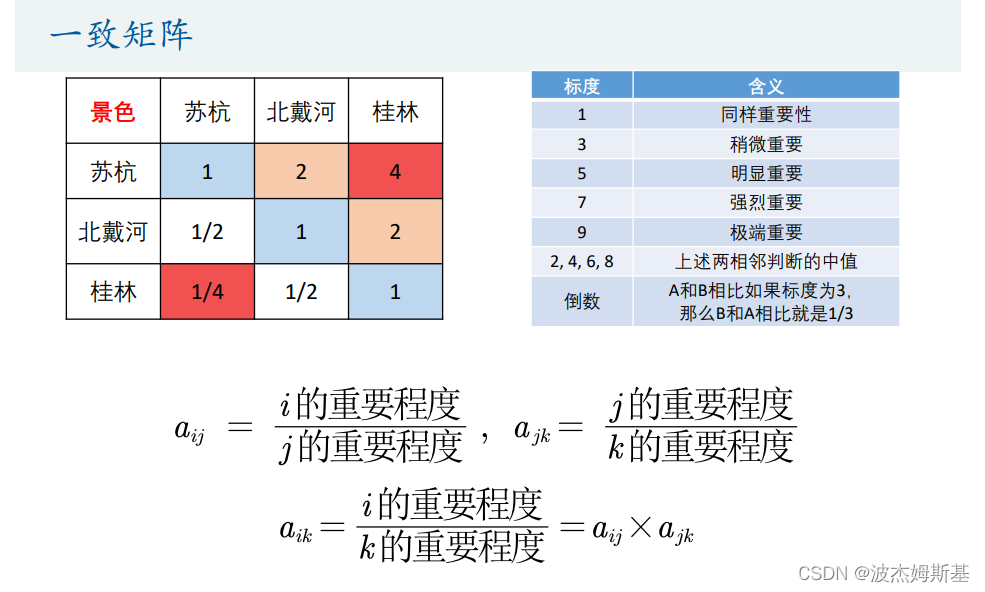
一致矩阵中 各行(各列)之间成倍数关系

对自己构造的判断矩阵,要一致性检验。
权重要按列进行归一化处理。判断矩阵(不是一致矩阵),可以用算术平均法/几何平均法/特征值法求权重。
Python代码:Mathematical-Modeling/层次分析法/层次分析法代码.ipynb at master · Lanrzip/Mathematical-Modeling (github.com)
2023年7月20日~2023年8月13日
摆烂
考完科三科四 拿了驾照
去武汉转了一圈(草东!!
2023年8月14日
复习链表















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









