







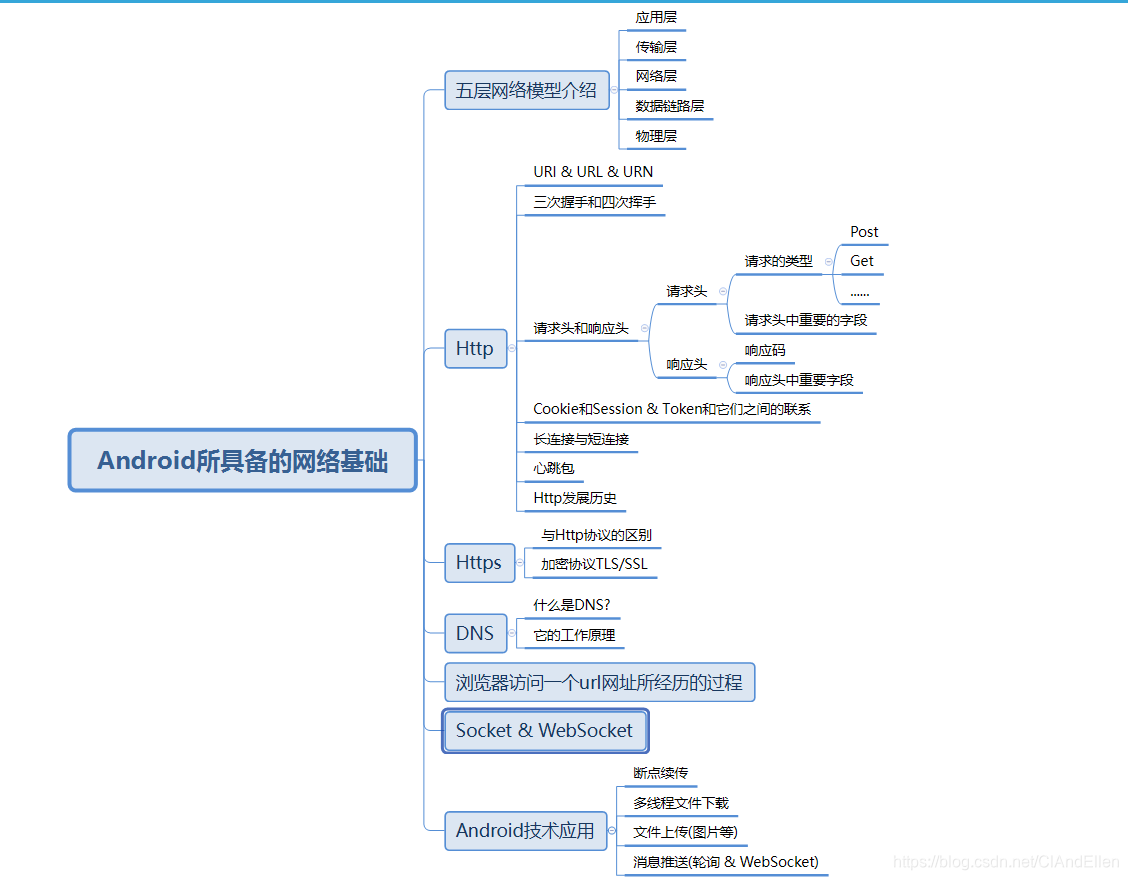
1.五层网络模型介绍
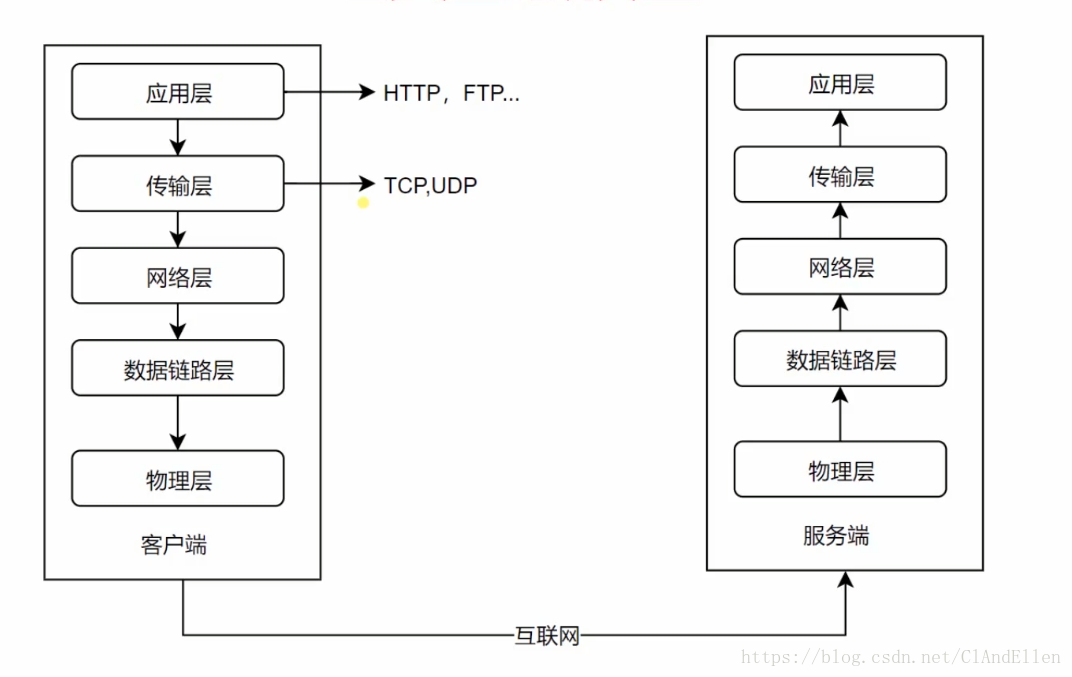
由于这是针对Android开发者的网络基础文章,而计算机网络知识体系十分复杂繁多,所以笔者这里只作浅层的介绍,对Android开发无帮助的网络知识,笔者这里就不废话连篇了,读者如果想深入研究,笔者倒是可以推荐一些书籍,在文章末尾位置。对于上图的五层网络模型,我们只需要对应用层和传输层研究的细致些,而下面三层,了解即可。下面来对这五层作一一介绍:
- 物理层:主要作用是定义物理设备之间如何传输数据。
- 数据链路层:在通信的实体之间建立数据链路连接。
- 网络层为数据在结点之间传输创建逻辑链路。
- 传输层:向用户提供端到端(End-to-End)的服务,传输层向高层屏蔽了下层数据通信的细节,作为Android开发者,需要对这一层的TCP/IP,UDP协议非常了解。
- 应用层:为应用软件提供了很多服务,构建于TCP协议之上,屏蔽网络的传输相关细节。这一层需要了解Http,Ftp等协议。
2.Http协议
2.1 三次握手与四次挥手
2.1.1 Tcp三次握手
什么是三次握手?它主要作用是干什么,为什么是三次握手呢?我们先来看看Tcp三次握手的过程:

- 第一次握手:客户端发送syn包(seq=x)到服务器,并进入SYN_SEND状态,等待服务器确认;
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(seq=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
Tcp三次握手的主要目的:
首先,tcp是可靠传输协议,需要三次握手建立连接服务。
三次握手的目的是“为了防止已经失效的连接请求报文段突然又传到服务端,因而产生错误”,这种情况是:client端发出了一个连接请求报文,而是因为某些未知的原因在某个网络节点上发生延迟、滞留,导致延迟到连接释放以后的某个时间才到达server端。本来这是一个早已失效的报文段,但是server收到此失效的报文之后,会误认为是client再次发出的一个新的连接请求,于是server端就向client又发出确认报文,表示同意建立连接。如果不采用“三次握手”,那么只要server端发出确认报文就会认为新的连接已经建立了,但是client端此时并没有发出建立连接的请求,因此不会去向server端发送数据,server端没有收到数据就会一直等待,产生死锁现象,这样server端就会白白浪费掉很多资源。如果采用“三次握手”的话就不会出现这种情况,client端首先发出连接请求并进入等待状态,server接收连接请求后同意建立连接,并向client返回报文段表示已经建立连接server进入SYN_RECV状态,client接收到server发出的确认信息后自己再发出确认信息,然后就可以建立直接通信。所以说只有三次握手在逻辑上才是最合适的,可以保障可靠性。
三次握手的最主要目的是保证连接是双工的,可靠更多的是通过重传机制来保证的。
2.1.2 Tcp四次挥手
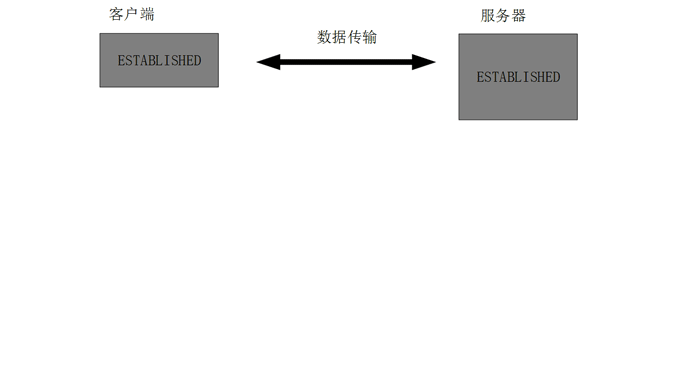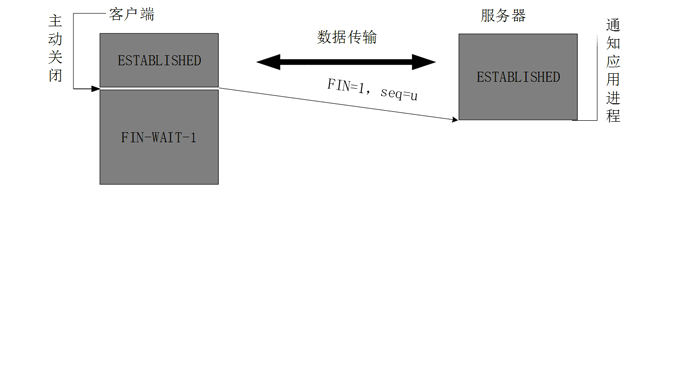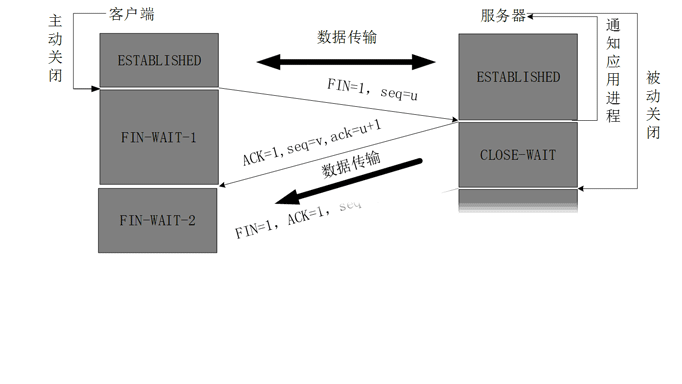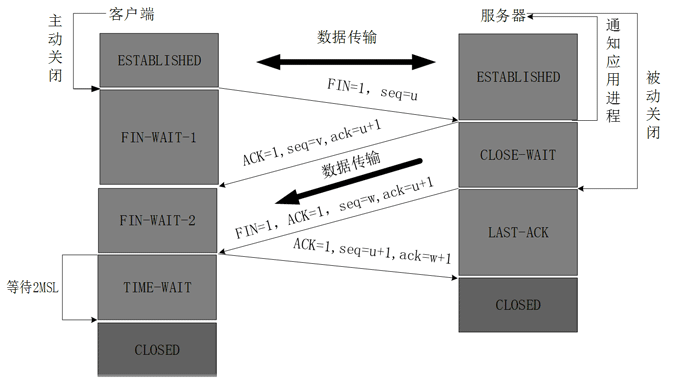
当客户端没有数据再需要发送给服务端时,就需要释放客户端的连接,这整个过程为:
- 1.客户端发送一个报文给服务端(没有数据),其中FIN设置为1,Sequence Number置为u,客户端进入FIN_WAIT_1状态
- 2.服务端收到来自客户端的请求,发送一个ACK给客户端,Acknowledge置为u+1,同时发送Sequence Number为v,服务端年进入CLOSE_WAIT状态
- 3.服务端发送一个FIN给客户端,ACK置为1,Sequence置为w,Acknowledge置为u+1,用来关闭服务端到客户端的数据传送,服务端进入LAST_ACK状态
- 4.客户端收到FIN后,进入TIME_WAIT状态,接着发送一个ACK给服务端,Acknowledge置为w+1,Sequence Number置为u+1,最后客户端和服务端都进入CLOSED状态
也许你会问我:为什么TCP连接的建立只需要三次握手而TCP连接的释放需要四次握手呢:
因为服务端在LISTEN状态下,收到建立请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而连接关闭时,当收到对方的FIN报文时,仅仅表示对方没有需要发送的数据了,但是还能接收数据,己方未必数据已经全部发送给对方了,所以己方可以立即关闭,也可以将应该发送的数据全部发送完毕后再发送FIN报文给客户端来表示同意现在关闭连接。
从这个角度而言,服务端的ACK和FIN一般都会分开发送。
2.2 请求头和响应头
2.2.1 请求头
什么是请求头?http请求头,HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。
注意:面试官会问你请求类型仅仅有Get和Post吗?显示Http请求不止这两种:
HTTP协议中共定义了八种方法或者叫“动作”来表明对Request-URI指定的资源的不同操作方式
- OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*'的请求来测试服务器的功能性。
- HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET:向特定的资源发出请求。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除Request-URI所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
虽然HTTP的请求方式有8种,但是我们在实际应用中常用的也就是get和post,其他请求方式也都可以通过这两种方式间接的来实现。面试官接着会问你Get和Post有什么区别?
Get和Post的区别如下:
a.提交数据方面的区别:
get提交的数据一般放在url之后,用"?"来分隔开来,post是通过HTTP post机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。
因为get设计成传输小数据,而且最好是不修改服务器的数据,所以浏览器一般都在地址栏里面可以看到,但post一般都用来传递大数据,或比较隐私的数据,所以在地址栏看不到,能不能看到不是协议规定,是浏览器规定的。
b.提交的数据大小是否有限制:
get是有大小限制的,而post是没有大小限制。get传送的数据量较小,不能大于2KB。post传送的数据量较大,一般被默认为不受限制。但理论上,IIS4中最大量为80KB,IIS5中为100KB。
post基本没有限制,我想大家都上传过文件,都是用post方式的。只不过要修改form里面的那个type参数
c.取得变量的值:
对于get方式,服务器端用Request.QueryString获取变量的值,对于post方式,服务器端用Request.Form获取提交的数据。
d.安全性:
get安全性非常低,post安全性较高。
如果没有加密,他们安全级别都是一样的,随便一个监听器都可以把所有的数据监听到。
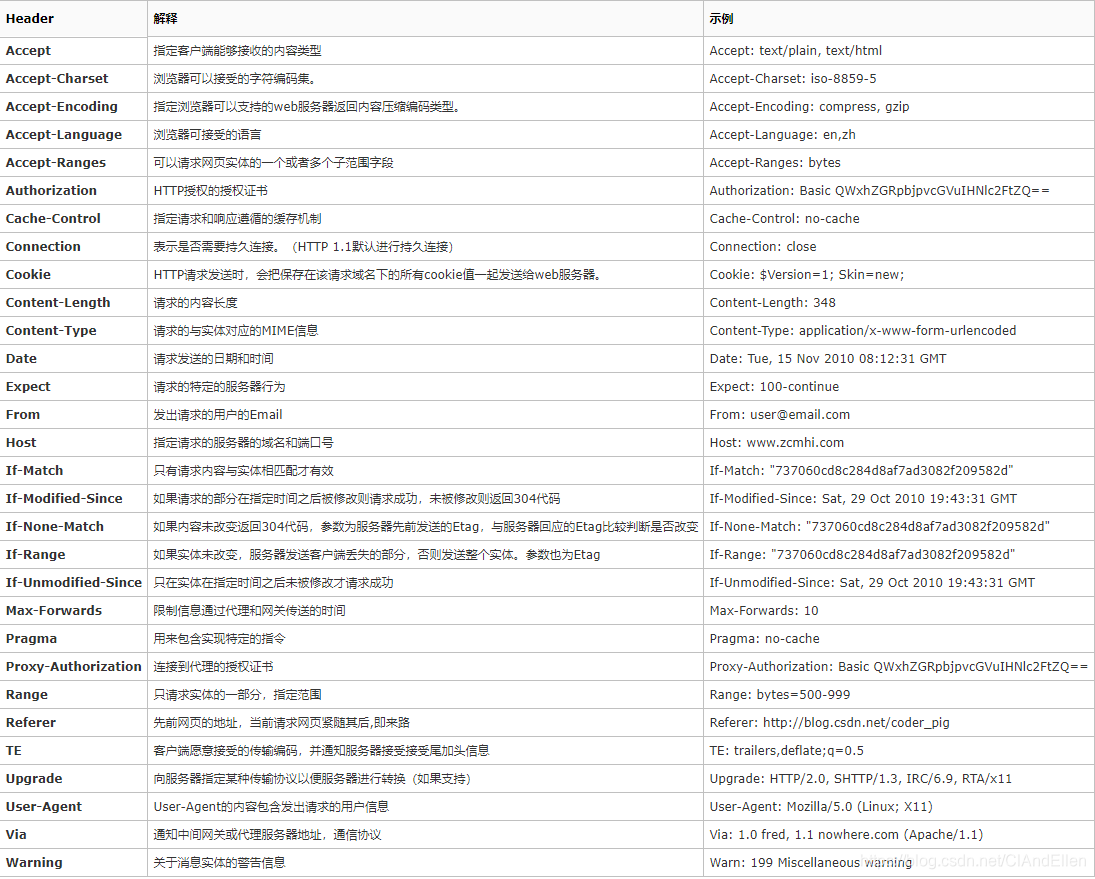
以上扯完了Http请求的类型以及Get和Post的区别,接下来,我们来看看请求头中比较重要的头字段信息:
2.2.2 响应头
什么是响应头?既然有请求,那么肯定有响应对不对,在http请求成功时,响应头中是存在一个叫响应码的东,它也叫状态码,它是用来标记请求的结果状态,比如:200代表请求成功,做过网络开发的你对这个状态码很熟悉吧!由于状态码比较多,所以笔者也就不在这里一一例举了,面试的时候把常见的一些说出来就行了,200,404等等。点击查阅所有状态码
接下来我们来看看响应头中字段信息:
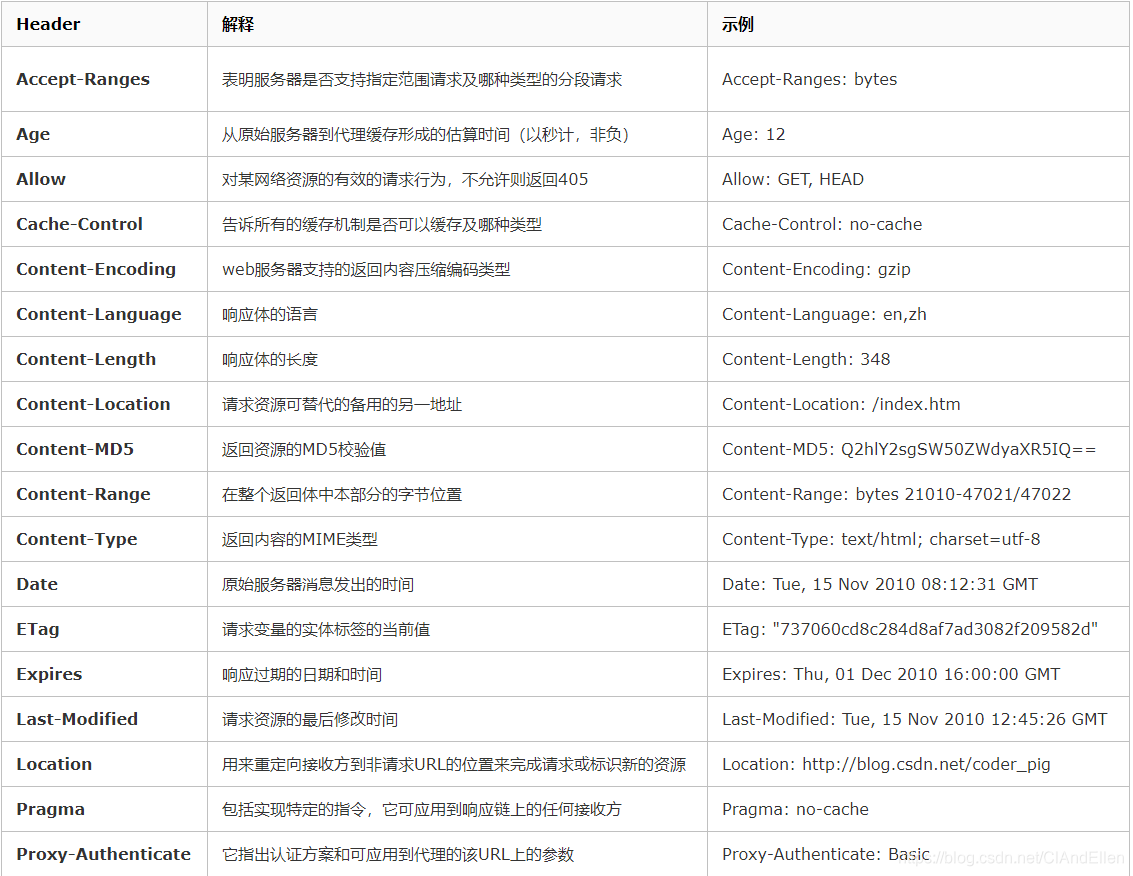
非常注意:
1.如何保存Token呢?比如二次登陆,又或者其它接口需要这个Token才能去访问,那么我们可能需要使用set-cookie字段,以下是set-cookie中参数的含义。在之后讲解Cookie和Session的时候具体会讲解二者和Token之间的联系。

2.3 Cookie和Session
2.3.1 什么是Cookie?
Cookie意为“甜饼”,是由W3C组织提出,最早由Netscape社区发展的一种机制。目前Cookie已经成为标准,所有的主流浏览器如IE、Netscape、Firefox、Opera等都支持Cookie。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。
2.3.2 什么是Session?
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种方式记录在服务器上。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。它的工作流程如下:
(1)第一步当然是创建Session啦
(2)在创建Session的同时,服务器会为Session生成一个唯一的Session Id。
(3)在Session创建完成后,就可以调用Session的相关方法往Session中增加内容。
(4)当客户端再次发送请求的时候,会将这个Session Id带上,服务器接收到这个请求之后就会依据Session Id找到对应的Session来确认客户端的身份。
2.3.3 Cookie和Session的区别
a.存放的位置不同:
Cookie保存在客户端,而Session保存在服务端。简单的说,当你登录一个网站的时候,如果web服务器端使用的是session,那么所有的数据都保存在服务器上面,客户端每次请求服务器的时候会发送 当前会话的session_id,服务器根据当前session_id判断相应的用户数据标志,以确定用户是否登录,或具有某种权限。由于数据是存储在服务器 上面,所以你不能伪造,但是如果你能够获取某个登录用户的session_id,用特殊的浏览器伪造该用户的请求也是能够成功的。session_id是服务 器和客户端链接时候随机分配的,一般来说是不会有重复,但如果有大量的并发请求,也不是没有重复的可能性,我曾经就遇到过一次。登录某个网站,开始显示的 是自己的信息,等一段时间超时了,一刷新,居然显示了别人的信息。
b.存取的方式不同:
Cookie中只能保存ASCII字符串,Session中可以保存任意类型的数据,甚至Java Bean乃至任何Java类、对象等。
c.安全性的不同:
Cookie存储在客户端,对客户端是可见的,可被客户端窥探、复制、修改。而Session存储在服务器上,不存在敏感信息泄露的风险
d.有效期上的不同:
Cookie的过期时间可以被设置很长。Session依赖于名为JSESSIONI的Cookie,其过期时间默认为-1,只要关闭了浏览器窗口,该Session就会过期,因此Session不能完成信息永久有效。如果Session的超时时间过长,服务器累计的Session就会越多,越容易导致内存溢出。
e.对服务器造成的压力不同:
每个用户都会产生一个session,如果并发访问的用户过多,就会产生非常多的session,耗费大量的内存。因此,诸如Google、Baidu这样的网站,不太可能运用Session来追踪客户会话。
f.浏览器支持不同:
Cookie运行在浏览器端,若浏览器不支持Cookie,需要运用Session和URL地址重写。
g.跨域支持不同:
Cookie支持跨域访问(设置domain属性实现跨子域),Session不支持跨域访问
2.3.4 Token和 Cookie & Session的联系
2.4 长连接和短连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
2.5 心跳包
2.6 Http发展历史
https://www.cnblogs.com/zhangyfr/p/8662673.html
3.Https
什么是Https?Https并不是一个单独的协议,而是对工作在一加密连接(SSL/TLS)上的常规Http协议,通过TCP和Http之间加入TLS(Transport Layer Security)来加密保证数据的安全。
3.1 Https和Http区别
HTTP+ 加密 + 认证 + 完整性保护 = HTTPS
3.2 SSL/TLS协议
4.DNS
4.1 什么是DNS?
它所提供的服务是用来将主机名和域名转换为IP地址的工作。
当然现在已经是IPV6了。图比较老了,理解它的原理,此图就凑合凑合吧!
4.2 DNS查询过程
递归:DNS服务器可使用其自身的资源记录信息缓存来应答查询,也可代表请求客户机来查询或联系其他DNS服务器,以完全解析该名称,并随后将应答返回至客户机。
迭代:客户机自己也可尝试联系其他的DNS服务器来解析名称。如果客户机这么做,它会使用基于服务器应答的独立和附加的查询。
步骤如下:
a.在浏览器中输入域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系。
b.如果hosts里没有这个域名的映射,则查询本地DNS解析器缓存。
c.如果hosts与本地DNS服务器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器。
d.如果要查询的域名,不是由本地DNS服务器区域解析,但是该DNS服务器已经缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析。
e.本地DNS就把请求发送到13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到这个IP信息后,将会练习负责.com域的这台服务器。
f.如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析。
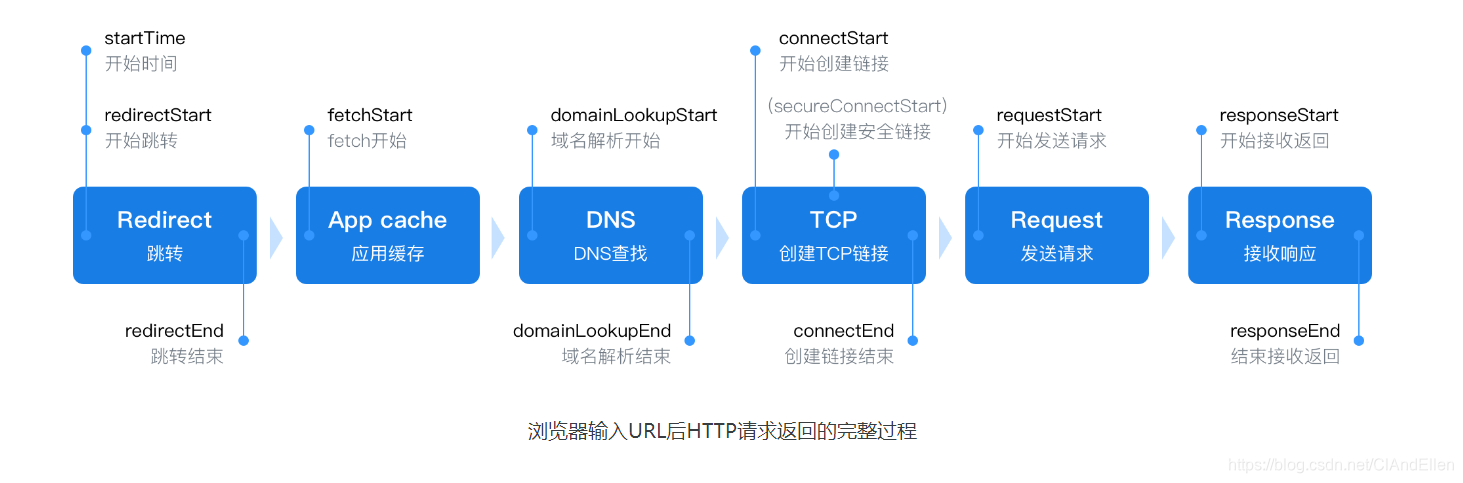
5.浏览器访问一个url所经历的过程














 5910
5910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









