








0.论文摘要
本文提出了对于对抗样本存在原因的新解释——神经网络的线性特性,并提出了快速有效生成对抗样本的方法以及基于对抗的模型训练方式。
1.对抗样本的线性解释
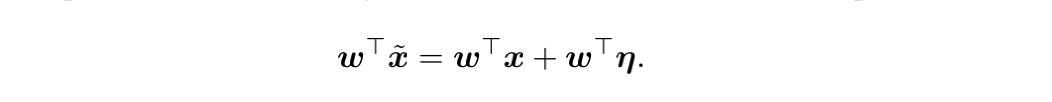
考虑如上公式,其中 代表一个生成的对抗样本,
代表权重参数,
代表在正常样本
基础上添加的扰动,其中扰动向量中每一元素的数值绝对值大小都不超过
。
当我们取 ,对计算结果造成的最大影响大小为
,其中
表示向量的维数。所以当
足够大时,即使扰动的最大范数很小,还是可以对总体结果产生较大影响。
2.神经网络的一种对抗样本生成算法——FGSM

扰动关键公式如下:
![]()
对这个公式的理解与之前类似,就是将扰动的向量方向设置为和损失函数梯度方向一致,使得扰动造成的影响更大
使用此算法产生对抗样本进行实验,结果:
当 ,浅层softmax分类模型在MNIST上错误率为 99.9%,对应平均置信度为 79.3%
同样的设定,maxout网络在MNIST对抗样本上错误率为 89.4%,对应平均置信度为 97.6%
当,卷积maxout网络在CIFAR-10上错误率为 87.15%,对应平均置信度为 96.6%
所以这些结果也侧面证明了是像之前 1 中所说——神经网络由于过于线性特性而容易受到对抗样本攻击
3.对抗训练以及和权重衰减的对比


其中推导第一个公式前请注意,样本标签 y 为 {1,-1} 时, ,其余步骤与普通逻辑回归推导一致。
然后我们考虑第二个对抗训练所用损失函数公式。其中含有L1正则化项,但是与权重衰减不同的是,此时的L1正则化项是作用在激活函数的自变量上,而不是直接乘以惩罚系数加在损失函数后。所以这一项对模型造成的损失可能会随着训练过程而减小消失,而权重衰减造成的影响直到最后也不会消失但是可能会造成欠拟合现象的加重,因为直接作用在激活函数中模型拟合的难度更大。
另外,权重衰减的系数 的选择比起
的选择更为困难,往往要比
的取值小很多很多,当权重衰减系数过小虽然训练效果更好,但是期望的正则化效果却会达不到。
4.深层网络的对抗训练

通过这种训练方法错误率也达不到 0 , 不过可以采用增大模型参数量、在对抗性验证集上使用early stopping的方式进一步降低错误率。
这种训练方法能够显著降低面对FGSM生成的对抗性样本的错误率,本文表示可以从 89.4% 降到 17.9%
5.关于抵抗性和对抗样本的范化性
RBF网络自然地对于对抗样本有较好的抵抗性,即当它们在对抗样本上产生错误的分类结果时对应的置信度很低。
关于对抗样本的范化性:针对某个模型的对抗样本往往会被其他模型也错误分类,甚至它们对于这个对抗样本的错误分类结果也差不多相同。具体实验结果见下方所示:

由上实验结果我们可知:对抗样本出现在连续的空间内,而不是离散分布的,并且我们观察到了结果概率变化和 之间的某种线性关系。
至于为什么不同模型的错误分类结果都类似,本文给出了一个假设可以概括为:基于当前的学习优化方法,不同模型学习到的模型参数类似,学习到的重要参数的稳定性导致了对抗样本被分类结果的稳定性。















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









