








对抗样本自从2014年被提出来之后,逐渐引发人们的关注,在Ian J. Goodfellow大佬的推动下,对抗样本攻防逐渐成为一个小领域,本文是Ian J. Goodfellow大佬在2015年ICLR上发表的论文,解释了对抗样本的机理以及通过实验论证了他的假设,同时借助该假设提出了一个快速梯度标记算法来产生对抗样本.
文献链接: https://arxiv.org/abs/1412.6572
摘要
对于对抗样本导致的误分类现象,早期解释的关注点在非线性和过拟合上,文章用线性惯性进行解释,并首次给出了定量结果。
文章主要有两方面的工作:
- 对交叉框架和训练集泛化的对抗样本误分类现象给出了线性解释
- 给出了一种快速产生对抗样本的方法
1.INTRODUCTION(引言)
以Szegedy的关于对抗样本的开山之作做引,不同架构的的且在不同数据集上训练完成的模型对于相同的对抗样本都会出现误分类的情况。表明了对抗样本暴露出训练算法中的基本盲点。
当前,一些推测认为对抗样本是由于深度神经网络的极端非线性,使得模型平均值与正则化不足而产生的。但是作者提出这些推测是不必要的,因为他们发现高维空间中的线性行为就可以导致这些对抗样本的出现。由此作者提出了一种快速生成对抗样本的方法(FGSM),大大地增强了对抗样本的实用性的同时提供除了传统正则化方法(dropout, pre-training, model averaging等)外的另外一种"正则化方法"。
作者的实验表明,在设计因线性而易于训练的模型和设计使用非线性效应抵抗对抗性扰动的模型之间存在着根本的矛盾。从长远来看,通过设计更强大的优化方法,可以成功地训练出更多的非线性模型,从而避免这种折衷。
2.RELATED WORK
总结概述了作者之前的人所做的关于对抗样本的一些相关工作。
Szegedy等人在《Intriguing properties of neural networks》中所做的一些相关工作:
- Box-constrained L-BFGS 能够可靠的产生对抗样本
- 在一些数据集上,人眼很难区分对抗样本与原始数据
- 相同的对抗样本能够使得不同架构和在不同训练集上训练的模型出现误分类
- 浅层softmax回归模型对于对抗样本也是脆弱的
- 在对抗样本上训练可以正则化模型——但是在当时条件下,对于这种昂贵的约束优化是不现实的
所以作者这些模型算法就像建了一个Potemkin village,即对于自然数据表现很好,而对于数据分布低概率的会显示出其不好的一面。
作者认为这些缺陷是可修复的,同时也表示,2014年Gu & Rigazio和Chalupka已经开始对于设计抵抗对抗扰动的模型迈出了第一步。
3.THE LINEAR EXPLANATION OF ADVERSARIAL EXAMPLES
此节解释线性模型中的对抗样本
作者提出,因为单个输入的特征信息总是被限制的,例如对于一张数字图片,每个像素是8bit,所以每个像素的信息在1-255之间。因此,当扰动
η
\eta
η比特征信息的精度小的时候,分类器就会对正常输入
x
x
x和对抗性输入
x
~
=
x
+
η
\tilde{x} = x+\eta
x~=x+η产生一样的响应。
为了能确保使分类器对 x x x和 x ~ \tilde{x} x~产生一样的输出,作者提出:
∣ ∣ η ∣ ∣ ∞ < ϵ ||\eta||_{\infty}<\epsilon ∣∣η∣∣∞<ϵ
ϵ \epsilon ϵ足够小,使得模型的传感器或数据存储设备对其丢弃。
在模型正向传播过程,考虑:
w T ⋅ x ~ = w T ⋅ ( x + η ) = w T ⋅ x + w T ⋅ η \begin{aligned} w^T\cdot\tilde{x}&=w^T\cdot(x+\eta)\\ &=w^T\cdot x+w^T\cdot \eta \end{aligned} wT⋅x~=wT⋅(x+η)=wT⋅x+wT⋅η
由此可以看出,对输入
x
x
x,扰动使得激活过程增加了
w
T
η
w^T\eta
wTη。作者提出最大化此增幅通过指定
η
=
s
i
g
n
(
x
)
\eta=sign(x)
η=sign(x),使
η
\eta
η受到最大化范数约束。继续提出,假设
w
w
w是n 维的,且元素平均大小为m,则The activation会增加
ϵ
m
n
\epsilon m n
ϵmn,
因为 ∣ ∣ η ∣ ∣ ∞ < ϵ ||\eta||_{\infty}<\epsilon ∣∣η∣∣∞<ϵ,而 η = s i g n ( x ) \eta=sign(x) η=sign(x)
故使得 w T ≤ ϵ m n w^T\leq\epsilon m n wT≤ϵmn
对于
∣
∣
η
∣
∣
∞
||\eta||_{\infty}
∣∣η∣∣∞是不变的,而对于
w
T
η
w^T\eta
wTη,会随着维度的增加而呈现出线性增加的趋势(因为The activation增加是
ϵ
m
n
\epsilon m n
ϵmn)
所以对抗样本的线性解释表明,对线性模型而言,如果其输入样本有足够大的维度,那么线性模型也容易受到对抗样本的攻击,也解释了为什么softmax回归容易受到对样本的影响
4.LINEAR PERTURBATION OF NON-LINEAR MODELS
对抗样本的线性特性提出了一种其生成的快速方法。
作者假设神经网络是too linear to resist linear adversarial perturbation.。而再看当前已知的一些模型,LSTM、ReLU、maxout等网络都是被设计用线性的方式来运作的,因为线性比较容易优化,而非线性的模型,比如Sigmoid网络,很难优化。然而线性方式,会让模型更容易受到攻击。基于线性的这种特性作者设计出FGSM对抗样本生成方法:
η = ϵ s i g n ( ∇ x J ( θ , x , y ) ) \eta=\epsilon sign(\nabla_x J(\theta,x,y)) η=ϵsign(∇xJ(θ,x,y))
其中
θ
\theta
θ表示模型的参数(parameters);
x
x
x表示模型输入;
y
y
y表示输出目标;
J
(
θ
,
x
,
y
)
J(\theta,x,y)
J(θ,x,y)表示神经网络训练的代价函数;而梯度
∇
\nabla
∇可以通过反向传播有效地计算;故该式表示围绕
θ
\theta
θ的当前值对成本函数
J
J
J进行线性化,得到最大范数约束下的最优扰动。此方法即称为FGSM方法,即快速梯度法。
当然实验表明,此方法生成的对抗样本能够可靠地导致各类模型出现误分类,实验中误分类的置信度都是比较大的。效果如图

作者也提出还有很多其他的简单地生成对抗样本的方法,例如,小角度旋转 x x x的梯度方向。
由此,证明了之前证明了对抗样本的线性解释。这些算法还可以用来加快对抗性训练,甚至只是分析训练过的网络。
5.ADVERSARIAL TRAINING OF LINEAR MODELS VERSUS WEIGHT DECAY
以最简单的回归模型为例,分析FGSM法生成的对抗样本,进一步理解在一个简单环境中如何产生抵抗样本
模型用
P
(
y
=
1
)
=
σ
(
w
T
x
+
b
)
P(y=1)=\sigma(w^Tx+b)
P(y=1)=σ(wTx+b)识别标签
y
∈
{
−
1
,
1
}
y\in \{-1,1\}
y∈{−1,1},其中
σ
(
.
)
\sigma(.)
σ(.)是逻辑sigmoid函数,(该函数输出为
±
1
\pm 1
±1).则使用梯度下降的训练过程可以描述为:
E x , y ∼ p d a t a ζ ( − y ( w T x + b ) ) \mathbb{E}_{x,y\sim p_{data}}\ \ \zeta(-y(w^Tx+b)) Ex,y∼pdata ζ(−y(wTx+b))
其中
ζ
(
z
)
=
l
o
g
(
1
+
e
x
p
(
z
)
)
\zeta(z)=log(1+exp(z))
ζ(z)=log(1+exp(z))表示softplus函数。基于梯度符号扰动,可以推导出一种简单的解析形式,用于训练x的最坏情况下的对抗性扰动,而不是x本身,即得到一个对对抗样本训练的模型。
值得注意的是 对模型而言,梯度的符号是 − s i g n ( w ) -sign(w) −sign(w),而 w T s i g n ( w ) = ∣ ∣ w ∣ ∣ 1 w^T sign(w) = ||w||_1 wTsign(w)=∣∣w∣∣1,所以,对于对抗样本来说,我们要做的就是最小化如下模型:
E x , y ∼ p d a t a ζ ( − y ( w T x ~ + b ) ) = E x , y ∼ p d a t a ζ ( − y ( w T ( x + η ) + b ) ) = E x , y ∼ p d a t a ζ ( − y ( w T η + w T x + b ) ) = E x , y ∼ p d a t a ζ ( − y ( w T ϵ s i g n ( w ) + w T x + b ) ) = E x , y ∼ p d a t a ζ ( y ( ϵ ∣ ∣ w ∣ ∣ 1 − w T x − b ) ) \begin{aligned} \mathbb{E}_{x,y\sim p_{data}}\ \ \zeta(-y(w^T \tilde{x}+b))&=\mathbb{E}_{x,y\sim p_{data}}\ \ \zeta(-y(w^T (x+\eta)+b))\\ &=\mathbb{E}_{x,y\sim p_{data}}\ \ \zeta(-y(w^T \eta +w^T x+b))\\ &=\mathbb{E}_{x,y\sim p_{data}}\ \ \zeta(-y(w^T \epsilon\ sign(w) +w^T x+b))\\ &=\mathbb{E}_{x,y\sim p_{data}}\ \ \zeta(y(\epsilon\ ||w||_1 -w^T x-b))\\ \end{aligned} Ex,y∼pdata ζ(−y(wTx~+b))=Ex,y∼pdata ζ(−y(wT(x+η)+b))=Ex,y∼pdata ζ(−y(wTη+wTx+b))=Ex,y∼pdata ζ(−y(wTϵ sign(w)+wTx+b))=Ex,y∼pdata ζ(y(ϵ ∣∣w∣∣1−wTx−b))
这个公式很像 L 1 L^1 L1正则化后的公式,但又有些不同, L 1 L^1 L1正则化是加上 ϵ ∣ ∣ w ∣ ∣ 1 \epsilon ||w||_1 ϵ∣∣w∣∣1 ,而我们得到的是减去该式子,作者也将该方法称为 L 1 L^1 L1惩罚。但是,当模型的 ζ \zeta ζ饱和(啥意思),模型能够做出足够自信的判断的时候,该方法就会失效,该方法只能够让欠拟合更严重,但不能让一个具有很好边界的模型失效。
将该方法由逻辑回归转移到多分类softmax回归时, L 1 L^1 L1 weight decay 会变得更糟糕,因为它将softmax的每个输出视为独立的扰动,而实际上通常无法找到与类的所有权重向量对齐的单个 η \eta η。在具有多个隐藏单元的深层网络中,该方法高估了扰动可能造成的损害。因为, L 1 L^1 L1 weight decay 高估了一个对抗样本所能造成的危害,所以有必要将 L 1 L^1 L1 weight decay 的系数设置的更小。更小的系数时训练能够更成功,但也让正则化效果不好。作者在MNIST训练集上训练maxout网络使用 ϵ = 0.25 \epsilon = 0.25 ϵ=0.25的系数却获得了很好的结果。但是对模型第一层使用 L 1 L^1 L1 weight decay时,发现0.0025的系数也显得太大了,导致模型在训练集上的误差超过5%。较小的权重衰减系数可以使得训练成功,但无法显示正则化的好处。
6.ADVERSARIAL TRAINING OF DEEP NETWORKS
作者认为相比于浅层网络,深度网络有抵抗对抗样本的能力。广义逼近定理(the universal approximator theorem)认为至少有一层隐藏层的神经网络就能够以任意精度的表示任何函数,只要有足够的单元。而浅层线性模型既不能在训练点附近保持不变(拟合不光滑),同时也不能将不同的输出分配给不同的训练点。
当然,广义逼近定理并没有说明训练算法是否能够发现具有所有期望性质的函数。很明显的,标准的监督学习并没有具体说明,选择的函数能够抵御对抗样本。这必须在训练程序中编码才行。所以作者通过Szegedy等人的说明研究对抗性例子的训练与其他数据增强有些不同;数据增强使用的是不太可能自然发生的输入,但这些输入暴露了模型概念化决策函数方式中的缺陷。然而,这一过程从未被证明可以改善dropout以外的状况。这在一定程度上是因为很难用基于L-BFG的昂贵的对抗样本进行广泛的实验。
作者发现基于FGSM的对抗目标函数训练是一种有效地正则化方式:
J ~ ( θ , x , y ) = α J ( θ , x , y ) + ( 1 + α ) J ( θ , x + ϵ s i g n ( ∇ x J ( θ , x , y ) ) ) . \tilde{J}(\theta,x,y) = \alpha J(\theta,x,y) + (1 + \alpha)J(\theta,x + \epsilon sign(\nabla_x J(\theta,x,y))). J~(θ,x,y)=αJ(θ,x,y)+(1+α)J(θ,x+ϵsign(∇xJ(θ,x,y))).
所有实验中 α = 0.5 \alpha = 0.5 α=0.5,因为模型表现很好,故没有再试用其他参数。此方法会不断更新对抗样本,以使其抵抗当前模型版本,其实就是一直用对抗样本对当前版本模型进行训练,以提高模型对于对抗样本的鲁棒性。maxout网络的训练展示了此方法呢个能够使错误率有0.94%降低到0.84%。
后面作者用该方法进行试验:
1)该模型在某种程度上也可以抵抗对抗样本。对抗样本可在两个模型之间转移,但对抗性训练的模型显示出更高的鲁棒性。原始模型对基于FGSM生成的对抗样本的错误率是89.4%,而对抗模型是17.9%;原始模型产生的对抗样本在对抗模型上错误率是19.6%,新模型生成的对抗样本在原始模型上错误率是40.9%。然而对抗模型误分类对抗样本的置信度是比较高的,平均置信度达到81.4%。对抗模型的权重也随之发生改变,且更加的局部化和可解释。
2)当数据被扰动时,对抗训练过程可以被看作是使最坏情况的错误最小化(即防止被扰动)。对抗训练也可以看作是主动学习的一种形式,其中模型能够请求新的点的标签(通过附近(能够得到附近的点是对抗训练的扰动造成的)的标签复制过来)。
3)通过对最大范数约束内的所有点进行训练,或者对该约束内的很多点进行采样,来对模型进行正则化,使其对小于精度的特征变化不敏感。这相当于在训练过程中以最大范数增加噪声。我们可以将对抗训练看作是在嘈杂的输入中进行样本挖掘,以便仅考虑那些强烈抵抗分类的嘈杂点来更有效地进行训练。
由于符号函数的导数在任何地方都是零或未定义,因此FGSM的对抗目标函数的梯度下降无法使模型预测对手对参数变化的反应。但是基于小旋转或按比例缩放的梯度的对抗样本,则扰动过程本身是可区分的,学习可以将对抗的反应考虑在内。但是,发现此过程的正则化结果几乎没有强大的功能,因为这类对抗样本并不难解决。
扰动输入层或隐藏层或同时扰动两者那种情况更好?
- Sigmoidal network :隐藏层,规则化效果更好
- 具有隐藏单元的激活不受限制的网络:输入层
- Maxout network: 隐藏层的旋转扰动
我们对对抗性训练的观点是: 只有在模型具有学习抵抗对对抗样本的能力时,它才明显有用。仅当应用The universal approximator theorem时,情况才很明显。而且因为神经网络的最后一层是linear sigmoid或linear softmax层,不是最终隐藏层功能的通用逼近器,所以很可能会遇到欠拟合的问题隐藏层,使用隐藏层扰动但不涉及最终隐藏层的扰动进行训练得到最佳结果。
7.DIFFERENT KINDS OF MODEL CAPACITY
此节作者主要描述低容量(Low capacity)模型对于对于对抗样本是免疫的,原因是由于低容量(Low capacity)模型虽然不能够在所有的点上都能够正确的分类,但是它却可以在一些不能理解的点上(扰动点),给予较低的预测置信度。作者以RBF网络为例,对于RBF网络有:
p ( y = 1 ∣ x ) = e x p ( ( x − μ ) T β ( x − μ ) ) p(y=1|x)=exp((x-\mu)^T \beta(x-\mu)) p(y=1∣x)=exp((x−μ)Tβ(x−μ))
此网络仅仅能够预测
μ
\mu
μ附近的正例,但是对其他范围就具有低的预测置信度,这让RBF网络天生就不易受对抗样本的影响,因为,当RBF被攻击时,它具有较低的置信度。一个没有隐藏层的RBF网络,在MNIST数据集上,使用FGSM方法进行攻击,具有55.4%的攻击成功率。但是,它在误分类样本上的平均置信度只有1.2%。而在干净的测试集上的平均置信度有60.6%。
然而,RBF单元对任何有意义的变换也是不变的,因此它不能很好地推广应用。作者继续将线性units和RBFunits相比,分别将其看作是精确-召回折衷曲线上的不同点。线性units通过在某个方向上响应每一个输入来实现高召回率,但由于在不熟悉的情况下响应太强,因此可能具有较低的精度。RBF单元只对空间中的某个特定点做出响应,但这样做会牺牲召回率,从而获得较高的精度。基于这一思想,作者决定探索包含二次单元的各种模型,包括深RBF网络。但是他发现这是一个非常困难的任务模型,当使用SGD进行训练时,模型具有足够的二次抑制以抵抗对抗性扰动,在训练集上获得了较高误差。
8.WHY DO ADVERSARIAL EXAMPLES GENERALIZE?
作者提出一个有趣的现象,一个模型生成的对抗样本常常也会让其他模型产生误分类,即使这些模型基于不同架构和在不同训练集上训练的,同时多个模型误分类的类基本是同一类。而基于极端非线性和过拟合,没法解释这种行为。因为,在这两种观点中,对抗样本很常见,但只发生在特别精确的位置上。
基于线性的观点下,对抗样本发生在一个较宽的子空间。 只要 η \eta η在损失函数的梯度方向上点积, ϵ \epsilon ϵ足够大,一个模型就会出现误分类的现象。跟踪 ϵ \epsilon ϵ,发现对抗样本出现在由快速梯度符号法定义的一维子空间的相邻区域,而不是在精细的区域。如图
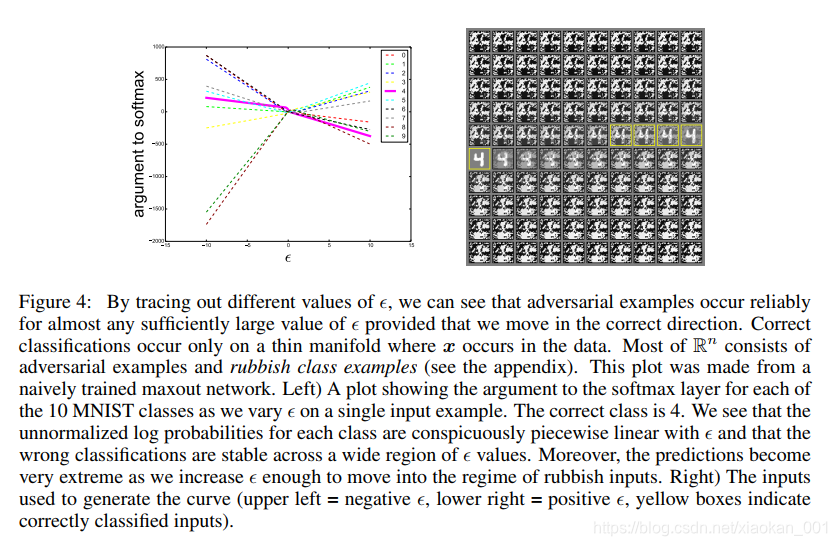
为了解释,多个分类器会将对抗样本分类成相同的类,他们假设目前方法所训练的神经网络看起来都像是在同一个训练集上训练出来一样。在训练集的不同子集上训练时,这些分类器能够学习到近似相同的分类权值。而这是因为机器学习的泛化能力。而根本的分类权值的稳定性又能反过来影响对抗样本的稳定性。
为了测试这一假设,作者又进行了如下的实验。作者在一个maxout网络上生成了对抗样本,然后用一个浅的softmax网络和RBF网络去分类这些样本。这里作者讨论了这两个浅的网络对 那些被maxout网络分类错误的对抗样本 进行分类所花费的时间。然后作者通过实验发现RBF花费的去适配这些分类错误时间更少,是因为RBF是线性的,也就是说,线性的模型更容易被迁移的攻击,也就是说,线性造成了模型之间的泛化。
9.ALTERNATIVE HYPOTHESES
在这一节,作者主要介绍和反驳对抗样本存在性的一些其他假设 。
- 第一个要说的假设是,生成训练可以在训练过程中提供更多的约束条件,或者使模型学习如何区分“真实”和“虚假”数据,并且只对“真实”数据有高的置信度。文章表明,某些生成训练并不能达到假设的效果,但是不否认可能有其他形式的生成模型可以抵御攻击,但是确定的是生成训练的本身并不足够。
- 另一个假设是,相比于平均多个模型,单个模型更能够抵御对抗样本的攻击。作者做了实验证明了这个假设。作者在MNIST训练集上训练了12个maxout模型进行集成,每一个都使用不同的随机数种子来初始化权重,使用了dropout,minibatch的梯度下降,在对抗样本攻击的时候,具有91.1%的攻击成功率。但是当我们使用对抗样本攻击集成模型中的一个模型的时候,攻击成功率下降到了87.9%。
10 SUMMARY AND DISCUSSION
显然,此节是总结和讨论部分:
总结
- 对抗样本被解释为高维点积的一种性质。此为模型是
too linear,而不是too nonlinear。 - 对抗样本的泛化(在不同模型之间)可以解释为:对抗性扰动与模型的权重向量高度一致,不同模型在训练执行相同任务时学习相似的函数
- 对抗样本生成最重要的是扰动的方向,而不是空间中的特定的点。对抗样本在空间内,并不是像实数空间中的有理数那样平铺的。
- 因为最重要的是扰动的方向,所以对抗扰动也可以在不同的训练集上进行泛化
- 介绍了一组可以快速生成对抗样本的方法(FGSM)
- 证明了对抗训练可以用来正则化,甚至效果比dropout还要好
- 容易优化的模型也容易被扰动
- 控制实验,但没有用更简单但效率更低的正则化器重现这种效果,包括L1权重衰减和添加噪声。
- 线性模型缺乏抵抗对抗性扰动的能力;只有具有隐藏层的结构(在普遍近似定理适用的情况下)才应该被训练来抵抗对抗性扰动。
- RBF网络可以抵御对抗样本
- 训练来模拟输入分布的模型不能够抵御对抗样本
- 集成策略不能够抵御对抗样本
- 对抗样本的分布特征,即对抗样本往往存在于模型决策边界的附近,在线性搜索范围内,模型的正常分类区域和被对抗样本攻击的区域都仅占分布范围的较小一部分,剩余部分为垃圾类别(rubbish class)
- 垃圾类别样本是普遍存在的且很容易生成
- 浅的线性模型不能抵御垃圾类别样本
- RBF网络可以抵御垃圾类别样本
讨论
基于梯度的优化方式是现代AI的核心。作者说使用一个设计成足够线性的网络——无论是ReLU或maxout网络、LSTM,还是经过精心配置以避免过多饱和的sigmoid网络——我们能够解决我们关心的大多数问题,至少在训练集上是这样。对抗样本的存在表明,能够解释训练数据,甚至能够正确标记测试数据并不意味着我们的模型真正理解我们要求他们执行的任务。相反,他们的线性反应在数据分布中没有出现的点上过于自信,而这些自信的预测往往是非常错误的。这项工作表明,我们可以通过明确地识别问题点并在每个问题点上修正模型来部分地纠正这个问题。然而,我们也可以得出这样的结论:我们使用的模型族在本质上是有缺陷的。优化的容易程度是以容易被误导的模型为代价的。这推动了优化程序的发展,这些程序能够训练行为更局部稳定的模型
代码链接: FGSM代码实现
参考
[1] BaiDing’s blog
[2] 图片均来自原论文截图

















 4759
4759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









