






现代操作系统是最复杂的计算机程序之一,但在其开发的过程中不可避免地会引入错误或漏洞。并且由于操作系统的广泛应用和重要地位,这些漏洞可能带来严重的威胁并导致损失。因此,挖掘操作系统中隐藏的错误和漏洞对提高系统的整体安全性具有重要意义。模糊测试是目前最流行、最有效的软件测试技术之一,被广泛用于各个主流软件的测试,其中也包括操作系统内核的测试。
但是,目前的内核模糊测试工具在生成和变异测试用例时,没能充分考虑系统调用之间的关系。本文的作者提出了一种动静态相结合的关系学习算法,捕捉系统调用之间的依赖关系,并通过捕捉到的依赖关系来指导生成更有效的测试用例。作者搭建了基于上述算法的模糊测试工具HEALER,并对其进行了实验。实验结果表明,与目前主流的内核模糊测试工具Syzkaller和Moonshine相比,Healer平均提升28%与21%的分支覆盖率,并且效率提升了2.2倍与1.8倍。实验中,Healer在Linux内核中发现了218个漏洞,其中有33个首次发现的漏洞。
一、研究背景
操作系统内核的测试用例其实就是系统调用的序列。Syzkaller并不是完全没有考虑系统调用之间的影响,它利用一张系统调用选择表来记录一个系统调用在另一个系统调用之前被调用的概率,以确定要测试的系统调用的顺序。虽然这个表体现了系统调用之间的资源依赖关系,但选择表并不能显示出系统调用之间的影响关系。而且,系统调用的组合的空间巨大,并且其中大多数组合是无效的或是与别的组合等价,需要采取有效的方法来减少搜索空间并增加生成有效测试用例的概率。
为此,作者提出了新的内核模糊测试工具Healer。Healer通过关系学习算法来处理测试用例,推断用例中的系统调用之间是否存在影响关系,然后将学习到的关系存储在关系表中。关系表会在模糊测试的过程中被逐步细化,用于指导测试用例的生成和变异,最终使得测试用例中的每个系统调用都能够深入到内核的深层逻辑。
二、Healer的结构设计
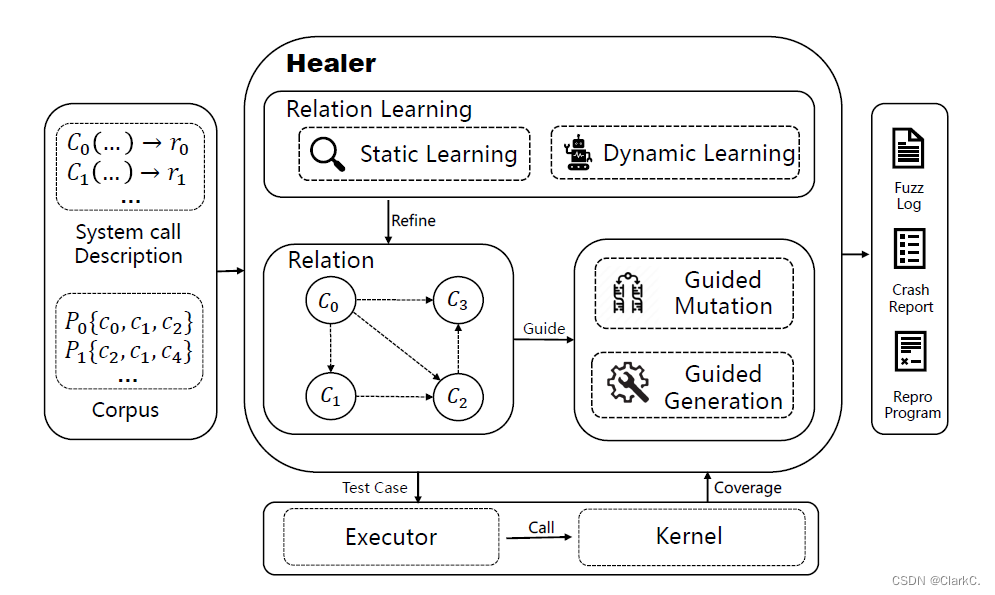
上图展示了Healer的主要组件和整体工作流程。Healer借用了Syzkaller的系统调用格式Syzlang来描述被测内核的系统调用信息,比如参数的输入结构和部分语义。Healer可以基于给定的信息来生成满足结构和部分语义约束的系统调用序列,同时为每个特定类型使用不同的变异算子。输入语料库是一组高质量的测试用例,由模糊测试过程中积累的调用序列组成。用户可以自定义初始语料库以提高效率。系统调用描述包含现有的系统调用信息。关系学习模块对最小化的测试用例进行分析,并在模糊测试过程中对关系表进一步细化。同时,引导式生成和变异模块根据学习到的关系生成系统调用序列。
Healer的输入是一系列系统调用描述符和种子集。种子集是非必须的,如果没有,HEALER会通过随机组合系统调用来构造初始语料集。
Healer启动后,对于给定的种子,首先进行静态学习获得系统调用间相关关系,并记录到关系表中。然后基于关系表生成新种子或将已有的种子进行变异来得到测试用例。随后将测试用例交由内核执行并记录序列中各个系统调用的覆盖率。基于覆盖率进行动态学习获得系统调用的相关关系,并更新关系表。Healer将上述步骤循环执行,并保存测试过程中crash的相关信息。
三、Healer的关系学习过程
Healer的核心就是其关系学习算法。在本文中,系统调用之间的影响关系定义如下:如果系统调用Ci的执行可以通过修改内核的内部状态来影响的系统调用Cj的执行路径,则称Ci对Cj有影响。
Healer的关系学习算法分为两类,即静态学习与动态学习。
1. 静态学习
静态学习是为了捕捉系统调用间显式的相关关系,例如一个系统调用的返回值可以作为另一个系统调用的参数。如果两个系统调用Ci和Cj满足以下规则,则将其标记为相关:
(1)Ci的返回值为资源类型r0或者Ci中的参数是该资源类型的数据流流向向外的指针
(2)Cj中至少一个参数是资源类型r0;或是具有向内的数据流方向且兼容r0的资源类型r1。
2. 动态学习
动态学习是为了捕捉系统调用间隐式的相关关系。动态学习可以使用syzlang无法表达的信息来更好地更新和细化关系表。
基于这些关系学习过程,Healer将系统调用间的相关关系整理成一张关系表。接下来就利用学习到的关系表来生成高质量的测试用例,并指导种子的变异。
四、Healer的实验
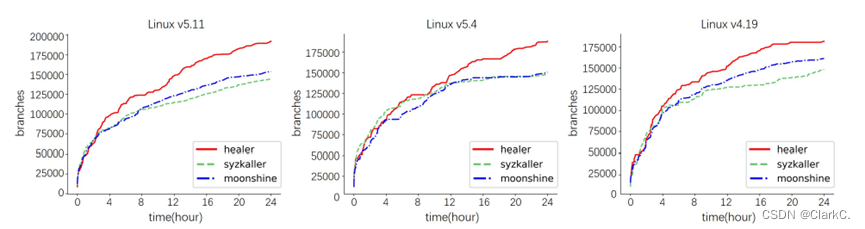
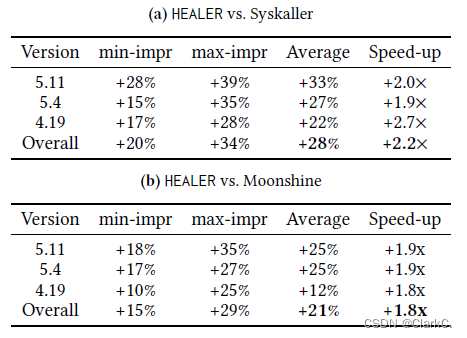
作者选用Linux 5.11、5.4和4.19作为测试对象,在一台16核32G内存的服务器上进行实验。与HEALER进行对比的是其他内核模糊测试工具Syzkaller、Moonshine,其中HEALER和Syzkaller都没有加入初始种子集。每次实验进行24小时的测试,并重复十次,取平均值作为结果。
分支覆盖情况:
性能表现:
除此之外,作者还针对关系学习的有效性进行了实验,将完整的Healer与不用学习到的关系表来指导用例生成和变异的Healer-进行了对比:

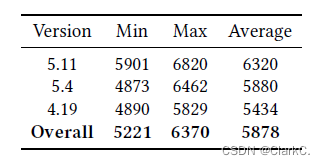
作者还在文中展示了Healer所学习到的关系数量:
论文中还将Healer学到的关系可视化。因为长时间学习后的关系表太过复杂,下图中只展示了前3小时的结果。观察可视化的过程可以发现,关系学习的过程就是系统调用间的依赖关系逐渐明确的过程。
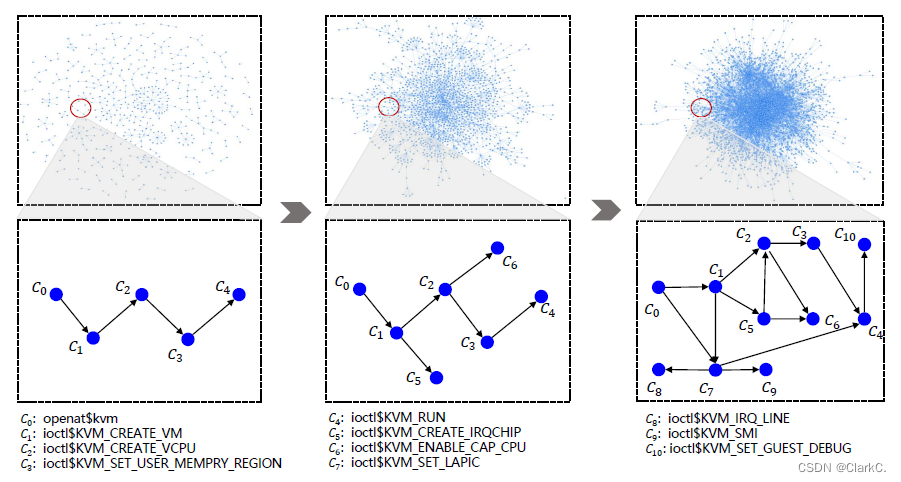
最后一步就是检验Healer发现真实漏洞的能力。作者在三个内核版本上选取了35个已知bug作为测试用例,用3个工具分别进行测试。Syzkaller和Moonshine分别发现了其中17、20个bug,而Healer发现了32个。并且由Healer找出而被其他工具忽略的bug所对应的测试用例更复杂、序列更长,这进一步证实了Healer的有效性。
五、总结
Healer采用了动静态结合的方法来学习系统调用间的关系,为操作系统内核的模糊测试生成和变异出高效且实用的测试用例。使用Healer能够帮助开发人员更高效更全面地找出内核中的bug。Healer的成功体现了系统调用之间的关系在生成和变异高质量测试用例时起着重要作用。
此外,论文中的实验设计思路非常直观,第一个实验展示了相对于已有工具性能的提升,第二个实验验证了关系学习方法的有效性,第三个实验突出了其真实漏洞的挖掘能力。
参考资料:

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









