








本文字数:8563;估计阅读时间:22 分钟
作者:ClickHouse Team
本文在公众号【ClickHouseInc】首发

时间!又一个月过去了,这意味着又到了发布新版本的时间!
发布概要
本次ClickHouse 24.7 版本包含了18个新功能🎁、12项性能优化🛷、76个bug修复🐛
新贡献者
一如既往,我们特别欢迎所有在 24.7 版本中的新贡献者!ClickHouse 的广受欢迎,很大程度上归功于社区的积极贡献。看到社区不断壮大,总是让人感到谦虚。
以下是新贡献者的名单:
0x01f, AntiTopQuark, Daniel Anugerah, Elena Torró Martínez, Filipp Bakanov, Gosha Letov, Guspan Tanadi, Haydn, Kevin Song, Linh Giang, Maksim Galkin, Max K., Nathan Clevenger, Rodolphe Dugé de Bernonville, Tobias Florek, Yinzuo Jiang, Your Name, Zawa-II, cw5121, gabrielmcg44, gun9nir, jiaosenvip, jwoodhead, max-vostrikov, maxvostrikov, nauu, 忒休斯~Theseus
按顺序读取的优化
由 Anton Popov 贡献
在从表中读取数据时,ClickHouse 默认应用了一些优化。其中之一是 optimize_read_in_order:如果查询中的 ORDER BY 列是表主键的前缀,或者在完全排序的合并连接中,一个或两个连接表的物理行顺序与连接键的排序顺序一致,则数据可以按磁盘顺序读取,从而跳过排序操作。这通常也有利于内存使用。因为不需要进行完整的内存排序,所需内存更少。此外,当查询使用 LIMIT 子句时,还可以进行短路操作。
然而,optimize_read_in_order 优化虽然防止了数据重新排序,但也降低了读取表数据的并行性。通常,表数据会被划分为不重叠的范围,由 N 个线程并行读取(流式传输)到查询引擎中以进行进一步处理(N 由 max_threads 设置控制)。
下图展示了为何这种方法不适用于 optimize_read_in_order 优化:
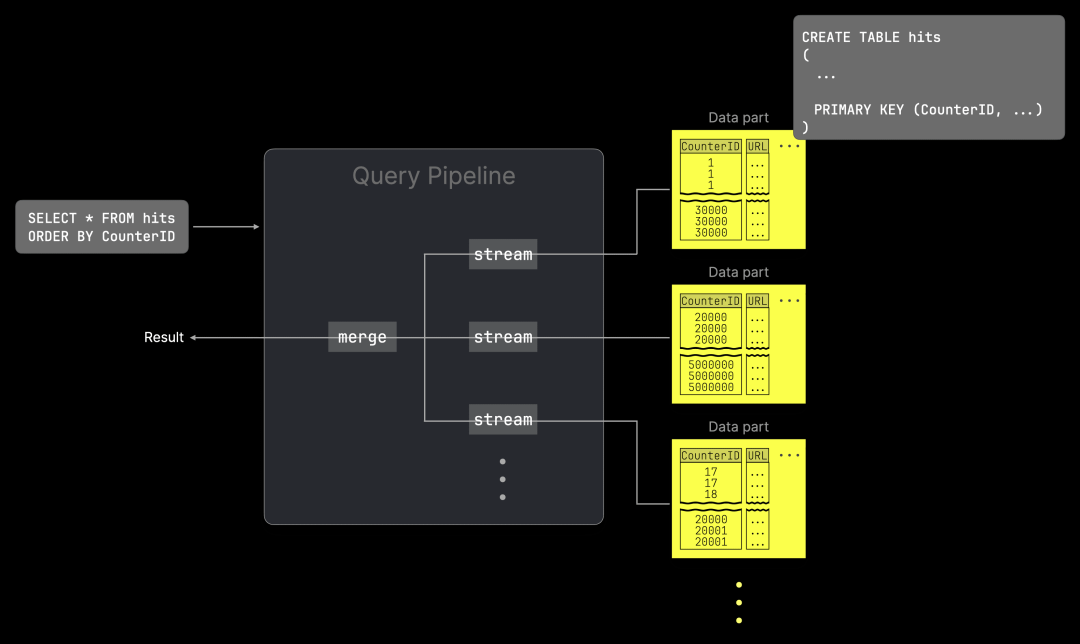
在上图中,我们勾画了属于表的部分数据,这些数据在磁盘上的行(每个数据部分)首先按 CounterID 列排序。我们展示了一个查询管道(物理执行计划),该查询包含一个 ORDER BY 子句,与表在磁盘上的物理行顺序一致。因此,无需重新排序数据。相反,表中已(局部)排序的行通过在各数据部分内以及跨数据部分的交错线性扫描进行合并。这意味着数据不是并发流式传输的,而是顺序处理的。
ClickHouse 24.7 版本现在引入了在合并步骤前对表数据部分进行缓冲的功能,该功能由设置 read_in_order_use_buffering 控制(默认启用)。尽管这增加了内存使用量,但也提升了查询执行的并行性,因为它允许在数据合并到最终结果之前将其并发地流式传输到缓冲区:
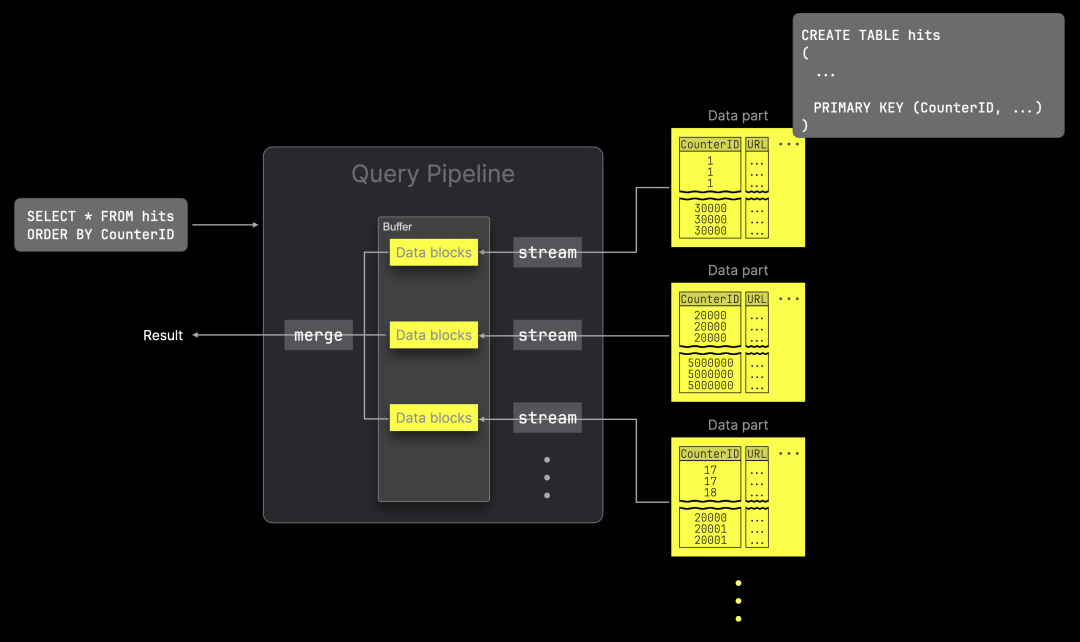
如果查询使用了高选择性过滤器(显著减少了流式传输和缓冲的数据量),应用 optimize_read_in_order 优化的查询性能最多可提升 10 倍。
我们可以通过 Anonymized Web Analytics Data 数据集来看看这一优化的实际效果,该数据集包含 1 亿次匿名页面访问。ClickBench 也使用了这个数据集,我们可以使用提供的 DDL 语句来创建表。
请注意,该表有以下主键:
PRIMARY KEY (CounterID, EventDate, UserID, EventTime, WatchID)接下来,我们将数据插入表中:
INSERT INTO hits SELECT * FROM s3('s3://clickhouse-public-datasets/hits_compatible/hits.parquet');我们将该数据集加载到运行在 AWS c6a.8xlarge 实例上的 ClickHouse 实例中。
首先,我们编写一个不使用新缓冲方法的查询(请注意,我们禁用了文件系统缓存,以便更好地比较这次和下次查询的运行情况):
SELECT
CounterID,
UserID
FROM hits_100m_obfuscated
WHERE RegionID = 2
ORDER BY CounterID ASC
FORMAT `Null`
SETTINGS enable_filesystem_cache = 0,
read_in_order_use_buffering = 0
0 rows in set. Elapsed: 0.590 sec. Processed 100.00 million rows, 1.58 GB (169.48 million rows/s., 2.67 GB/s.)
Peak memory usage: 17.82 MiB.查询耗时约 0.6 秒,使用了 18 MB 的内存。现在,我们启用缓冲功能:
SELECT
CounterID,
UserID
FROM hits_100m_obfuscated
WHERE RegionID = 2
ORDER BY CounterID ASC
FORMAT `Null`
SETTINGS enable_filesystem_cache = 0,
read_in_order_use_buffering = 1
0 rows in set. Elapsed: 0.097 sec. Processed 100.00 million rows, 1.58 GB (1.04 billion rows/s., 16.35 GB/s.)
Peak memory usage: 48.37 MiB.查询时间减少到不到 0.1 秒,内存使用量增加到 48 MB。因此,缓冲功能使查询速度提高了 5 倍,同时内存使用量增加了 3 倍。
更快的并行 Hash Join
由 Nikita Taranov 贡献
每次 ClickHouse 版本更新都会带来 JOIN 的改进。
在本次更新中,我们改进了并行 Hash Join 算法中的哈希表分配。
需要提醒的是,并行 Hash Join 算法是一种哈希连接的变体,它通过将输入数据拆分为多个部分,以并行构建多个哈希表,从而加速构建阶段,但需要付出更高的内存开销作为代价。
默认的 Hash Join 算法通过使用单个哈希表填充来自右表的数据,从而减少内存使用量。为此,右表的数据可以由多个线程并行拆分和读取,但由于哈希表在插入时并不支持线程安全,因此只有一个线程可以将数据填充到哈希表中。如果右表的数据量很大,这可能成为 JOIN 时的瓶颈。
下图展示了并行 Hash Join 算法如何克服这一瓶颈:
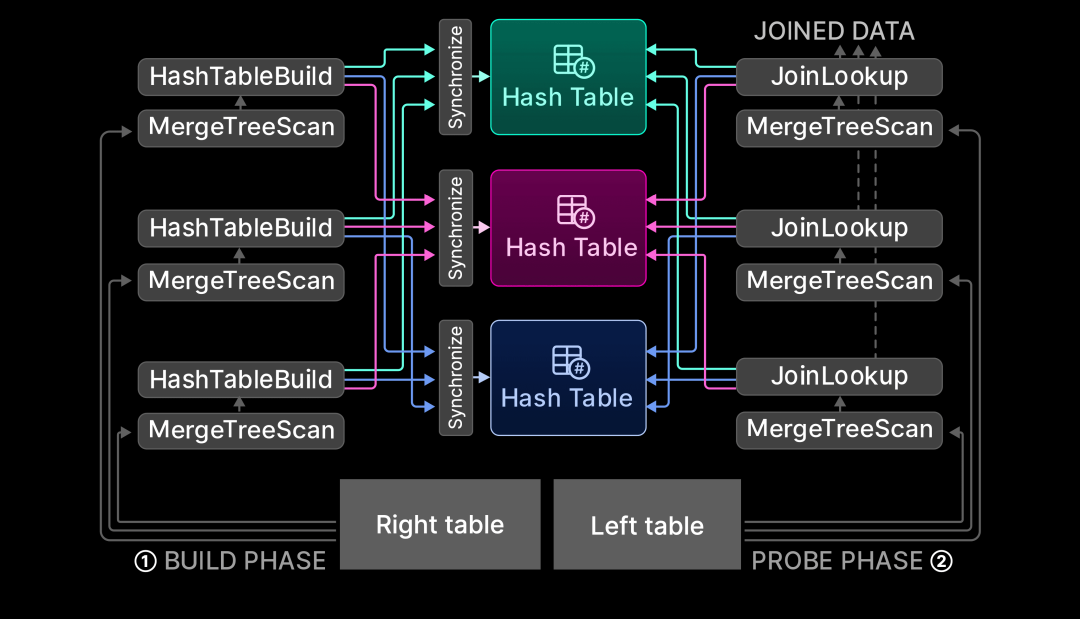
在算法的①构建阶段,来自右表的数据通过 N 个流(N 由 max_threads 设置控制)进行并行拆分和流式传输,以并行填充 N 个哈希表。通过对每一行的连接键应用哈希函数,将每个流的行路由到 N 个哈希表中的一个。用于将行拆分到哈希表的哈希函数与哈希表内部使用的哈希函数不同。
在算法的②探测阶段,左表的数据通过 N 个流并行拆分并流式传输(同样,N 由 max_threads 设置控制)。在每一行的连接键上应用与步骤①相同的“桶哈希函数”,以确定对应的哈希表,并通过查找该哈希表来进行连接。
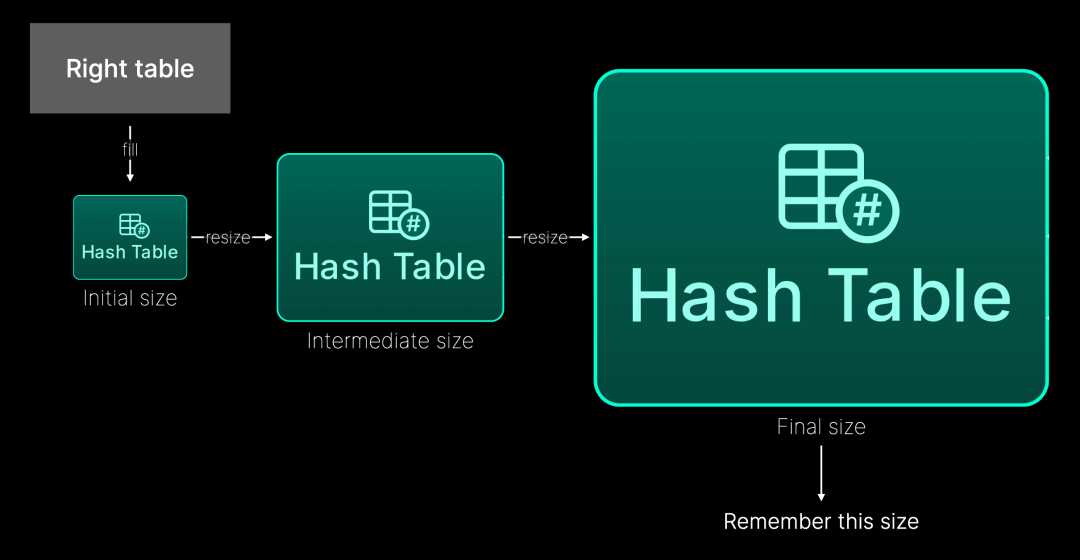
为了避免浪费内存,哈希表会预先分配一个有限的初始大小。如果哈希表已满,则会分配一个更大的新哈希表,将前一个哈希表中的数据复制过来,并释放旧的哈希表。新哈希表的大小通常是通过内部乘数增加前一个哈希表的大小来确定的。
在 ClickHouse 24.7 中,并行哈希连接完成后会收集并缓存哈希表的最终大小(使用 JOIN 的右表名称和连接列名称作为查找键的输入)。在随后的查询执行中,哈希表将根据之前查询运行时的大小进行预分配,从而避免了冗余的中间调整步骤,节省了时间。下图对此进行了可视化:
让我们通过一个具体的例子来演示这一点。
我们使用 ClickBench 表,该表包含 1 亿次匿名页面访问。
首先,我们运行提供的 DDL 语句来创建表。然后插入数据:
INSERT INTO hits SELECT * FROM s3('s3://clickhouse-public-datasets/hits_compatible/hits.parquet');数据加载完成后,表中应包含约 1 亿行:
SELECT count()
FROM hits;
┌──count()─┐
1. │ 99997497 │ -- 100.00 million
└──────────┘我们运行一个执行自连接的 JOIN 查询。请注意,此 JOIN 默认使用 Hash Join 算法:
SELECT count()
FROM hits AS t1
INNER JOIN hits AS t2 ON t1.ClientIP = t2.RemoteIP
WHERE t1.ClientIP != 0;
┌─count()─┐
1. │ 3395861 │ -- 3.40 million
└─────────┘
1 row in set. Elapsed: 5.112 sec. Processed 199.99 million rows, 799.98 MB (39.12 million rows/s., 156.49 MB/s.)
Peak memory usage: 3.25 GiB.现在,我们使用并行 Hash Join 算法运行相同的 JOIN 查询:
SELECT count()
FROM hits AS t1
INNER JOIN hits AS t2 ON t1.ClientIP = t2.RemoteIP
WHERE t1.ClientIP != 0
SETTINGS join_algorithm = 'parallel_hash';
┌─count()─┐
1. │ 3395861 │ -- 3.40 million
└─────────┘
1 row in set. Elapsed: 0.517 sec. Processed 199.99 million rows, 799.98 MB (387.03 million rows/s., 1.55 GB/s.)
Peak memory usage: 3.44 GiB.在相同的硬件上,该查询运行速度提高了 10 倍。
当我们在 ClickHouse 进程启动后首次运行启用了并行 Hash Join 算法和跟踪级别日志记录的查询时,可以在日志中看到 ClickHouse 正在收集和缓存哈希表大小统计信息:
SELECT count()
FROM hits AS t1
INNER JOIN hits AS t2 ON t1.ClientIP = t2.RemoteIP
WHERE t1.ClientIP != 0
SETTINGS
join_algorithm = 'parallel_hash',
send_logs_level = 'trace';
...
<Trace> HashTablesStatistics: Statistics updated for key=18113390195926062714: new sum_of_sizes=9594872, median_size=149909
...当我们在不重启 ClickHouse 进程的情况下重新运行查询(并启用跟踪级别日志记录)时,可以看到 ClickHouse 在预分配之前正在访问缓存的哈希表统计信息。
SELECT count()
FROM hits AS t1
INNER JOIN hits AS t2 ON t1.ClientIP = t2.RemoteIP
WHERE t1.ClientIP != 0
SETTINGS
join_algorithm = 'parallel_hash',
send_logs_level = 'trace';
...
<Trace> HashTablesStatistics: An entry for key=18113390195926062714 found in cache: sum_of_sizes=9594872, median_size=149909
... ASOF JOIN 的 Merge Join 算法
由 Vladimir Cherkasov 贡献
ClickHouse 是首个在 2019 年 4 月引入 ASOF JOIN 的 SQL DBMS。
需要提醒的是,ASOF JOIN 提供了非精确匹配的功能。如果左表中的某行在右表中没有找到精确匹配,则会使用右表中最接近的匹配行作为替代。
这在时间序列分析中尤其有用,并且可以显著减少查询的复杂性。
此外,当 ClickHouse 作为机器学习的特征存储时,ASOF JOIN 也非常实用。它可以轻松地将特征组合起来,生成一组特征向量。
在此之前,ASOF JOIN 仅支持内存绑定的 Hash Join 和并行 Hash Join 算法。
自 ClickHouse 24.7 版本起,ASOF JOIN 还支持非内存绑定的全排序 Merge Join 算法。需要提醒的是,该算法的连接策略要求首先按连接键对数据进行排序,然后通过交错线性扫描和合并两个表的已排序数据块流来确定连接匹配:
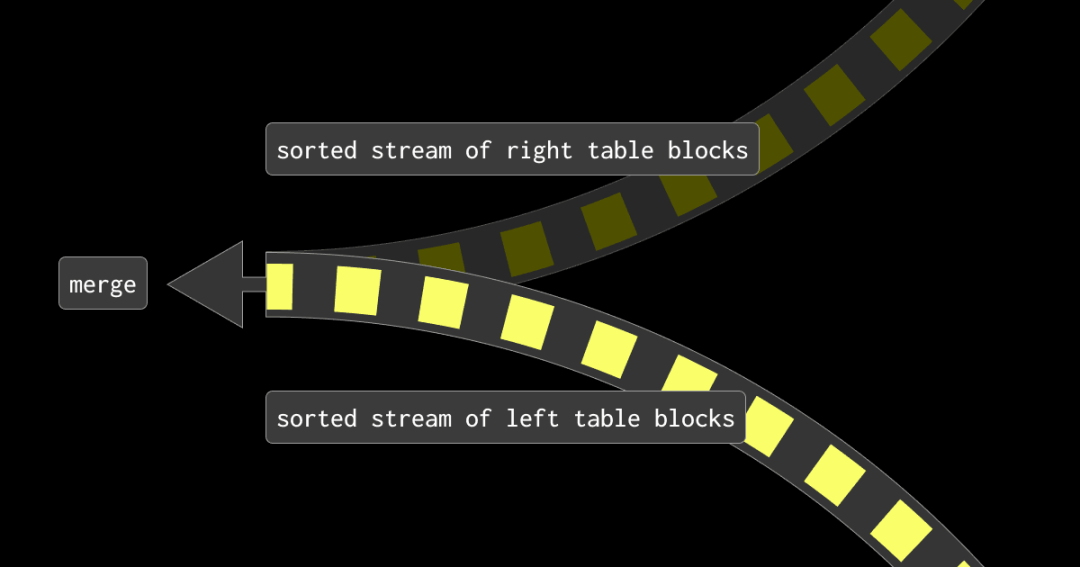
全排序 Merge Join 可以利用一个或两个表的物理行顺序,允许跳过排序(并受益于上文提到的按顺序读取的新优化)。在这种情况下,连接性能可以与 Hash Join 算法媲美,同时通常需要显著更少的内存。否则,全排序 Merge Join 需要在确定连接匹配之前对表中的行进行完全排序。排序可以在内存中进行,并且内存使用通常与连接表的大小无关。
让我们来看一个实际例子。
假设我们在 hits 表中跟踪互联网用户的点击事件,而在 sessions 表中跟踪用户会话。然后,我们可以使用 ASOF JOIN 简洁地构建一个查询,查找每个会话的第一个用户点击事件:
SELECT ...
FROM hits h ASOF JOIN sessions s
ON h.UserID = s.UserID AND h.EventTime > s.StartTime;我们使用 hits 表模拟 sessions 表,并将上述查询重新表述为一个自 ASOF JOIN:
SELECT ...
FROM hits t1 ASOF JOIN hits t2
ON t1.UserID = t2.UserID AND t1.EventTime < t2.EventTime;为了运行此查询,我们首先使用 ClickBench 提供的 DDL 语句创建 hits 表。
接下来,我们插入数据(1 亿行):
INSERT INTO hits SELECT * FROM s3('s3://clickhouse-public-datasets/hits_compatible/hits.parquet');现在,我们准备使用默认的 Hash Join 算法运行上述 ASOF JOIN 查询:
SELECT count()
FROM hits t1 ASOF JOIN hits t2
ON t1.UserID = t2.UserID AND t1.EventTime < t2.EventTime;
┌──count()─┐
1. │ 81878322 │ -- 81.88 million
└──────────┘
1 row in set. Elapsed: 11.849 sec. Processed 199.99 million rows, 2.40 GB (16.88 million rows/s., 202.55 MB/s.)
Peak memory usage: 6.49 GiB.接下来,我们使用全排序 Merge Join 算法运行相同的查询:
SELECT count()
FROM hits t1 ASOF JOIN hits t2
ON t1.UserID = t2.UserID AND t1.EventTime < t2.EventTime
SETTINGS
join_algorithm = 'full_sorting_merge';
┌──count()─┐
1. │ 81878322 │ -- 81.88 million
└──────────┘
1 row in set. Elapsed: 5.041 sec. Processed 199.99 million rows, 2.40 GB (39.68 million rows/s., 476.11 MB/s.)
Peak memory usage: 2.41 GiB.如您所见,对于我们的特定数据集,使用全排序 Merge Join 算法实现的 ASOF JOIN 查询速度比使用 Hash Join 算法快两倍多,峰值内存消耗也减少了一半以上。然而,这并非普遍规律,建议在您的特定数据集上进行测试。
percent_rank
由 lgbo-ustc 贡献
percent_rank 返回窗口分区内各行的相对排名(即,百分位数)。
让我们通过一个模拟的足球运动员薪资数据集来看看它是如何工作的。我们将创建一个名为 salaries 的表格:
CREATE TABLE salaries
ORDER BY team AS
SELECT *
FROM url(
'https://raw.githubusercontent.com/ClickHouse/examples/main/LearnClickHouseWithMark/WindowFunctions-Ranking/data/salaries.csv'
)
SETTINGS schema_inference_make_columns_nullable=0;然后,我们可以计算这些薪资的排名和百分位排名:
SELECT
team, player, weeklySalary AS salary, position AS pos,
rank() OVER (ORDER BY salary DESC) AS rank,
round(percent_rank() OVER (ORDER BY salary DESC), 6) AS percentRank
FROM salaries
ORDER BY salary DESC
LIMIT 10┌─team─────────────────────────┬─player──────────┬─salary─┬─pos─┬─rank─┬─percentRank─┐
│ North Pamela Trojans │ Robert Griffin │ 399999 │ GK │ 1 │ 0 │
│ Jimmyville Legionnaires │ Nathan Thompson │ 399998 │ D │ 2 │ 0.000004 │
│ Stephaniemouth Trojans │ Benjamin Cline │ 399998 │ D │ 2 │ 0.000004 │
│ Maryhaven Generals │ Scott Chavez │ 399998 │ M │ 2 │ 0.000004 │
│ Michaelborough Rogues │ Dan Conner │ 399998 │ M │ 2 │ 0.000004 │
│ Nobleview Sages │ William Rubio │ 399997 │ M │ 6 │ 0.00002 │
│ North Christinaview Archers │ Robert Cook │ 399991 │ M │ 7 │ 0.000024 │
│ North Krystal Knights-Errant │ Juan Bird │ 399986 │ GK │ 8 │ 0.000028 │
│ Claireberg Vikings │ Benjamin Taylor │ 399985 │ M │ 9 │ 0.000032 │
│ Andreaberg Necromancers │ John Lewis │ 399985 │ D │ 9 │ 0.000032 │
└──────────────────────────────┴─────────────────┴────────┴─────┴──────┴─────────────┘自动命名元组
由 Amos Bird 贡献
如果为元组元素指定别名(使用 AS),系统将自动创建一个命名元组。我们来看看它在 24.6 版本中的工作方式:
docker run --rm clickhouse/clickhouse-server:24.6 \
clickhouse-local \
--query \
"SELECT ('Hello' AS a, 123 AS b) AS x,
toTypeName(x) AS type,
toJSONString(x) AS json
FORMAT Vertical"Row 1:
──────
x: ('Hello',123)
type: Tuple(String, UInt8)
json: ["Hello",123]现在,再看看 24.7 版本中的变化:
docker run --rm clickhouse/clickhouse-server:24.7 \
clickhouse-local \
--query \
"SELECT ('Hello' AS a, 123 AS b) AS x,
toTypeName(x) AS type,
toJSONString(x) AS json
FORMAT Vertical"Row 1:
──────
x: ('Hello',123)
type: Tuple(
a String,
b UInt8)
json: {"a":"Hello","b":123}征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









