








本文字数:8293;估计阅读时间:21分钟
作者: Lionel Palacin
本文在公众号【ClickHouseInc】首发

在生产环境中,数据库系统的监控是不可或缺的。了解部署的健康状况是避免中断或快速解决问题的关键。
ClickHouse 深知这一点,因此默认提供了一组预配置的高级监控仪表板。高级仪表板是一款轻量级工具,可深入分析 ClickHouse 系统及其运行环境,帮助您提前识别性能瓶颈、系统故障以及低效操作,从而保持系统高效运行。
无论您是处理高查询负载的数据工程师,还是保障 ClickHouse 高可用性的站点稳定性工程师 (SRE),高级仪表板都能为您提供高效的监控和故障排查能力。该工具支持 ClickHouse OSS(开源软件)和 ClickHouse Cloud 环境。
快速上手高级监控仪表板
高级仪表板无需额外安装即可使用。根据您的运行环境,可能需要启用指标日志和异步指标日志来生成默认的可视化效果。如果您使用的是 ClickHouse Cloud,这些功能已默认启用,无需额外配置。
若需手动启用,请参考全球设置文档,修改服务器配置文件 /etc/clickhouse-server/config.d/metric_log.xml:
<clickhouse>
<metric_log>
<database>system</database>
<table>metric_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<collect_interval_milliseconds>1000</collect_interval_milliseconds>
<max_size_rows>1048576</max_size_rows>
<reserved_size_rows>8192</reserved_size_rows>
<buffer_size_rows_flush_threshold>524288</buffer_size_rows_flush_threshold>
<flush_on_crash>false</flush_on_crash>
</metric_log>
<asynchronous_metric_log>
<database>system</database>
<table>asynchronous_metric_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<collect_interval_milliseconds>1000</collect_interval_milliseconds>
<max_size_rows>1048576</max_size_rows>
<reserved_size_rows>8192</reserved_size_rows>
<buffer_size_rows_flush_threshold>524288</buffer_size_rows_flush_threshold>
<flush_on_crash>false</flush_on_crash>
</asynchronous_metric_log>
</clickhouse>启动 ClickHouse 服务器后,您可以通过以下地址访问高级监控仪表板:
<your_clickhouse_url>/dashboard
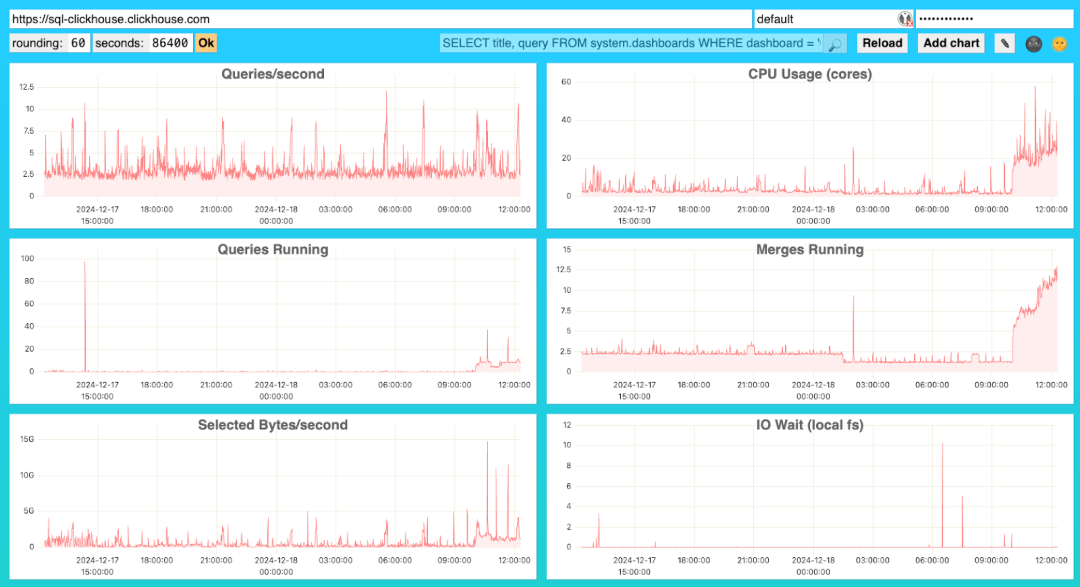
默认情况下,您可以使用系统的默认用户登录访问仪表板。但为了安全起见,建议为此专门创建一个独立的用户。
要正常运行默认的可视化功能,该用户需要具备以下表的读取权限:
-
system.dashboards:存储仪表板的可视化定义。
-
system.metric_log:记录来自 system.metrics 和 system.events 表的历史指标值。
-
system.asynchronous_metric_log:保存 system.asynchronous_metrics 的历史数据。
同时,用户还需要以下两个特殊权限:CREATE TEMPORARY TABLE ON *.* 和 REMOTE ON *.*。
下面,我们为实验创建一个仪表板专用用户:
-- Create dashboard user
CREATE USER dashboard_user IDENTIFIED BY ;
-- Create dashboard role and assign to dashboard_user
CREATE ROLE dashboard;
GRANT dashboard TO dashboard_user;
-- Grant rights to access advanced dashboards
GRANT REMOTE ON *.* to dashboard;
GRANT CREATE TEMPORARY TABLE on *.* to dashboard;
GRANT SELECT ON system.metric_log to dashboard;
GRANT SELECT ON system.asynchronous_metric_log to dashboard;
GRANT SELECT ON system.dashboards to dashboard;您可以通过在 URL 中添加用户名参数的方式访问,例如:
<your_clickhouse_url>/dashboard?user=dashboard
登录时,输入创建仪表板用户时设置的密码。
在页面顶部的导航栏中,您可以查看应用程序加载仪表板定义时使用的 SQL 查询。
-- Load dashboard definition
SELECT title, query FROM system.dashboards WHERE dashboard = 'Overview'仪表板的查询过滤器默认设置为 "Overview"。不同的仪表板集适用于不同的场景:默认的 "Overview" 仪表板适合本地部署,而 "Cloud Overview" 则针对云部署环境进行了优化。
高级仪表板的默认可视化功能
高级仪表板内置了一系列默认图表,能够为您提供 ClickHouse 系统的实时运行状况和性能洞察。为了便于查看,这些图表被分为三类,分别对应不同的使用场景。
ClickHouse 专用指标
这些图表专注于监控 ClickHouse 实例的运行状况和性能表现:
-
每秒查询数 (Queries Per Second):监控系统每秒处理的查询数量。
-
每秒读取行数 (Selected Rows/Sec):显示查询读取的数据行数。
-
每秒插入行数 (Inserted Rows/Sec):反映数据写入的速率。
-
MergeTree 活跃分片总数 (Total MergeTree Parts):展示 MergeTree 表中活跃的分片数,帮助识别未批量处理的插入操作。
-
单分区最大分片数 (Max Parts for Partition):突出显示某个分区中分片数量的峰值。
-
当前运行的查询数 (Queries Running):显示系统中正在执行的查询数目。
-
每秒读取字节数 (Selected Bytes Per Second):显示查询读取的数据量。
系统健康状况相关指标
除了 ClickHouse 本身,底层系统的状态同样至关重要。这些图表帮助您监控相关的系统资源:
-
I/O 等待时间 (IO Wait):跟踪磁盘 I/O 操作的等待时间。
-
CPU 等待时间 (CPU Wait):测量因 CPU 争用导致的操作延迟。
-
磁盘读取量 (Read From Disk):显示从磁盘读取的数据量。
-
文件系统读取量 (Read From Filesystem):记录从文件系统(包括页面缓存)读取的数据量。
-
内存使用量 (Memory tracked, bytes):展示 ClickHouse 跟踪的内存占用情况。
-
15 分钟平均负载 (Load Average (15 minutes)):显示系统最近 15 分钟的平均负载。
-
用户空间 CPU 使用率 (OS CPU Usage (Userspace)):监控运行用户空间代码时的 CPU 使用情况。
-
内核空间 CPU 使用率 (OS CPU Usage (Kernel)):监控运行内核代码时的 CPU 使用情况。
ClickHouse Cloud 专用指标
ClickHouse Cloud 采用对象存储(如 S3 类型)保存数据。以下图表可帮助您检测相关接口的性能:
-
S3 读取等待时间 (S3 Read wait):反映对 S3 进行读取请求的延迟。
-
每秒 S3 读取错误数 (S3 read errors per second):监控读取错误的发生频率。
-
每秒从 S3 读取数据量 (Read From S3 (bytes/sec)):展示从 S3 存储读取数据的速率。
-
每秒写入 S3 的请求数 (Disk S3 write req/sec):监控写入 S3 的操作频率。
-
每秒读取 S3 的请求数 (Disk S3 read req/sec):监控从 S3 读取的操作频率。
-
页面缓存命中率 (Page cache hit rate):评估页面缓存的使用效率。
-
文件系统缓存命中率 (Filesystem cache hit rate):显示文件系统缓存的命中情况。
-
文件系统缓存大小 (Filesystem cache size):记录文件系统缓存的当前大小。
-
每秒发送的网络流量 (Network send bytes/sec):监控出站网络流量的速率。
-
每秒接收的网络流量 (Network receive bytes/sec):监控入站网络流量的速率。
-
并发网络连接数 (Concurrent network connections):显示当前的并发网络连接数量。
定制高级仪表板中的图表
在高级仪表板中,每个可视化图表都由一个关联的 SQL 查询驱动,这些查询负责提供图表的数据内容。您可以通过点击图表上的铅笔图标来修改相关查询。
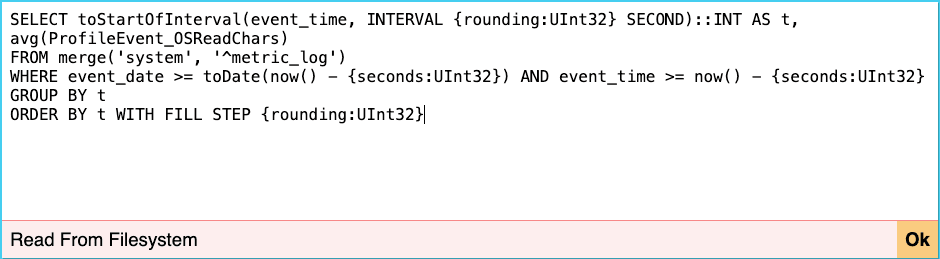
在编辑界面中,您可以根据需求调整查询内容。此外,您还可以通过点击“添加图表 (Add chart)”按钮新增自定义图表,并在新图表中编辑对应的查询。例如,我们可以新增一个图表来跟踪主键的内存使用情况。以下是为该图表提供支持的 SQL 查询:
SELECT toStartOfInterval(event_time, INTERVAL {rounding:UInt32} SECOND)::INT AS t, avg(value) FROM merge('system', '^asynchronous_metric_log') WHERE event_date >= toDate(now() - {seconds:UInt32}) AND event_time >= now() - {seconds:UInt32} AND metric = 'TotalPrimaryKeyBytesInMemory' GROUP BY t ORDER BY t WITH FILL STEP {rounding:UInt32}需要注意,通过 Web 应用程序添加的图表是以查询参数的形式编码的,这使得它们可以方便地添加到书签中。
如果您需要一种更稳定的方式,可以将自定义图表直接存储到 ClickHouse 数据库中。操作步骤如下:
1. 创建一个与默认表 system.dashboards 架构一致的新表。
-- Create a separate database
CREATE DATABASE custom;
-- Create the custom dashboard table
CREATE TABLE custom.dashboards
(
`dashboard` String,
`title` String,
`query` String
) ORDER BY ()2. 将您的自定义可视化内容插入到新表中。
-- Total size primary keys visualization query
INSERT INTO custom.dashboards (dashboard, title, query)
VALUES (
'Overview',
'Total primary keys size',
'SELECT toStartOfInterval(event_time, INTERVAL {rounding:UInt32} SECOND)::INT AS t, avg(value) FROM merge(\'system\', \'^asynchronous_metric_log\') WHERE event_date >= toDate(now() - {seconds:UInt32}) AND event_time >= now() - {seconds:UInt32} AND metric = \'TotalPrimaryKeyBytesInMemory\' GROUP BY t ORDER BY t WITH FILL STEP {rounding:UInt32}'
);通过这种方式,您可以将自定义数据库中的仪表板定义与 Web 应用程序中默认的定义合并,从而实现扩展和优化。
SELECT title, query FROM merge(REGEXP('custom|system'),'dashboards') WHERE dashboard = 'Overview'最后,请确保仪表板用户具备访问自定义数据库所需的权限。例如,用户需要对相关表拥有读取和修改的权限,以便正确加载和管理仪表板内容。
如何通过高级仪表板识别问题
实时监控 ClickHouse 服务的运行状况,可以帮助您在问题影响业务之前及时发现和解决问题。以下是利用高级仪表板可以识别的一些常见问题。
未批量插入的数据问题
根据最佳实践文档的建议,在 ClickHouse 中插入数据时应尽量使用批量插入。
合理的批量大小可以显著减少数据写入过程中创建的部分数量,从而优化磁盘写入效率,并降低合并操作的频率。
要判断插入操作是否优化,可以关注以下两个关键指标:每秒插入行数 (Inserted Rows/sec) 和每个分区的最大部分数 (Max Parts for Partition)。
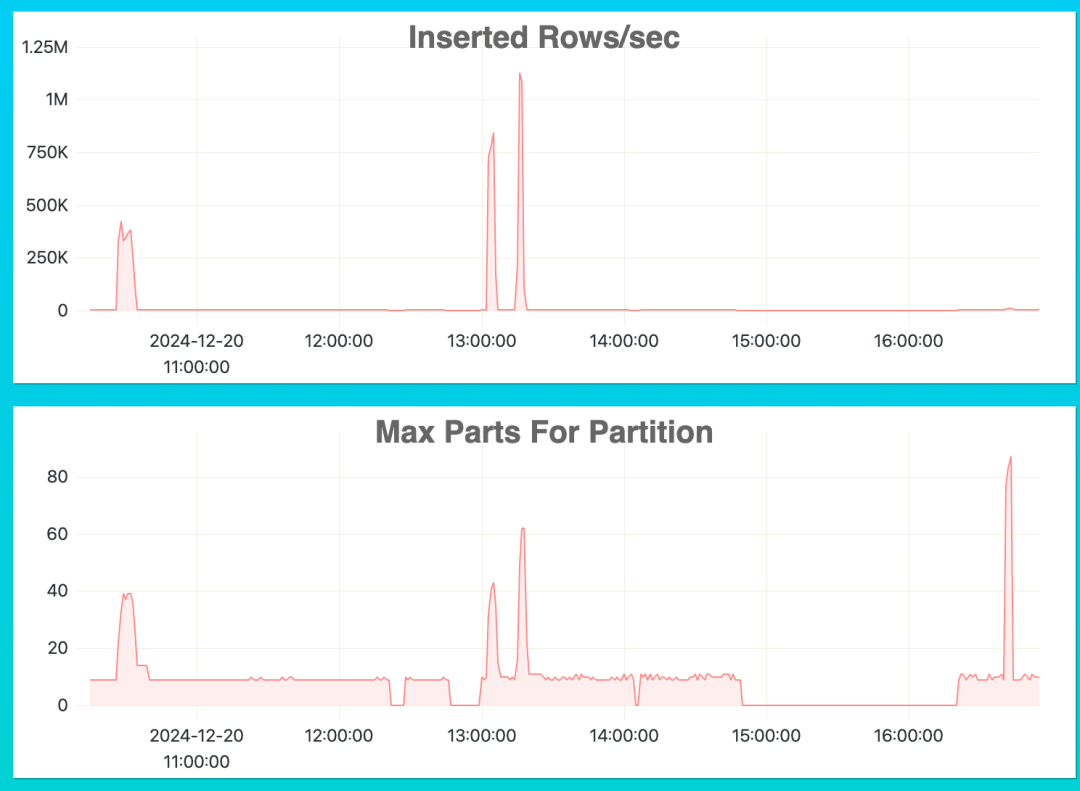
如上图所示,从 13 点到 14 点之间,每秒插入行数和每个分区的最大部分数出现了两次峰值。这表明数据摄取速度是合理的。
然而,16 点之后,我们注意到每个分区的最大部分数急剧上升,但每秒插入行数却很低。这表明数据分区的大小可能未得到有效优化。
资源密集型查询问题
某些 SQL 查询可能会占用大量资源(如 CPU 或内存)。监控这些查询的资源消耗情况,对于保障系统整体性能至关重要。
如果资源使用量突然增加,而查询吞吐量并未显著变化,则可能是某些高成本查询导致的。这种现象可以通过高级仪表板快速发现。
以下是一个 CPU 使用率达到峰值,但每秒执行的查询数量未发生显著变化的示例:

主键设计问题
高级仪表板还可以帮助识别主键设计不当的问题。根据文档,针对具体使用场景选择合适的主键,能够显著提升查询性能,因为这样可以减少 ClickHouse 在查询过程中需要读取的行数。
您可以通过监控“每秒选中行数 (Selected Rows/sec)”指标来判断主键设计是否需要优化。选中行数的突然激增,可能意味着查询吞吐量的增加,也可能表明某些查询需要选中大量行来执行操作。
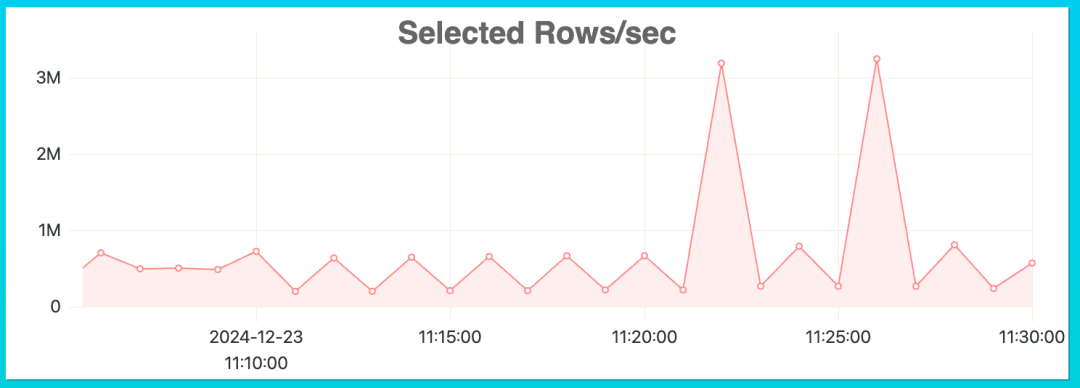
通过时间戳过滤条件,您可以在 system.query_log 表中找到峰值时间段内执行的查询。
例如,我们可以运行以下查询,查看上午 11:20 到 11:30 之间执行的所有查询,以找出哪些查询读取了过多的行。
SELECT
type,
event_time,
query_duration_ms,
query,
read_rows,
tables
FROM system.query_log
WHERE has(databases, 'default') AND (event_time >= '2024-12-23 11:20:00') AND (event_time <= '2024-12-23 11:30:00') AND (type = 'QueryFinish')
ORDER BY query_duration_ms DESC
LIMIT 5
FORMAT VERTICAL
Row 1:
──────
type: QueryFinish
event_time: 2024-12-23 11:22:55
query_duration_ms: 37407
query: SELECT
toStartOfMonth(review_date) AS month,
any(product_title),
avg(star_rating) AS avg_stars
FROM amazon_reviews_no_pk
WHERE
product_category = 'Home'
GROUP BY
month,
product_id
ORDER BY
month DESC,
product_id ASC
LIMIT 20
read_rows: 150957260
tables: ['default.amazon_reviews_no_pk']
Row 2:
──────
type: QueryFinish
event_time: 2024-12-23 11:26:50
query_duration_ms: 7325
query: SELECT
toStartOfMonth(review_date) AS month,
any(product_title),
avg(star_rating) AS avg_stars
FROM amazon_reviews_no_pk
WHERE
product_category = 'Home'
GROUP BY
month,
product_id
ORDER BY
month DESC,
product_id ASC
LIMIT 20
read_rows: 150957260
tables: ['default.amazon_reviews_no_pk']
Row 3:
──────
type: QueryFinish
event_time: 2024-12-23 11:24:10
query_duration_ms: 3270
query: SELECT
toStartOfMonth(review_date) AS month,
any(product_title),
avg(star_rating) AS avg_stars
FROM amazon_reviews_pk
WHERE
product_category = 'Home'
GROUP BY
month,
product_id
ORDER BY
month DESC,
product_id ASC
LIMIT 20
read_rows: 6242304
tables: ['default.amazon_reviews_pk']
Row 4:
──────
type: QueryFinish
event_time: 2024-12-23 11:28:10
query_duration_ms: 2786
query: SELECT
toStartOfMonth(review_date) AS month,
any(product_title),
avg(star_rating) AS avg_stars
FROM amazon_reviews_pk
WHERE
product_category = 'Home'
GROUP BY
month,
product_id
ORDER BY
month DESC,
product_id ASC
LIMIT 20
read_rows: 6242304
tables: ['default.amazon_reviews_pk']在这个示例中,我们看到同一个查询分别对 amazon_reviews_no_pk 和 amazon_reviews_pk 表进行了执行。这表明可能有人正在测试 amazon_reviews 表的主键设计选项。
总结
通过这篇文章,我们了解了 ClickHouse 的高级仪表板功能,包括如何开始使用它,以及如何利用它识别和解决常见问题。
无论您选择哪种部署方式,这款轻量级的监控工具都可以开箱即用。如果您倾向于使用 Prometheus 等第三方监控工具,也可以参考官方文档中的示例进行配置。
此外,ClickHouse Cloud 还提供了专属的新仪表板功能,让您可以创建更丰富的可视化效果,值得进一步探索。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









