








本文字数:15679;估计阅读时间:40 分钟
作者:The ClickHouse & Ruby Central teams
本文在公众号【ClickHouselnc】首发

Ruby 开发者请注意,我们带来了一个好消息!继 ClickPy 在 Python 社区取得巨大反响之后,我们与 Ruby Central 合作,在 sql.clickhouse.com 上推出了免费的 Ruby Gem 下载分析服务。通过这个平台,Ruby 社区可以轻松使用 SQL 查询,对自 2017 年以来的全部 Gem 下载数据进行分析——总数据量超过 1800 亿行!
SELECT toStartOfMonth(date) as month, sum(count) as total_downloads
FROM rubygems.downloads_per_day
GROUP BY month
ORDER BY month ASC如果你想了解这项服务的来龙去脉,请继续阅读;如果更关心如何使用,也可以直接查看下方示例查询,或访问公共服务页面立即开始体验。
一切始于 Python
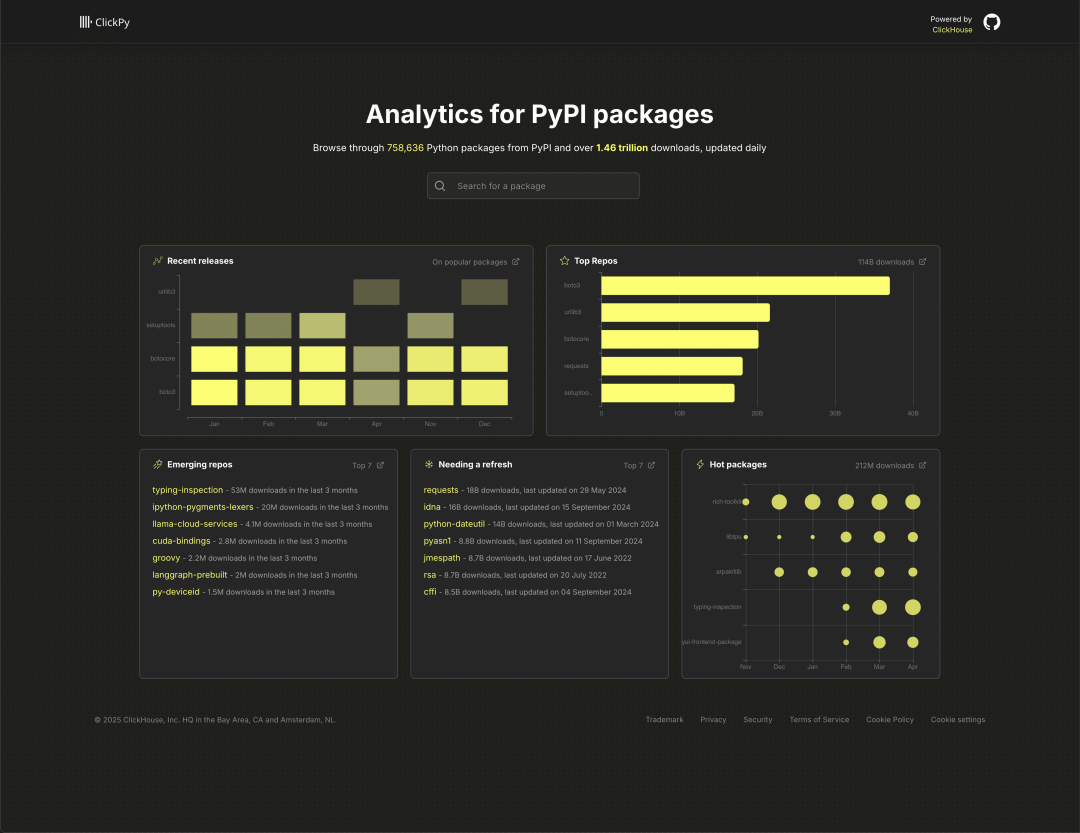
2024 年初,我们推出了 ClickPy,这是一个用于分析 Python 软件包下载情况的简单应用。它背后的数据集会记录通过 PyPI 仓库发生的每一次下载 —— 每当开发者执行一次 pip install,ClickHouse 就会新增一条记录。
短短九个月内,数据量就突破了 1 万亿行。目前的累计下载总数已超过 1.43 万亿,并且每天仍以超过 20 亿行的速度增长。
SELECT formatReadableQuantity(count()) as number_rows FROM pypi.pypiSELECT date, sum(count) AS total
FROM pypi.pypi_downloads_per_day
GROUP BY date
ORDER BY date ASC除了网页界面,包维护者和技术爱好者还可以通过 sql.clickhouse.com,直接使用 SQL 查询这个数据集。这项免费的服务广受欢迎,每月的查询量已经超过 50 万次!(上面的示例查询正是基于这项服务)
对于好奇这项服务背后技术细节的用户,我们撰写了详细的博客和文档,介绍了 ClickPy 的实现原理、所用的 ClickHouse 功能,以及它如何在面对上万亿行数据时依然实现毫秒级响应。同时,我们也分享了如何构建一个稳定、公开、并可供用户公平访问的服务。
欢迎 Ruby Central 加入
在 ClickHouse,我们对大型数据集情有独钟。所以当 Ruby Central 的 Marty Haught 联系我们,希望为 Ruby 社区打造一项类似的服务时,我们欣然响应:
Hi Dale,
RubyGems 团队的几位成员在看到 ClickPy 网站后感到非常惊艳,他们很好奇是否也能为 RubyGems 创建一个类似的分析平台。你知道 ClickHouse 是否愿意支持开源软件包仓库的分析服务吗?
谢谢,Marty
除了 PyPI 数据集,sql.clickhouse.com 目前还托管着超过 35 个公共数据集,每一个都配有完整的文档说明,并且支持免费查询。因此,当我们有机会再新增一个包管理类数据集 —— 特别是像 RubyGems 这样对开源社区具有高度价值、在技术层面也颇具挑战的数据集时,我们当然不会错过。
在与 Marty 以及 Ruby Central 的 Samuel Giddens 进行了一次简短的沟通后,我们确认了一个并不让人意外的好消息:RubyGems 的数据结构与 PyPI 的结构高度相似。
Ruby 数据集
Ruby Central 是一个支持 Ruby 语言及其生态系统的非营利组织。他们还负责维护 RubyGems 包管理仓库和 gem 命令行工具,这些都是 Ruby 社区赖以运行的重要基础设施。
如果你曾经安装过 Ruby 包(也称为 gem),那么你用到的就是 RubyGems。就像 Python 用户使用 pip 一样,Ruby 开发者只需输入一行命令,例如 gem install rails,即可完成安装。
在背后,这个命令会向 Ruby Central 维护的 RubyGems.org 包注册中心发起一个请求。每当开发者安装一个 gem,系统都会记录包括包名、版本号、平台和时间戳等元数据。
这些操作构成了几个有价值的数据集。
下载日志
每一条记录都包含时间戳、包名、版本、平台信息,以及大量客户端环境的元数据,比如所用的 Ruby 版本、操作系统、下载是否由 Bundler 或 CI 触发、还有如国家和城市的地理位置数据。同时还会记录请求和响应的技术细节,包括 TLS 协议版本、HTTP 状态码、响应时延和缓存行为等。这些信息非常适合用于分析 Ruby 生态系统中的下载趋势、使用模式和运行环境。
截至 2025 年 4 月,这个下载日志已经是目前规模最大的一个数据集,总行数超过 1800 亿,数据可追溯到 2017 年。我们也希望这部分数据尽量保持实时更新。考虑到其体量庞大,Ruby Central 提供了 GCS bucket 的数据分发方式,文件以 gzip 压缩的 NDJSON 格式存储,并且每小时生成一次。
每日聚合下载量
Ruby Central 还发布了一个预聚合的数据集,提供每个 gem 的每日下载统计信息。每条记录包括包名、日期、当天的下载次数(daily_downloads),以及截至当日的累计总下载量(total_downloads)。这个数据集会定期更新,可在 GitHub 上获取。虽然它不具备前文提到的数据集那样丰富的元数据和细粒度,但非常适合用于快速趋势分析,让你无需遍历原始日志就能高效观察长期变化。
一些熟悉 ClickHouse 的用户可能会想,既然我们已有原始日志数据,是否还有必要保留这个聚合版本?虽然确实可以通过 ClickHouse 内建的物化视图(materialized view,详见下文)或使用查询按日分组的方式来生成每日下载数据,但这个聚合数据集可以追溯到 2013 年,因此仍具有重要的历史分析价值。
每周数据导出
Ruby Central 还会将 gem 的元数据以每周为单位导出,并上传至 GitHub,形式上类似于 PyPI 提供的项目元数据。这些数据集提供了超越下载数量的更丰富的 Ruby 生态视角,包括:
- attestations(认证信息):包含特定 gem 版本的签名元数据,例如软件物料清单(SBOM)和安全认证信息,以 JSON 格式存储。
- deletions(删除记录):记录已被移除的 gem 版本,包含 gem 名称、版本、平台和执行删除操作的用户信息。
- dependencies(依赖关系):记录每个 gem 声明的依赖项、版本约束以及作用范围(如运行时或开发依赖)。
- gem_downloads(版本下载总量):记录每个 gem 版本的累计下载次数,用于分析其在某一时点的流行度。
- linksets(链接信息):包含与每个 gem 相关的链接地址,如主页、文档、源代码仓库和问题追踪系统等。
- rubygems(Gem 列表):提供所有 gem 的主目录,包括名称、创建时间和所属组织等基本信息。
- versions(版本信息):列出每个已发布版本的详细数据,包括作者、描述、许可证、依赖条件、校验和,以及该版本是否已被撤回。
这些数据集非常适合用于分析软件包元数据、依赖结构以及生态系统的发展趋势,能为构建可视化仪表盘、执行安全审计或洞察供应链提供有力支持。
通常来说,每周数据导出是全量更新,上传到 GitHub 的文件会被新版本完全替换;而每日聚合下载数据则是增量更新的,每次只添加最近 7 天的新记录。
此外,我们还特别确保所有数据的加载流程完全基于 ClickHouse 的原生机制,以尽可能简化数据摄取逻辑并提升处理效率。
数据加载
下载日志
虽然下载日志是目前体量最大的一个数据集,但它其实是最容易导入的。该数据集的结构非常简单:
CREATE TABLE rubygems.downloads
(
`timestamp` DateTime,
`request_path` String,
`request_query` String,
`user_agent` Tuple(
agent_name String,
agent_version String,
bundler String,
ci String,
command String,
jruby String,
options String,
platform Tuple(
cpu String,
os String,
version String),
ruby String,
rubygems String,
truffleruby String),
`tls_cipher` String,
`time_elapsed` Int64,
`client_continent` String,
`client_country` String,
`client_region` String,
`client_city` String,
`client_latitude` String,
`client_longitude` String,
`client_timezone` String,
`client_connection` String,
`request` String,
`request_host` String,
`request_bytes` Int64,
`http2` Bool,
`tls` Bool,
`tls_version` String,
`response_status` Int64,
`response_text` String,
`response_bytes` Int64,
`response_cache` String,
`cache_state` String,
`cache_lastuse` Float64,
`cache_hits` Int64,
`server_region` String,
`server_datacenter` String,
`gem` String,
`version` String,
`platform` String
)
ENGINE = MergeTree
ORDER BY (gem, toDate(timestamp))Ruby Central 会将这些日志以压缩 JSON 的形式上传至 GCS bucket,而 ClickHouse 原生支持从 GCS 读取 JSON 和 gzip 格式文件。这意味着我们甚至可以直接查询这些文件,无需提前导入。
SELECT
toStartOfMonth(timestamp) AS month,
count()
FROM gcs('https://storage.googleapis.com/clickhouse-rubygems/backfill/2017//**/*.json.gz', '', '')
GROUP BY month
ORDER BY month DESC
LIMIT 12
┌──────month─┬───count()─┐
│ 2017-12-01 │ 662622048 │
│ 2017-11-01 │ 716549049 │
│ 2017-10-01 │ 693602509 │
│ 2017-09-01 │ 686176096 │
│ 2017-08-01 │ 608606033 │
│ 2017-07-01 │ 556639959 │
│ 2017-06-01 │ 487825551 │
└────────────┴───────────┘
7 rows in set. Elapsed: 252.989 sec. Processed 4.41 billion rows, 236.12 GB (17.44 million rows/s., 933.34 MB/s.)
Peak memory usage: 902.94 MiB.在导入历史数据时,我们使用了一条简单的 INSERT INTO SELECT 语句。例如,下面这个查询用时约 20 分钟就导入了 2018 年的全部数据 —— 大约 100 亿条记录,来自 12 万个文件,总大小为 530GB 的压缩 JSON。
INSERT INTO rubygems.downloads_2018
FROM s3Cluster('default', 'https://storage.googleapis.com/clickhouse-rubygems/backfill/2018/**/*.json.gz', '', '')
SETTINGS max_insert_threads = 16, min_insert_block_size_rows = 0, min_insert_block_size_bytes = 2083333333, parallel_distributed_insert_select = 2
0 rows in set. Elapsed: 1317.014 sec. Processed 10.14 billion rows, 562.52 GB (7.70 million rows/s., 427.12 MB/s.)
Peak memory usage: 47.25 GiB.你可能会注意到,我们对该查询设置做了优化:通过参数 parallel_distributed_insert_select = 2 启用并行插入功能,将任务分配到所有节点上,以加快导入速度。想了解更多关于优化类似导入过程的内容,可以参考官方指南《Optimizing for S3 Insert and Read Performance》。
上述方法解决了历史数据的回填问题。而要处理新增文件并持续将其写入 ClickHouse,我们使用了 S3Queue 表引擎。
S3Queue 表引擎支持从 S3(与 GCS 兼容)流式消费数据。当新的日志文件按小时上传到 bucket 后,ClickHouse 会自动检测这些文件,并将内容写入指定的数据表。借助这种能力,用户可以轻松搭建增量数据管道,全程无需编写任何额外代码。
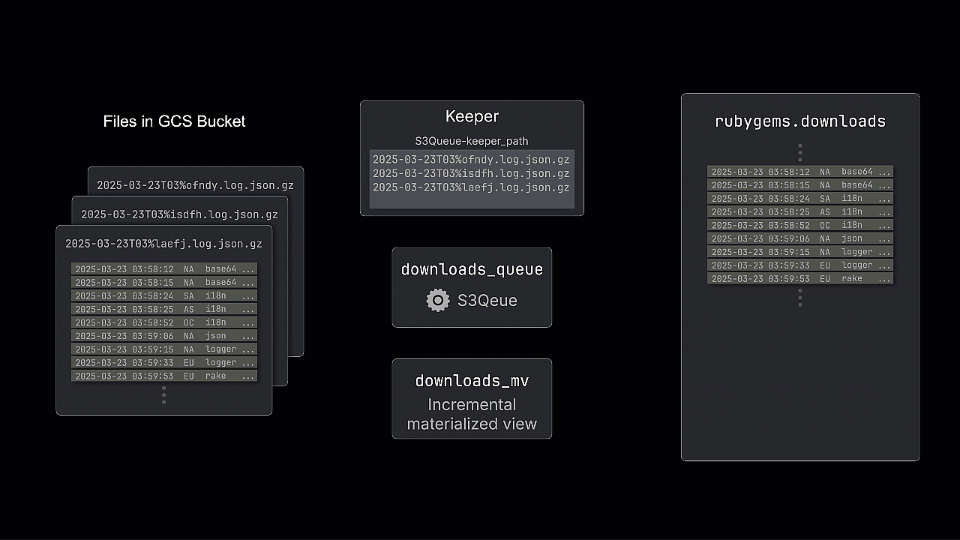
S3Queue 表引擎的运行机制是定期轮询 GCS bucket,追踪其中的文件列表,并将状态信息保存在 ClickHouse Keeper 节点中。每次轮询时,它会将新获取到的文件列表与已有记录进行比对,从而识别出新增的文件。虽然队列表本身并不存储这些数据,但我们可以使用增量物化视图(incremental materialized view)来订阅这些新增记录,并在写入目标表之前对其进行转换。
构建这样一个数据处理管道,仅需两个简单的 DDL 命令:第一个用于创建 S3Queue 表,第二个用于创建一个订阅该队列变化的增量物化视图,并将结果写入主下载表中。
CREATE TABLE rubygems.downloads_queue_2025_04_01
(
`timestamp` DateTime,
`request_path` String,
`request_query` String,
...
`gem` String,
`version` String,
`platform` String
)
ENGINE = S3Queue('https://storage.googleapis.com/clickhouse-rubygems/incremental/**/*.json.gz', '', '[HIDDEN]', 'JSONEachRow', 'gzip')
SETTINGS mode = 'ordered', s3queue_polling_min_timeout_ms='6000', s3queue_polling_max_timeout_ms='9000', s3queue_buckets = 30, s3queue_processing_threads_num = 10;CREATE MATERIALIZED VIEW rubygems.downloads_2025_04_01_mv TO rubygems.downloads
AS SELECT *
FROM rubygems.downloads_queue_2025_04_01一些关键点需要说明:
-
这些日志文件在命名上没有明确的时间顺序(尤其在同一小时内)。因此我们选择使用 S3Queue 的无序模式(unordered mode)。在这种模式下,ClickHouse 会通过 Keeper 跟踪所有文件,而不是依赖文件名的顺序。
相比之下,有序模式(ordered mode)需要确保所有文件按字典序顺序上传。这种模式会维护一个文件名游标,并以此判断哪些文件是新增的。但如果文件顺序错乱,就可能漏掉部分数据。而 Ruby Central 当前的导出流程并不支持这种顺序保证 —— 所以我们最终决定采用无序模式。
虽然有序模式更高效(只需追踪上一个处理的文件),但它对上传流程提出了更高要求。考虑到我们要处理接近 2000 亿行数据,Ruby Central 团队设计了一个完全并行的导出机制 —— 每小时从各个 Fastly 区域生成的日志文件会各自触发一个 Lambda 函数进行处理。这些 Lambda 函数是并发执行的,没有办法也没必要去做顺序控制。
鉴于这些文件存在乱序传输的可能性,我们最终使用了 S3Queue 的无序模式进行消费。
-
我们每天会新建一个 S3Queue 表和一个对应的物化视图,并清理掉两天前的旧队列和视图。这样可以将每个队列需要追踪的文件数量控制在 1000 以内,并提供 48 小时的宽限期,以容纳延迟到达的文件。
-
我们还对默认参数做了优化,包括延长最小和最大轮询时间,将最大追踪文件数上限提高到 2000。
-
文件路径模式 **/*.json.gz 允许递归处理所有子目录中的文件。
-
当前我们在 sql.clickhouse.com 的部署环境由三个节点组成,每个节点配备 60 个 vCPU。参数 s3queue_processing_threads_num 控制每台服务器的并发处理线程数。若使用有序模式,还需配置 s3queue_buckets,推荐设置为副本数(3)乘以每个副本的处理线程数(10),以获得最佳性能。
数据流正式开启后,下载记录开始源源不断地写入系统。下面是一个示例查询,展示如何分析 bundler gem 每小时的下载情况:
SELECT
toStartOfHour(timestamp) AS hour,
count()
FROM rubygems.downloads
WHERE gem = 'bundler' AND timestamp > today() - INTERVAL 1 WEEK
GROUP BY hour
ORDER BY hour ASC自 2017 年以来的全部下载数据现已加载完毕,整个数据集总行数达到约 1800 亿。原始数据来自约 9.5 TB 的 Gzipped JSON(解压后约 160 TB),在 ClickHouse 中压缩后体积控制在 5 TB 以内。
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes)) AS total_size
FROM system.columns
WHERE (database = 'rubygems') AND (`table` = 'downloads')
GROUP BY `table`
ORDER BY sum(data_compressed_bytes) DESC每日聚合下载量
我们的第二个数据集托管在 GitHub 上,并大约每周更新一次。
为了导入这部分历史数据,我们首先克隆了对应的代码仓库,然后使用 clickhouse-local 工具运行如下命令,对 CSV 文件进行解析并写入我们的 Cloud 实例中。
clickhouse local --query "SELECT replaceOne( _file, '.csv','')::Date as date, * FROM file('/data/rubygems/gem-daily-downloads/**/*.csv') FORMAT Native" | clickhouse client --host sql-clickhouse.clickhouse.com --secure --password --query "INSERT INTO rubygems.daily_downloads FORMAT Native"后续的增量更新通过一个非常简单的 bash 脚本实现。
这个脚本会先从 ClickHouse 查询当前数据集中已加载的最新日期,然后从 RubyGems 的 GitHub 仓库中拉取缺失的 CSV 文件。它会按日期循环处理,检测当天的数据文件是否存在,如果存在,则使用 ClickHouse 原生命令进行导入。整个流程无需依赖任何外部调度系统,逻辑也非常轻量。
与通过 GCS 和 S3Queue 实现实时流式导入的下载日志不同,这份数据是经过预聚合的,每周更新一次,数据量也更小,因此非常适合采用“拉取 + 加载”的方式进行维护。借助 ClickHouse 对远程文件的就地读取与导入能力,这个脚本在保持处理效率的同时,也确保了 sql.clickhouse.com 上公共数据集的持续更新。
我们将该脚本部署在 Google Cloud Run 上运行。
截至 2025 年 4 月,该数据集的总行数约为 6 亿行。
每周数据导出
每周数据导出同样托管在 GitHub 上,并采用全量更新的方式 —— 每次都会替换所有文件。每个数据集的所有内容都会集中在一个目录中,例如 Ruby Gems 的完整包列表和相关元数据。
这种结构让数据处理变得更加简单。我们使用可刷新视图(refreshable materialized view)来定期执行导入查询,并将结果写入目标表。这种方式既适用于初次加载,也能支持后续的定期更新。
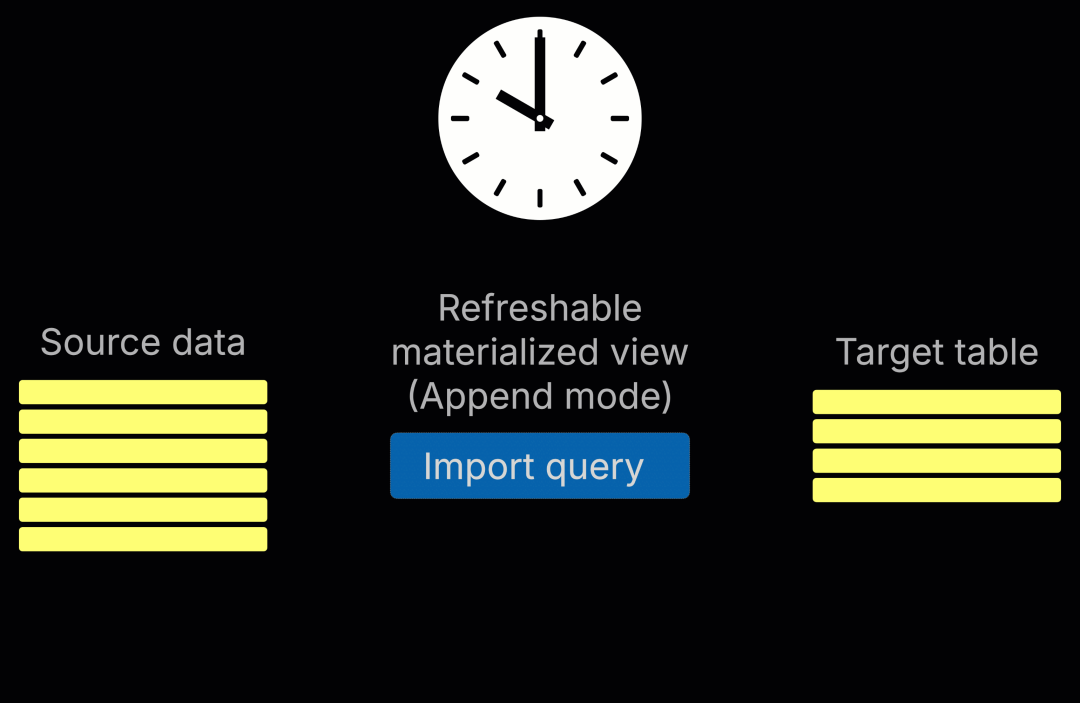
例如,下面这个可刷新视图每周运行一次,通过 ClickHouse 的 url 函数读取 GitHub 上 Ruby Gems 的包文件:
CREATE MATERIALIZED VIEW rubygems.rubygems_mv
REFRESH EVERY 1 WEEK APPEND TO rubygems.rubygems
(
`id` UInt32,
`name` String,
`created_at` DateTime64(6),
`updated_at` DateTime64(6),
`indexed` LowCardinality(String),
`organization_id` LowCardinality(String)
)
AS SELECT *
FROM url('https://raw.githubusercontent.com/segiddins/rubygems-org-db-dumps/refs/heads/main/tables/rubygems/part_{0..100}.csv', 'CSVWithNames')该视图会将数据写入 rubygems.rubygems 表中:
CREATE TABLE rubygems.rubygems
(
`id` UInt32,
`name` String,
`created_at` DateTime64(6),
`updated_at` DateTime64(6),
`indexed` LowCardinality(String),
`organization_id` LowCardinality(String)
)
ENGINE = ReplacingMergeTree
ORDER BY (name, id)如果你希望将这份数据或其他每周导出表加载到自己的 ClickHouse 实例中,只需创建目标表,并运行以下命令即可:INSERT INTO SELECT * FROM
url('https://raw.githubusercontent.com/segiddins/rubygems-org-db-dumps/refs/heads/main/tables/rubygems/part_{0..100}.csv', 'CSVWithNames')。
其他表的结构定义可以参考 sql.clickhouse.com 上提供的查询示例。
关于这个视图的配置和排序键,有几个需要特别注意的点:
该视图使用了 APPEND 子句,意味着所有导入数据都会追加写入 rubygems.rubygems 表,而不会替换原有内容。
这种追加策略会带来重复数据的问题。为了解决这个问题,我们采用了 ReplacingMergeTree 表引擎,它会根据排序键中的唯一字段(如 name 和 id)自动去重。这个去重是最终一致的,通过 ClickHouse 的后台合并机制实现。
你可以在查询时使用 FINAL 关键字,确保结果中不包含重复数据;或者在查询中按排序键进行聚合。由于该表的数据量并不大(仅为几百万行),这些处理带来的开销几乎可以忽略。
这些表在 ClickHouse 中属于轻量级的元数据表,非常适合与其他数据集联动分析。我们将在下文展示如何将它们用于数据关联和生态洞察。
SELECT
name,
formatReadableQuantity(total_rows) AS total_rows,
formatReadableSize(total_bytes_uncompressed) AS total_size
FROM system.tables
WHERE (database = 'rubygems') AND (engine LIKE '%ReplacingMergeTree')物化视图
借鉴 ClickPy 的经验,我们也希望通过构建增量物化视图来加速常见查询。
简单来说,增量物化视图就是一条在数据插入时自动触发的查询语句。
需要理解的一点是,物化视图本身并不保存任何数据。它只是对新插入的数据执行一次查询,并将处理结果写入到另一个“目标表”中。
更进一步地说,这个查询过程可以对原始数据进行聚合压缩,将多行合并为更小的结果集,从而加快后续在目标表上的查询速度。这种设计思路的核心是:将原本在查询阶段执行的计算,提前到了写入阶段完成。
我们可以通过原始下载日志中的数据,重新构建每日聚合下载量的物化视图。
这样做的主要原因在于,已有的聚合日志只是估算数据,而且每周才更新一次;而使用物化视图计算出来的结果则更加精确,并且能做到每小时更新。这也是一个非常直观易懂的示例。
CREATE MATERIALIZED VIEW rubygems.downloads_per_day_mv TO rubygems.downloads_per_day
AS SELECT
toDate(timestamp) AS date,
gem,
count() AS count
FROM rubygems.downloads
GROUP BY
date,
gem该视图在每次有新数据写入 downloads 表时,都会实时对数据块执行聚合计算:
SELECT
toDate(timestamp) AS date,
gem,
count() AS count
FROM rubygems.downloads
GROUP BY
date,
gem处理完成后的聚合结果会写入名为 rubygems.downloads_per_day 的目标表中,而该表采用了特殊的引擎配置:
CREATE TABLE rubygems.downloads_per_day
(
`date` Date,
`gem` String,
`count` UInt64
)
ENGINE = SummingMergeTree
ORDER BY (gem, date)这个表使用的是 SummingMergeTree 引擎,它会将所有具有相同排序键(这里是 gem 和 date)的记录自动合并为一行,并对其中所有数值字段执行求和操作。具有相同项目标识的记录会在后台异步合并,从而形成每日下载量的累加结果。这种特性使得目标表可以在数据持续写入时自动完成增量更新。
举个例子,假如我们想查看 bundler gem 的每日下载量。使用原始的 downloads 表执行查询:
SELECT toDate(timestamp) as date, count() AS count
FROM rubygems.downloads WHERE gem = 'bundler'
GROUP BY gem, date ORDER BY date ASC大多数情况下,这条查询大约需要 7 到 10 秒才能返回结果。而如果改为从 downloads_per_day 表中查询:
SELECT date, sum(count) AS count
FROM rubygems.downloads_per_day WHERE gem = 'bundler'
GROUP BY gem, date ORDER BY date ASC几乎是秒级响应!这就是增量物化视图的强大之处 —— 将计算工作从查询阶段前置到了写入阶段。
除了这个视图之外,我们还维护了其他几个常用的物化视图,并已在下方的查询中使用。未来,我们还将根据实际需求或社区反馈,持续扩展更多视图支持。
示例查询
为了帮助大家更轻松地使用数据集,我们整理了一些典型查询示例。这些查询大多参考了 ClickPy 中的使用方式。你可以尝试下方的任意语句,或者直接访问 sql.clickhouse.com 查看完整的查询目录。
最受欢迎的 Gems
通过我们前面构建的物化视图即可快速查询:
SELECT
gem,
sum(count) AS total_downloads
FROM rubygems.downloads_per_day
GROUP BY gem
ORDER BY total_downloads DESC
LIMIT 5新兴 Gems
这个查询基于 gems_downloads_max_min 物化视图,该视图记录了每个 gem 被下载的最早和最晚日期。
WITH (
SELECT max(max_date)
FROM rubygems.gems_downloads_max_min
) AS max_date
SELECT
gem,
sum(count) AS c
FROM rubygems.downloads_per_day
WHERE gem IN (
SELECT name
FROM rubygems.gems_downloads_max_min
GROUP BY name
HAVING min(min_date) >= (max_date - toIntervalMonth(3))
)
GROUP BY gem
ORDER BY c DESC
LIMIT 7查看 gem 的下载趋势
如果你只需要按天统计的粒度,可以使用 downloads_per_day 视图。例如查看 bundler gem:
SELECT
date,
sum(count) AS total_downloads
FROM rubygems.downloads_per_day
WHERE (gem = 'bundler')
GROUP BY date
ORDER BY date ASC如果你希望进行更细粒度的分析,也可以使用原始下载事件表。此时建议加上日期范围的过滤条件以提升效率。
SELECT
toStartOfHour(timestamp) as hour,
count() as total_downloads
FROM rubygems.downloads
WHERE (gem = 'bundler') AND timestamp > now() - INTERVAL 2 DAYS
GROUP BY hour
ORDER BY hour ASC按 Ruby 版本统计下载趋势
以 bundler gem 为例:
--Daily gem downloads by version over time. NOTE - We recommended applying a time range (weeks max) to avoid quota limits.
WITH top_versions AS
(
SELECT user_agent.ruby
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03') AND (gem = 'bundler')
GROUP BY user_agent.ruby
ORDER BY count() DESC
LIMIT 10
)
SELECT
user_agent.ruby AS ruby_version,
toStartOfHour(timestamp) AS hour,
count() AS downloads
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03') AND (gem = 'bundler') AND user_agent.ruby IN top_versions
GROUP BY
hour,
ruby_version
ORDER BY
hour DESC,
ruby_version ASC我们计划在后续提供相应的物化视图来加速这类查询。
按操作系统平台统计下载趋势
以 bundler gem 为例:
WITH systems AS
(
SELECT user_agent.platform.os
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03')AND (gem = 'bundler') AND (user_agent.platform.os NOT IN ('', 'unknown'))
GROUP BY user_agent.platform.os
ORDER BY count() DESC
LIMIT 5
)
SELECT
user_agent.platform.os AS name,
toStartOfHour(timestamp) AS hour,
count() AS total_downloads
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03') AND (gem = 'bundler') AND (user_agent.platform.os IN (systems))
GROUP BY
name,
hour
ORDER BY
hour ASC,
name DESC这类查询在未来也会配套物化视图以进一步提升性能。
查询最新版本的 Gem 下载量(使用字典机制)
有些查询涉及多个表的联动,尤其是每周导出的元数据表,在处理这类复杂查询时非常有帮助。
此外,我们还提供了若干内存字典结构,用于加速查询中的键值查找。比如,下面这两个字典就可以实现 gem 名称与其 ID 的互相映射:
CREATE DICTIONARY rubygems.name_to_id
(
`name` String,
`id` UInt64
)
PRIMARY KEY name
SOURCE(CLICKHOUSE(QUERY 'SELECT name, id FROM rubygems.rubygems'))
LIFETIME(MIN 86400 MAX 90000)
LAYOUT(COMPLEX_KEY_HASHED())
CREATE DICTIONARY rubygems.id_to_name
(
`id` UInt64,
`name` String
)
PRIMARY KEY id
SOURCE(CLICKHOUSE(QUERY 'SELECT id, name FROM rubygems.rubygems'))
LIFETIME(MIN 86400 MAX 90000)
LAYOUT(FLAT())要了解更多关于字典的用法,推荐查看官方文档中的《Dictionary》使用指南。
例如,想要查找 bundler gem 的 ID:
SELECT dictGet(rubygems.name_to_id, 'id', 'bundler') AS gem_id如果想反过来根据 ID(如 19969)查找对应的名称:
SELECT dictGet(rubygems.id_to_name, 'name', 19969) AS gem_name字典在每周数据集中特别有用,因为有些表中并不包含 gem 的名称字段。例如,我们可以通过 versions 表查找某个 gem 的最新版本,同时借助前面介绍的字典获取对应的 gem ID:
SELECT canonical_number
FROM rubygems.versions
WHERE rubygem_id = dictGet(rubygems.name_to_id, 'id', 'bundler')
ORDER BY arrayMap(x -> toUInt8OrDefault(x, 0), splitByChar('.', canonical_number)) DESC
LIMIT 1然后我们可以将这些信息与下载日志结合起来,统计该 gem 最新版本的每周下载量。
WITH (
SELECT canonical_number
FROM rubygems.versions
WHERE rubygem_id = dictGet(rubygems.name_to_id, 'id', 'bundler')
ORDER BY arrayMap(x -> toUInt8OrDefault(x, 0), splitByChar('.', canonical_number)) DESC
LIMIT 1
) AS latest_version
SELECT
toStartOfWeek(timestamp) AS week,
count() AS downloads
FROM rubygems.downloads
WHERE (gem = 'bundler') AND (version = latest_version)
GROUP BY week
ORDER BY week ASC总结与未来展望
我们对 Ruby Gem 的分析才刚刚起步,未来还有很多新内容即将上线。
接下来,我们将继续增加物化视图的覆盖范围,并对 ClickPy 的 UI 进行改造,以支持 Ruby 数据集,让开发者可以通过交互式网页,轻松探索 gem 的使用趋势。ClickGems,这个名字不错吧?
在那之前,研究者、维护者以及所有对 Ruby 感兴趣的开发者,都可以访问 sql.clickhouse.com 自由查询数据,支持原始下载日志和每日聚合统计两类数据集。
衷心感谢 Marty、Samuel,以及整个 Ruby Central 社区的合作、支持与鼓励,正是你们的努力,让这一切得以实现。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









