







一.mrjob实现WordCount
# -*- coding: utf-8 -*-
# @Time : 2019/12/1 9:45
# @Author :
from mrjob.job import MRJob
class MRWordFrequencyCount(MRJob):
def mapper(self, _, line):
yield "chars", len(line)
yield "words", len(line.split())
yield "lines", 1
def reducer(self, key, values):
yield key, sum(values)
if __name__ == '__main__':
MRWordFrequencyCount.run()
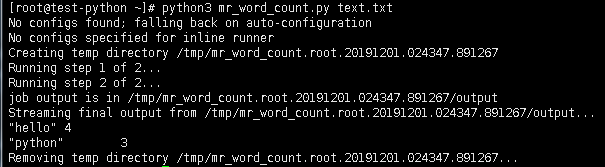
1.本地测试
python3 mr_word_count.py text.txt
2.提交job到Hadoop集群
# 确保text.txt文件已经存在Hadoop集群中
hadoop fs -ls /
hadoop fs -cat /text.txt
# 删除之前生成的output文件夹
hadoop fs -rm -r /output
# 提交job
python3 mr_word_count.py -r hadoop hdfs:///text.txt -o hdfs:///output
3.可能会遇到的问题
1.上传文件到Hadoop异常
could only be replicated to 0 nodes instead of minReplication (=1)
jps 发现DataNode没有起来
原因:
可能是多次运行hadoop namenode -format 格式化namenode引起的clusterIDid不一致
解决方法:
修改dfs/data/current/VERSION 中的clusterID值为dfs/name/current/VERSION中的值
2.Retrying connect to server: 0.0.0.0/0.0.0.0:8032
可能原因:
1.服务器性能不够
2.yarn-site.xml配置有问题
集群ha可以参考:https://blog.csdn.net/Cocktail_py/article/details/102631199
3.subprocess failed with code 127
参考: https://blog.csdn.net/Saltwind/article/details/82913477
二.mrjob 实现 topN统计
# -*- coding: utf-8 -*-
# @Time : 2019/12/1 9:45
# @Author :
from mrjob.job import MRJob, MRStep
import heapq
class TopNWords(MRJob):
def mapper(self, _, line):
if line.strip() != "":
for word in line.strip().split():
yield word, 1
# 介于mapper和reducer之间,用于临时的将mapper输出的数据进行统计
def combiner(self, word, counts):
yield word, sum(counts)
def reducer_sum(self, word, counts):
yield None, (sum(counts), word)
# 利用heapq将数据进行排序,将最大的2个取出
def top_n_reducer(self, _, word_cnts):
for cnt, word in heapq.nlargest(2, word_cnts):
yield word, cnt
# 实现steps方法用于指定自定义的mapper,comnbiner和reducer方法
# MRStep指定执行顺序
def steps(self):
return [
MRStep(mapper=self.mapper,
combiner=self.combiner,
reducer=self.reducer_sum),
MRStep(reducer=self.top_n_reducer)
]
def main():
TopNWords.run()
if __name__ == '__main__':
main()
















 1891
1891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











