






01 概述
- 本文档是利用TensorRT-LLM(early access)对 CodeFuse-CodeLlama-34B 进行int4量化的实践(注:TensorRT-LLM(GA) 已发布)。Codefuse是由蚂蚁集团开发的专门用于支持整个软件开发生命周期的大型代码语言模型(Code LLMs),涵盖设计、需求、编码、测试、部署、运维等关键阶段。致力于打造创新的解决方案,让软件开发者们在研发的过程中如丝般顺滑。CodeFuse-CodeLlama-34B的是在CodeLlama-34b-Python的基础上,通过高质量指令数据集和多任务范式微调而成的模型,在HumanEval Benchmarks的Python Pass@1 取得了74.4%(greedy decoding)的开源SOTA成绩。下面会展示我们是如何一步一步地完成TensorRT-LLM的安装、量化以及测试。
02安装
构建容器
如果网络能够触达以下url
- nvcr.io/nvidia/pytorch:23.07-py3
- https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.0.1/tars/TensorRT-9.0.1.4.Linux.x86_64-gnu.cuda-12.2.tar.gz
- https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.0.1/tars/polygraphy-0.48.1-py2.py3-none-any.whl
直接使用如下命令进行容器构建
docker build -t tensorrt_llm -f docker/Dockerfile.dev .但诸如业务生产环境,会出于安全考虑无法直接触达上述url,在这种情况下就需要自己构建镜像。我们是在一个py3.8的pytorch基础镜像上构建tensorrt-llm的运行镜像,在构建过程中,需要着重注意以下要点
- 操作系统:最好是ubuntu系统
- gcc版本:我们使用的gcc版本 GCC 10 + GLIBC 2.32
- TensorRT路径:需要将TensorRT-9.0.1.4.Linux.x86_64-gnu.cuda-12.2.tar.gz手动传入生产环境并解压至根目录
- polygraphy:手动传入polygraphy-0.48.1-py2.py3-none-any.whl并安装
- NCCL路径
- cuda/cudnn 路径:在cmake中,如果系统路径没有cuda/cudnn路径,会出现编译错误
从源码构建wheel
当容器构建好后,参考README.md中“build from source”就可以构建并安装tensorrt-llm,请注意build_wheel.py 的如下参数
- trt_root:tensorrt路径
- nccl_root:nccl路径
- clean:是否重新构建wheel文件
- cuda_architectures:支持的GPU,我们需要评测 80/86/89
- cpp_only:我们需要python runtime,所以不触发cpp_only
- install: 在构建wheel后进行安装
综上,我们使用的命令如下
python scripts/build_wheel.py --clean --install --trt_root {trt location} --nccl_root {nccl location} --cuda_architectures "80-real;86-real;89-real" 2>&1 | tee build_whl.log这样,我们就将TensorRT-llm安装在了环境中。
CodeFuse-CodeLlama-34B int4量化
这里我们使用GPTQ技术对模型进行int4量化。GPTQ是对逐层量化范式经典框架 OBS(Optimal Brain Srugeon)的高效实现,能够利用单张A100-80G在4小时内完成OPT-175B模型的量化,并且可以获得较好的准确率。另外,我们这里采用了静态量化方式,即通过矫正数据离线地进行量化,得到诸如缩放因子和零点的量化参数,在推理时不再进行量化参数的更新。与之对应的是动态量化,会在模型推理的同时根据输入进行量化参数的调整。最后,我们这里进行的是int4-weights-only量化,即只对权重进行量化而不对层输入进行量化,即W4A16量化。
int4-weights-only量化
这里我们利用开源工具AutoGPTQ进行量化,工具超参数如下;
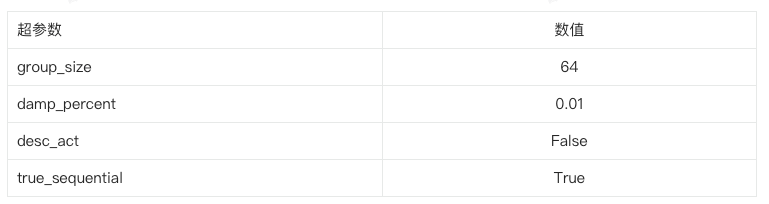
静态低bit量化算法会出现对于矫正数据集过拟合情况,引起该现象的的本质原因是矫正数据集和模型推理时的数据分布不一致。这里,我们通过将模型生成数据作为矫正集,达到数据分布对齐的目的。具体地,对于微调模型,首先通过self-instruct的方式或者抽取训练数据中的Question做为引导方式,其次再利用模型生成生成Answer,将Question和Answer拼接起来做为矫正数据;最终在HumanEval Benchmarks的Python Pass@1 取得了73.8%的准确率。

构建TensorRT引擎
通过AutoGPTQ可以得到safetensors格式的int4量化模型,我们的目标是构建单卡TensorRT引擎,同时保证Activation是fp16的数据精度。通过examples/llama/build.py进行TensorRT引擎构建,需要关注如下参数
- dtype:设置为fp16
- use_gpt_attention_plugin:设置为fp16,构建引擎是利用gpt attention plugin并且数据精度为fp16
- use_gemm_plugin: 设置为fp16,构建引擎是利用gemm_plugin并且数据精度为fp16
- use_weight_only: 触发weight only量化
- weight_only_precision:设置为int4,需要构建W4A16的量化模型引擎
- per_group:gptq为group-wise量化,所以需要触发per-group
- max_batch_size: TensorRT引擎最大batch size
- max_input_len:TensorRT引擎最大输入长度
- max_output_len:TensorRT引擎最大输出长度
综上,我们在单卡A10/A100/L40S 上构建TensorRT引擎的命令如下
python build.py --model_dir "${model_dir}" \
--quant_safetensors_path "${quant_safetensors_path}" \
--dtype float16 \
--use_gpt_attention_plugin float16 \
--use_gemm_plugin float16 \
--use_weight_only \
--weight_only_precision int4 \
--max_batch_size 1 \
--max_input_len 2048 \
--max_output_len 1024 \
--per_group \
--output_dir "${engin_dir}" 2>&1 | tee dev_build.log03 测试
性能
下面,我们主要测试了不同的输入输出长度和量化精度情况下,TensorRT-LLM在A10/A100/L40S上的推理速度的表现。可以看到,在A100上,TensorRT-LLM的int4相对fp16,最高能够带来2.4的加速(Speedup),相对int8最高也能带来1.7的加速
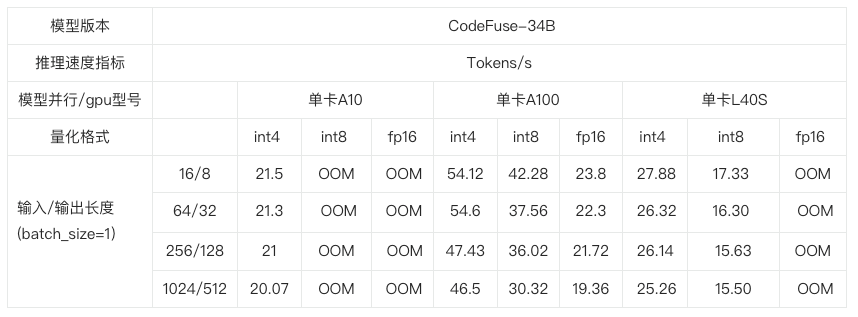
备注:
- L40S是通过“docker/Dockerfile.dev”构建的容器进行的测试
- A10/A100是在自建容器中进行
显存占用和结果测试
我们测量了模型加载后占用的显存占用情况,以及输入2048/1024 tokens并输出1024/2048 tokens时的显存使用情况;同时我们也测试了量化前后的精度情况,如下表所示

可见,4bit量化后,显存占用大幅缩小,在一张A10(24GB显存)上就能部署34B的大模型,同时精度相比FP16损失小于<1%,具备非常好的实用性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









