






 CodeFuse-VLM是一个开源的多模态多任务微调框架,支持多种视觉和语言模型。CodeFuse-VLM-14B基于Qwen-VL和Qwen-14B,性能超越LLAVA-1.5和Qwen-VL,尤其在MMBenchmark上展示了出色的表现。该框架通过预训练和指令微调解决多任务问题,提升了开发效率。
CodeFuse-VLM是一个开源的多模态多任务微调框架,支持多种视觉和语言模型。CodeFuse-VLM-14B基于Qwen-VL和Qwen-14B,性能超越LLAVA-1.5和Qwen-VL,尤其在MMBenchmark上展示了出色的表现。该框架通过预训练和指令微调解决多任务问题,提升了开发效率。

CodeFuse-MFT-VLM 项目地址:
https://github.com/codefuse-ai/CodeFuse-MFT-VLM
CodeFuse-VLM-14B 模型地址:
CodeFuse-VLM-14B
CodeFuse-VLM框架简介
随着huggingface开源社区的不断更新,会有更多的vision encoder 和 LLM 底座发布,这些vision encoder 和 LLM底座都有各自的强项,例如 code-llama 适合生成代码类任务,但是不适合生成中文类的任务,因此用户常常需要根据vision encoder和LLM的特长来搭建自己的多模态大语言模型。针对多模态大语言模型种类繁多的落地场景,我们搭建了CodeFuse-VLM 框架,支持多种视觉模型和语言大模型,使得MFT-VLM可以适应不同种类的任务。
CodeFuse-VLM 支持多种视觉达模型:CLIP,CLIP-336px,Chinese Clip,Chinese Clip-336px,Qwen Clip;多种语言达模型:Vicuna-7B,Vicunam-13B,LLAMA-2-7B,Qwen-7B,Qwen-14B。用户可以根据自己的需求,通过配置文件的方式搭配VL-MFTCoder中不同的Vision Encoder 和 LLM,使用同一套框架去适配的不同的模型,大大提高了开发效率
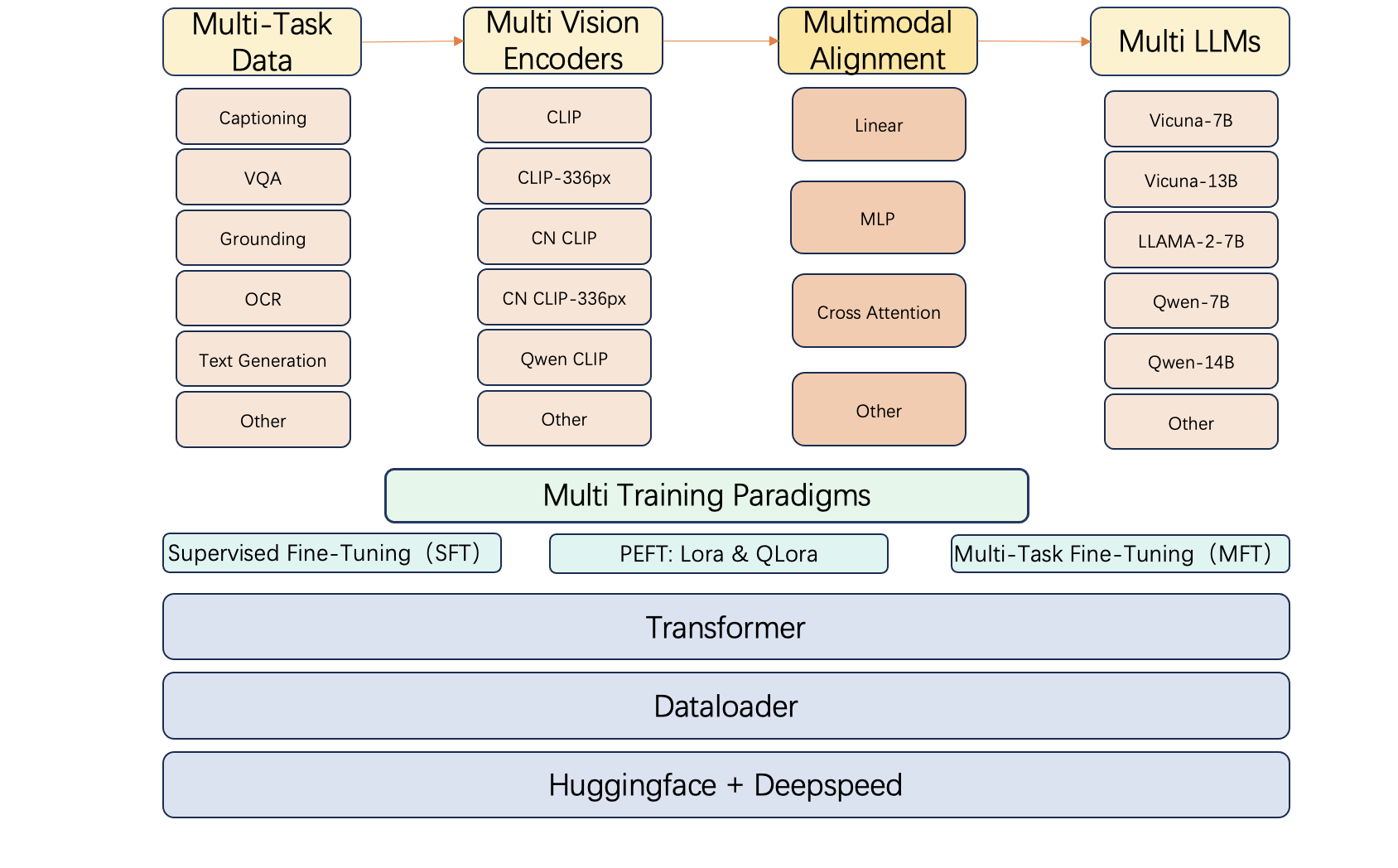
我们在2024年1月开源了多模态多任务微调框架——CodeFuse-VLM。在CodeFuse多任务微调的基础上,CodeFuse-VLM可以实现在多个模态,多个任务上同时并行地进行微调。通过结合多种损失函数,我们有效地解决了多任务学习中常见的任务间数据量不平衡、难易不一和收敛速度不一致等挑战。此外,CodeFuse-VLM框架具备高效训练特征,支持高效的PEFT微调,能有效提升微调训练速度并降低对资源的需求。
 https://cloud.video.taobao.com/play/u/23956347/p/1/d/ld/e/6/t/1/446458089308.mp4?auth_key=YXBwX2tleT04MDAwMDAwMTMmYXV0aF9pbmZvPXsidGltZXN0YW1wRW5jcnlwdGVkIjoiZDcxNGY0MjE3MDZmY2ZiYWY4ZWEyY2ExMGQyZGUxMDMifSZkdXJhdGlvbj0mdGltZXN0YW1wPTE3MDcxMjE2OTc=
https://cloud.video.taobao.com/play/u/23956347/p/1/d/ld/e/6/t/1/446458089308.mp4?auth_key=YXBwX2tleT04MDAwMDAwMTMmYXV0aF9pbmZvPXsidGltZXN0YW1wRW5jcnlwdGVkIjoiZDcxNGY0MjE3MDZmY2ZiYWY4ZWEyY2ExMGQyZGUxMDMifSZkdXJhdGlvbj0mdGltZXN0YW1wPTE3MDcxMjE2OTc=
CodeFuse-VLM-14B模型
我们基于Qwen-VL的视觉编码器和Qwen-14B 大语言模型,在CodeFuse-VLM框架下训练了CodeFuse-VLM-14B 模型,在多个通用和代码任务上的性能超过 LLAVA-1.5 和 Qwen-VL。
预训练数据
参考了Qwen-VL的Multi-Task Pretraining数据集,我们准备使用多种数据对齐Qwen-VL-14B的模态。在预训练当中我们使用多任务训练的方式,每一个数据集都是一个训练任务任务。
| dataset | type | number of samples |
| synthdog-en | OCR | 50w |
| synthdog-zh | OCR | 50w |
| cc3m(downsampled) | Image Caption | 55w |
| SBU | Image Caption | 85w |
| Visual Genome VQA | VQA | 50w |
| Visual Genome Region descriptions | Ref Grouding | 50w |
| Visual Genome objects | Caption With Grouding | 50w |
| OCR_VQA | OCR and VQA | 50w |
我们使用预训练数据集训练模态对齐的cross attention 模块,可以执行以下代码来启动模型预训练
sh scripts/pretrain_multinode.sh指令微调数据
我们使用了 LLAVA-1.5 的指令微调数据,总共65w样本,LLAVA的指令微调数据集包含复杂图片的推理分析,对LLM理解视觉特征很有帮助。

指令微调数据构成如下,在视觉指令微调当中我们使用多任务训练的方式,每一个数据集都是一个训练任务任务。
| dataset | type | number of samples |
| OCR_VQA | OCR and VQA | 7w |
| GQA | Image Caption | 8w |
| Visual Genome | Ref Grouding and Caption With Grouding | 10w |
| COCO | Detailed Description and Complex Reasoning | 37w |
| Text-VQA | Detailed Description and Complex Reasoning | 3w |
我们使用指令微调数据训练CodeFuse-VLM-14B中的Qwen-14B大语言模型,可以执行以下代码来启动模型的指令微调
sh scripts/finetune_multinode.sh模型性能
我们训练的CodeFuse-VLM-14B 模型在多个benchmark上的表现超过Qwen-VL和LLAVA-1.5, 具体得分参考下面的图表。
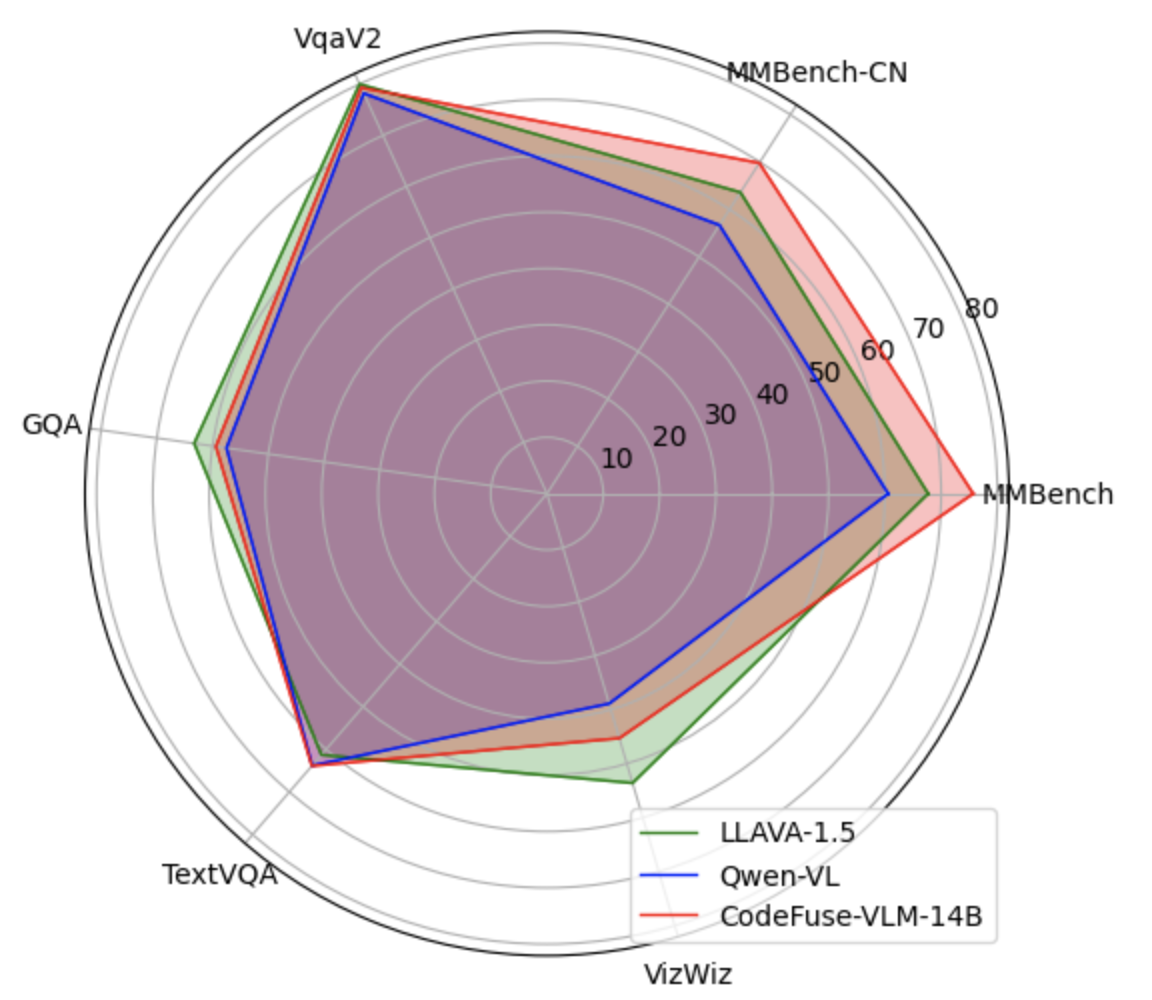
| Benchmark | LLAVA-1.5 | Qwen-VL | CodeFuse-VLM-14B |
| MM_Bench | 67.7 | 60.6 | 75.7 |
| MM_Bench_CN | 63.6 | 56.7 | 69.8 |
| VqaV2 | 80.0 | 78.2 | 79.3 |
| GQA | 63.3 | 57.5 | 59.4 |
| TextVqa | 61.3 | 63.8 | 63.9 |
| VizWiz | 53.6 | 35.25 | 45.3 |
| Sketch2Code | - | 90.7 | 94.4 |
我们的CodeFuse-VLM-14B 在MMBenchmark的中英文榜单分别取得第13/21名的排名,高于Qwen-VL第29/36名的排名
MMBench
产品图片
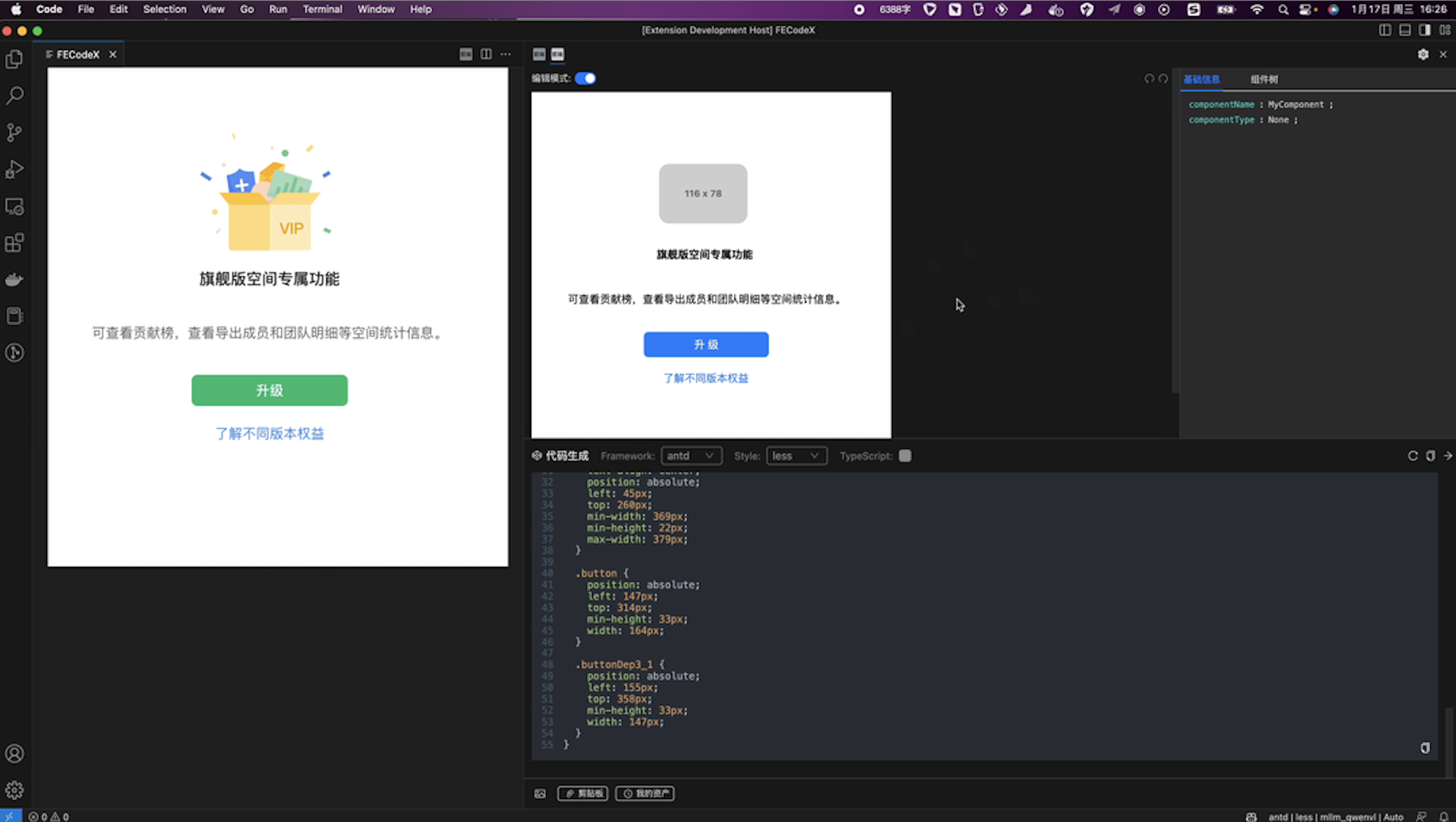
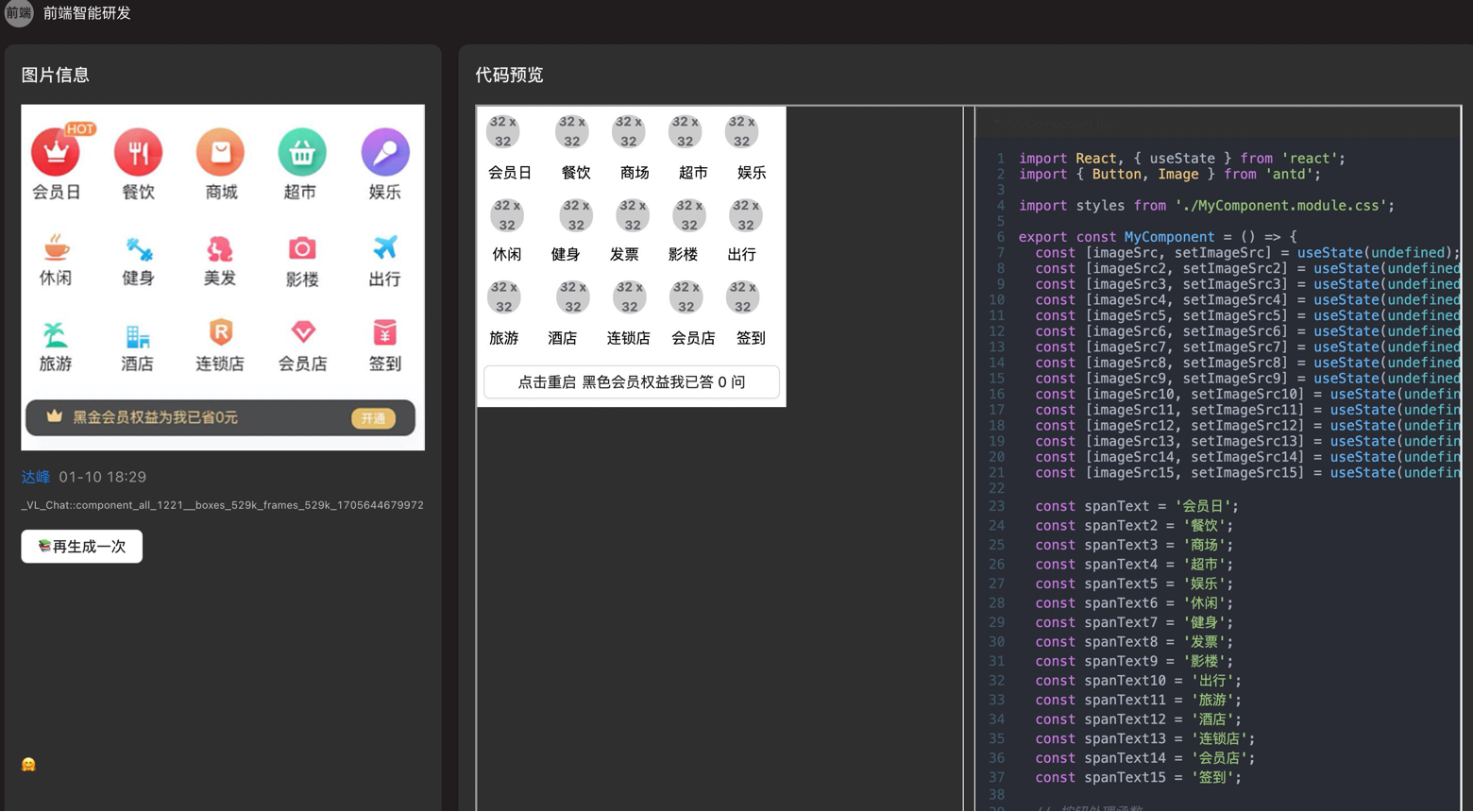
我们通过CodeFuse-VLM 在蚂蚁内部训练了网页图片到前端代码的多模态大模型,并把大模型集成到内部的Visual Studio Code插件中。如下面两站图所示,左边的图片是网页原图,右边的图片是大模型生成的前端代码渲染出的图片,多模态大模型生成的前端代码渲染出的图片对网页原图有很高的还原性,很大地提高了前端工程师开发的效率。

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









