






**CodeFuse-13B概述**
CodeFuse是蚂蚁集团自研的代码生成模型,能提供智能建议和实时支持,帮助开发者自动生成代码、注释、测试用例等,提高研发效率。CodeFuse项目起于2023年初,目前发布了系列模型15个,数据集4个,以及数个相关工具链。
CodeFuse-13B是该项目的早期预训练版本,完成于2023年6月,并于9月开源。论文《CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model》同期发表,并被ICSE-SEIP'24收录。该论文针对蚂蚁集团的现实应用场景,详细介绍了CodeFuse-13B预训练模型的数据准备和训练过程,揭秘了CodeFuse是如何成为一款能够同时处理英文和中文提示的高效预训练代码大型语言模型(LLM)。论文还对CodeFuse在代码生成、翻译、注释和测试用例生成等应用场景中的性能进行了评估。CodeFuse-13B在蚂蚁集团内广泛应用,并通过不断引入新技术,取得了持续的性能改进。

论文围绕CodeFuse-13B训练过程展开,包括:
1. 数据收集:CodeFuse的预训练数据包括196TB的代码、1.75TB的中文原始数据和1.7TB的英文原始数据,总计200TB。这一庞大的数据集被标记为8000亿个标记。
2. 数据处理:数据处理涉及各种步骤,如数据清洗、去毒、去重和重新采样,以确保训练数据的质量和有效性。
3. 程序特征分析:进行程序特征分析以从收集的代码中提取程序特征,包括语法正确性和清洁度评分。这种分析有助于确保预训练数据的高质量,并提取代码语义以实现程序理解。
4. 预训练:使用蚂蚁集团的常用技术堆栈,开发了CodeFuse以稳定地预训练具有130亿参数的大规模模型1。
5. 监督式微调:应用各种微调技术,如监督指导微调(SFT)和多任务指导微调(MFT),以提高模型的性能1。
6. 模型评估:提供了一个全面的评估工具包,支持在线和离线推断评估方法。该工具包有助于根据性能指标驱动模型在不同下游任务中的训练,并可视化评估结果的反馈,以进行持续优化1。
7. 模型运维:解决与模型运维相关的挑战,如管理数百甚至数千个GPU训练实例。这包括自动检测故障节点、启动训练任务和监控训练进度的收敛1。
8. 模型评估:在行业环境中将CodeFuse集成到蚂蚁集团的软件开发流程中进行评估。开发了适用于流行集成开发环境(IDE)如VSCode、JetBrains等的扩展,以便将CodeFuse无缝集成到编码工作流程中。
# 数据准备
由于代码LLMs更专注于代码相关任务,因此在数据获取、数据清洗、去毒、去重和数据重新采样等方面与一般LLMs使用的方法存在显著差异。该部分主要关注CodeFuse如何为代码领域大型模型构建预训练数据。
## 预训练数据准备

1. 数据获取:CodeFuse的预训练数据包括196TB的代码、1.75TB的中文原始数据和1.7TB的英文原始数据,总计200TB。这些数据被标记为8000亿个标记,其中包括自行爬取的GitHub数据集和开源数据集Stack。数据清洗、去毒、去重和数据重新采样等步骤确保了训练数据的高质量。

2. 数据清洗:代码数据的清洗策略分为两个级别。
- 第一级过滤策略涉及文件属性方面,包括丢弃大文件(例如,超过1MB的单个文件或超过10000行的文件)和丢弃异常文本(例如,平均长度大于100或字母数字字符比例低于40%的行)。
- 第二级过滤策略依赖于蚂蚁集团的程序分析,通过代码特征分析,过滤不符合语法正确性和代码质量要求的代码数据。我们提出了两种分析代码特征的方法:基于静态分析和基于模型的两种方法。并定义了高质量代码评估模型,包括正确性,可读性,冗余性,命名风格,圈复杂度,代码耦合性等方面,并通过Sparrow对其执行度量 (该系统开源命名为CodeFuse-Query)。
3. 数据去毒:利用蚂蚁集团的内容风险控制和隐私数据保护能力,识别和过滤训练数据中的风险数据,确保数据安全。
4. 数据去重:进行多个粒度的去重,包括全局去重、细粒度文件级去重和基于代码分析的段级去重,以确保训练数据的敏感性。这些步骤有助于提高数据质量。
5. 数据重新采样:基于语言分布的重新采样删除了数据量较小的封闭编程语言的数据,并对HTML、CSS、JSON等可能对模型训练效果产生负面影响的语言进行了降采样。
## 微调下游任务数据准备
### 代码语义提取
1. 代码语义理解:代码大型语言模型的一个关键任务是理解代码的语义。为了支持这一点,需要提取带有自然语言注释的代码,这些注释作为代码语义的解释。通过静态分析提取高质量代码的代码片段及其对应的注释。这些提取的数据随后用于CodeFuse的监督微调(SFT)。这种方法的目标是确保模型不仅理解编程语言的语法,还深入理解代码的基本逻辑和功能,从而增强其代码理解能力。
2. 选择代码-注释对的策略:为了确保代码-注释对的质量,重点是从代码中提取函数及其对应的注释。利用基于规则的方法来过滤代码-注释对:
- 无意义的注释:使用Sparrow检测无意义的注释,包括注释关键字检测、自动生成的setter/getter方法的识别等。这些注释被认为是无关的,随后被丢弃。
- 丢弃少于3行的代码,以确保代码中有足够的上下文信息。
- 丢弃有效代码行少于总代码行数60%的方法,以确保包含大量有意义的代码。通过这些代码长度限制,策略旨在保持代码-注释对的可读性、可管理性,并确保提取的代码-注释对的整体质量。
- 丢弃超过512个字符的注释,以维持可读性和易管理性。通过这种评论长度限制,策略旨在确保生成的注释不会过长,从而提高代码-注释对的质量。
通过这些代码语义提取的步骤,可以帮助CodeFuse模型更好地理解代码的语义,从而提高其在代码相关任务中的性能和效果。
### 代码数据集画像
我们通过程序分析技术对代码进行注释、分类和分析,以捕获大规模代码库的各个维度特征,创建代码数据画像。算法工程师可以更全面、详细地了解用于训练大型语言模型的代码数据,有助于调整数据,优化预训练和自监督微调。
1. 对训练数据的深入洞察:分析代码画像的不同维度,可以提供 validation loss、perplexity 和feedback等相关的信息,这些信息有助于算法工程师确定模型当前的数据情况,比如哪类代码学习效果不佳等。
2. 增强训练数据:代码画像分析可以指导算法工程师通过改进表现较弱维度的数量或质量来增强训练数据。这可能涉及改善训练数据的分布或提高特定数据段的质量,以优化模型在后续实验中的性能。
总的来说,创建代码画像为训练数据提供了宝贵的见解,有助于优化模型性能,并指导研究人员改进与代码相关任务的大型语言模型的质量和效果。
# 训练过程
## 分词
CodeFuse使用基于BPE的分词器,包括编程语言关键字和常见词汇在内的10,864个词汇量,同时支持对中文和英文等自然语言的有效分割,确保准确的代码分词。与CodeLlama和CodeGen相比,CodeFuse分词器在代码、中文和英文上的性能,明显更好。

## 模型架构
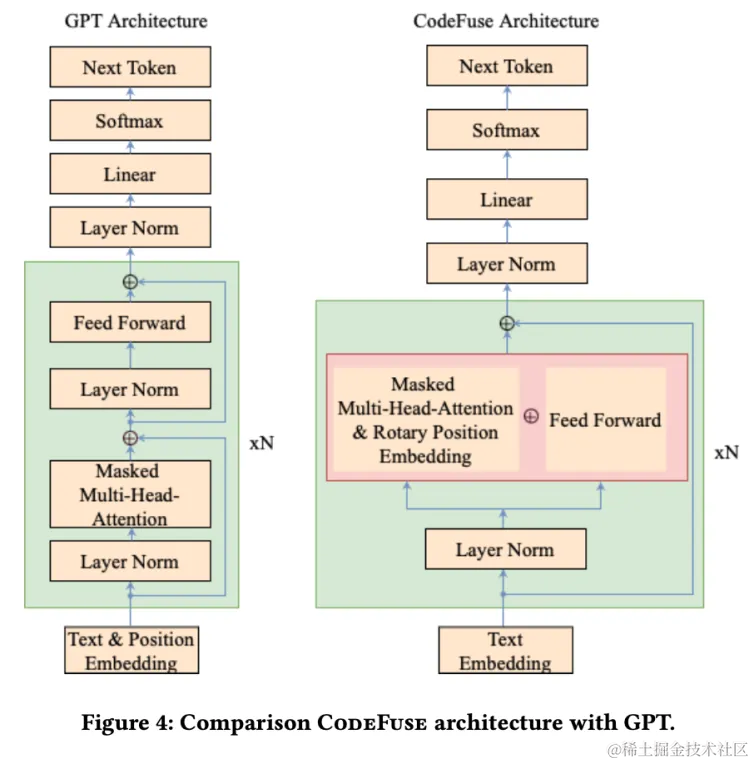
CodeFuse的模型架构是一种自回归Transformer,类似于GPT-3。我们对模型架构做了两个类似于GPT-J的优化:
1. 采用了Rotary Position Embedding (RoPE)
2. 采用parallel attention 和 FFN layer,代替GPT3的串行结构。
这种架构可以提高计算吞吐量约15%。
## CodeFuse训练
预训练:CodeFuse是基于GPT-NeoX框架进行训练的,该框架建立在Megatron和DeepSpeed之上,融合了对算法、通信和模型并行性的深度优化。我们在一个64节点的GPU集群上训练了CodeFuse,每个节点配备了八个NVIDIA A100-SXM-80GB GPU。
CodeFuse预训练版本有 350M,1.3B,6B 和 13B 等几个版本。CodeFuse-13B的训练采用了256路数据并行、2路张量并行和序列并行,通过DeepSpeed ZeRO-1减少内存消耗。CodeFuse-13B的序列长度为4096,并利用Flash Attention加速长序列模型训练。微批量大小为16,全局批量大小为4096,我们在512个GPU上实现了180 TFLOPS和56%的张量核心平均利用率。我们使用Adam优化器进行训练,初始学习率为1.5e-4,最小学习率为1.5e-5,并采用余弦学习率衰减方式。我们使用fp16混合精度训练模式,为避免精度下溢或溢出,将初始损失缩放设置为32768,最小损失缩放设置为1。
1.3B, 6B, and 13B 1.3B, 6B, and 13B
## 监督式微调(SFT)
CodeFuse的监督式微调(SFT)包含几个方面:数据收集、指令增强、数据格式化、训练策略和微调框架。以下各节将详细阐述每个方面。
1. SFT数据收集:作为面向代码领域的特定领域语言模型,需要具备以下功能:
○ 基本的自然语言理解能力:模型应能对复杂的自然语言问题提供令人满意的理解,以用于文本转代码任务。
○ 常见的下游代码任务:如文本转代码(自然语言转代码片段)、代码转换(不同编程语言之间的代码翻译)、代码注释、代码解释、生成测试用例等。
○ 多轮对话能力:应支持用户之间可能与先前上下文相关或不相关的多轮对话,需要模型做出准确的意图判断。
○ 无毒输出:模型应生成无毒害和有害内容。除了遵守基本的人类价值观和道德伦理外,作为代码LLM的CodeFuse需要特别关注与代码相关的毒性。例如,不应生成可能引发信息安全问题的内容,如钓鱼或特洛伊木马程序
2. Self-instruction 指令增强:如数据收集章节,我们介绍了通过程序分析技术在公共数据集上收集了代码相关任务的问题-答案对。同时,我们还引入了Alpaca的Self-instruct方法,利用手写或原始数据集作为种子,生成丰富信息且相关的上下文。
3. Instruction-following description:为不同任务构建合适的输入和输出,是非常重要的。然而,对于LLM来说,仍存在一个步骤差距,即指令描述。一些信息已经包含在输入中,而其他数据则需要添加指令描述,以使模型熟悉特定任务的指导。此外,可以添加上下文描述和思维链(CoT)信息以增强模型的性能。
4. 数据格式:在实践中,不同场景的数据,如多轮对话、少样本学习和CoT任务,来自多种渠道,具有复杂的格式。为了处理这种情况,我们采用ChatML(聊天标记语言)对这些不同任务类型的原始JSON格式进行了标准化。通过优化解决了格式设计中的诸如标记化错误、指令注入攻击和多角色扮演场景等问题。LLM模型在训练和推断过程中接受一系列文本输入,并将原始JSON数据转换为ChatML格式的文本序列。CodeFuse对话模型默认支持三种角色:系统、人类和机器人。系统角色提供初始信息和指令,而人类和机器人角色分别代表用户输入和模型生成的响应。
5. 微调优化:在微调过程中,模型专注于通过仅计算机器人角色的损失来学习机器人的输出。此外,CodeFuse引入了多任务微调(MFT),因为下游代码任务自然地分为多个任务。MFT引入了基于多任务学习的设计良好的损失函数,使模型能够有效地从每个任务中学习,即使样本数量、难度和收敛速度各不相同。MFT可以补充不同任务,以实现比SFT更好的结果。有关MFT的详细信息将在另一篇论文中详细阐述。
## 模型运维
CodeFuse-13B使用了512张Nvidia A100 GPU卡进行训练,硬件FLOPs利用率约为60%。训练过程大约花费了40天。为确保成功的训练过程的稳定性,我们开发了一个基于云的可观测性系统,包括两个主要部分:
- 训练指标的可观测性对于监控训练过程至关重要,包括重要指标如训练/验证损失以评估收敛性和计算FLOPs水平。CodeFuse部署了一个在云中的TensorBoard实例,允许用户通过Web浏览器访问和分析这些指标。
- 基础设施指标的可观测性涵盖了各个方面,如GPU和RDMA。CodeFuse使用DCGM/NVML来收集GPU/RDMA性能指标、ECC错误和Xid错误。他们还使用了一个名为Walle的节点侧检测代理来捕获硬件异常信息。GPU诊断组件处理故障恢复操作。GPU集群利用RDMA高性能网络技术进行高效的数据传输和处理。
GPU诊断系统,协助CodeFuse训练,用于主动发现和自动处理GPU节点的故障,以及在没有手动干预的情况下自动重新启动/恢复终止的训练任务。在故障发生后的30分钟内,系统识别、隔离和重新安排有问题的GPU卡,使训练可以继续进行并使用最新的检查点。为了保持GPU资源的高可用性,我们为GPU卡的可调度性定义了SLO指标,导致在训练周期内集群的GPU可用性从87%增加到94%。
# 模型评测
CodeFuse-13B在软件工程任务的各种实际场景中展现出了有效性。一些CodeFuse-13B被证明有效的关键领域包括:
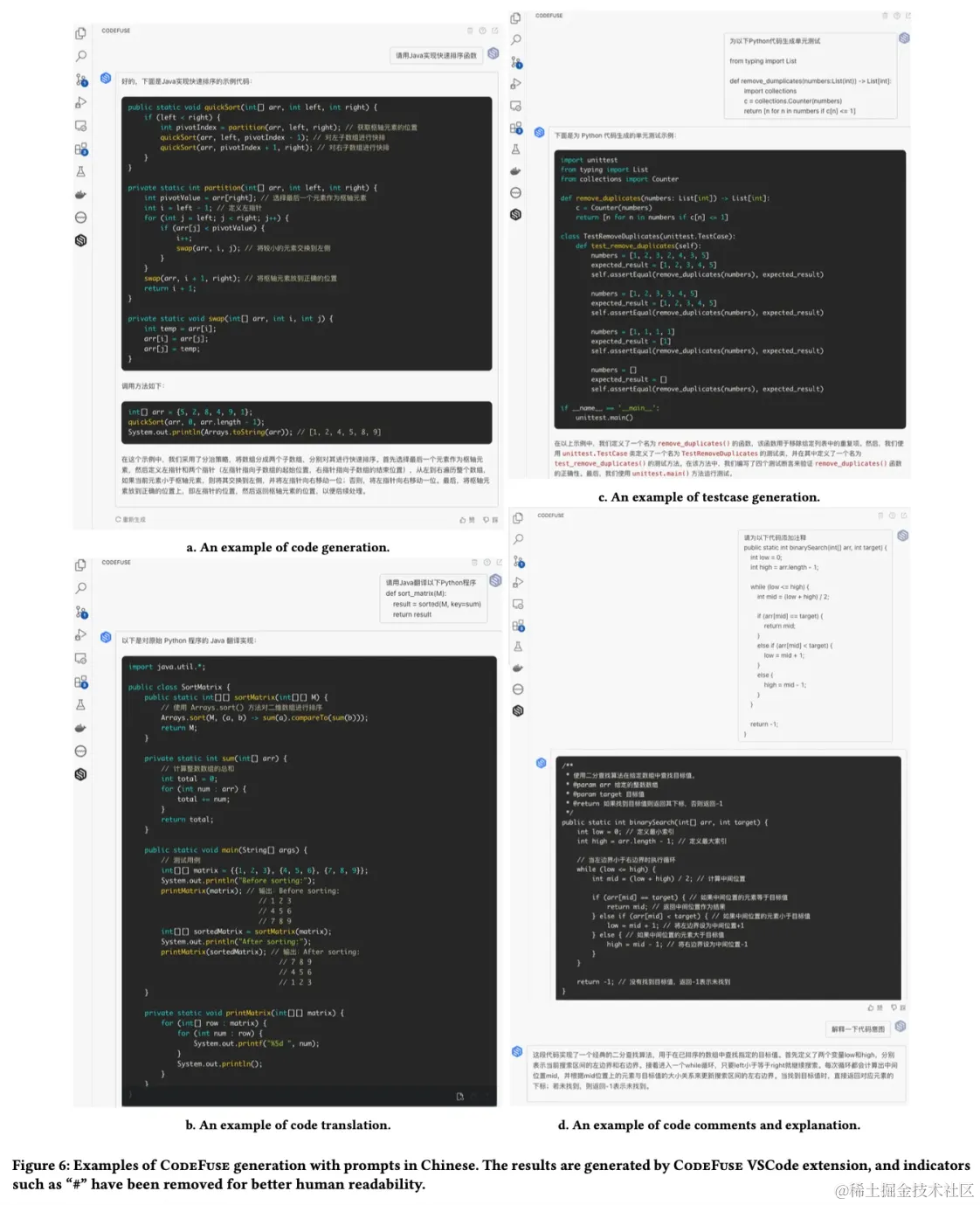
1. 代码生成:CodeFuse-13B擅长根据用户提示为不同编程语言生成代码片段。它可以帮助开发人员快速生成代码模板、函数或整个程序,从而提高软件开发工作流程的生产力。
2. 代码翻译:CodeFuse-13B在不同编程语言之间的代码翻译方面表现出色。它可以准确地将一个语言的代码片段转换为另一种语言,促进跨语言代码迁移和互操作性。
3. 代码注释:CodeFuse-13B能够为代码片段生成信息丰富且相关的注释。这个功能可以帮助开发人员有效地记录他们的代码,提高代码可读性,并增强开发团队内的协作。
4. 测试用例生成:CodeFuse-13B可以根据提供的代码片段自动生成测试用例。这个功能有助于测试软件应用程序,确保代码质量,并加速测试过程。
5. 支持中文提示:CodeFuse-13B专门设计支持中文提示,使其对使用中文的语言环境中工作的开发人员非常有价值。它可以有效处理具有中文输入的代码相关任务,如代码生成、翻译、注释和测试用例生成。
总的来说,CodeFuse-13B在代码生成、翻译、注释和测试用例生成方面的有效性,以及对中文提示的支持,使其成为一种多功能且有价值的工具,适用于各种实际软件工程场景。
## 评测数据集
HumanEval、HumanEval-x和MBPP是代码LLM领域中使用的广泛基准测试。这些基准测试包括大量的编程问题,使用测试用例来验证代码LLM生成的代码。然而,在涉及中文输入的情况下,仍需要在某些代码场景中使用评估方法为了。解决这个问题,我们开发了开源了CodefuseEval benchmark,以在代码促进补全、代码生成、跨程序翻译、代码语言注释代码和测试用例生成场景中使用英文中文提示和的评估。CodefuseEval基准测试是HumanEval和MBPP测试基准的,扩展涵盖了Python、Java、C++、Go和JavaScript等五种编程语言。
对于包括代码全补、文本转、代码代码翻译和测试用例生成在内 的代码生成,任务我们采用pass@k指标作为评估标准。对于代码注释任务,我们使用Bleu和BleuRT作为评估指标。为了全面评估模型在多任务评估代码中的能力,我们采用了解码三种策略:温度采样、贪婪和束搜索。使用提示零格式射,允许模型进行在不特定微任务的调的情况下生成。响应在使用温度采样策略时我们,为pass@1设置了以下超参数:温度=0.2、top_p=0.95和generaten=10个样本。
## 代码生成
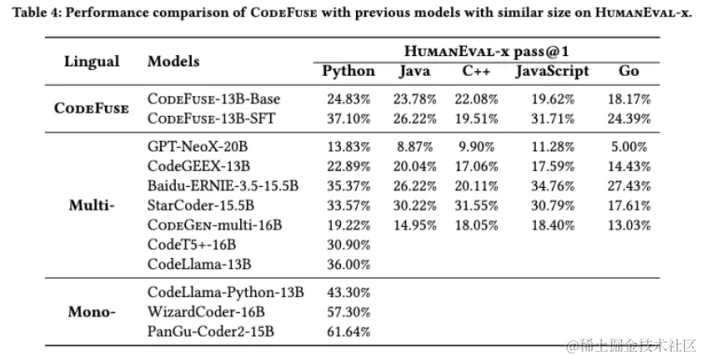
在我们将CodeFuse与类似规模的现有代码语言模型(LLMs)进行比较时,我们评估了它们的代码生成性能。我们展示了CodeFuse多个版本的评测结果,这些版本中大都部署在蚂蚁集团的实际研发场景中。此外,我们从现有报告中收集了 13B到16B参数规模的七个当前主流多语言模型 GPT-NeoX-20B, CodeGeeX-13B, Baidu-ERNIE-3.5-15.5B, StarCoder-15.5B, CodeGen-multi-16B, CodeT5+-16B, CodeLlama-13B。其中,CodeT5+和CodeLlama并未公布其在HumanEval-x上的表现,因此数据缺失。我们还展示了三种最先进的单语言代码模型,CodeLlama-Python、WizardCoder和PanGu-Coder2。在HumanEval Python pass@1评估中,CodeFuse-13B 超过其他7个多语言模型。然而,由于 CodeLlama-Python、WizardCoder和PanGu-Coder2这样的单语言模型(Mono-)已针对Python代码生成进行了特定优化,CodeFuse要在Python评估中超越它们仍然具有挑战性。
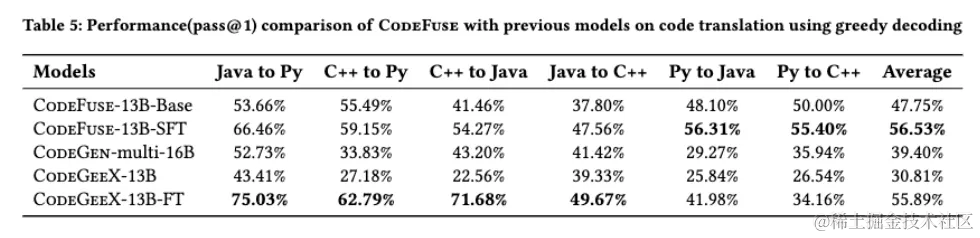
## 代码翻译
通过将CodeFuse与CodeGen-multi-16B和CodeGeeX-13B进行比较,对其进行了多语言代码翻译的评估。CodeGeeX-13B有一个专门用于代码翻译的精细调整版本称为CodeGeeX-13B-FT,同样CodeFuse-13B-SFT是一个包括代码翻译的多任务精细调整版本。我们使用基于MBXP和HumanEval-x构建的代码翻译评估数据集。它包括经专家审查和纠正的案例,并作为CodefuseEval的一部分开放。结果展示了使用贪婪解码进行Java、Python和C++之间相互转换的pass@1结果。CodeFuse-13B-SFT在将Python代码翻译成其他两种语言时优于其他模型。此外,它在所有六种翻译场景中实现了最高的平均分数。
## 支持中文提示的代码任务
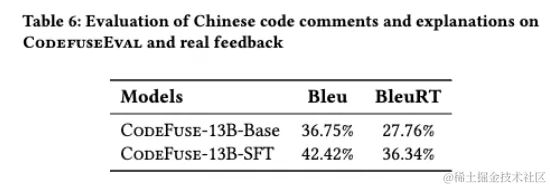
CodeGeeX有很好的中文支持能力,我们将其作为基准模型,评测CodeFuse的中文支持能力。除了前面提到的代码生成和代码翻译评估外,我们的评估还包括测试用例生成、代码注释和解释。在代码注释和解释任务中,我们特别将我们的CodeFuse集成到蚂蚁集团的开发流程中进行评估。我们收集了开发人员在日常工作中提供的宝贵反馈,以评估在实际场景中的性能。在收集了几个月的人类反馈后,CodeFuse-13B-SFT的Bleu分数为42.42%,BleuRT分数为36.34%。这些结果表明CodeFuse在实际开发场景中确实很有用。在自动生成测试用例评测中, CodeFuse在使用中文提示生成测试用例的任务中胜过了CodeGeeX。

# CodeFuse工具链
## CodeFuse-Query(Sparrow)
CodeFuse-Query(Sparrow)早于CodeFuse的项目,它是一种强大的静态代码分析平台,适合大规模、复杂的代码库分析场景。它的以数据为中心的方法和高度的可扩展性使得它在现代软件开发环境中具有独特的优势。CodeFuse-Query(Sparrow)代码数据平台分为三大部分:代码数据模型、代码查询DSL、平台产品化服务。CodeFuse-Query(Sparrow)使我们可以轻松实现代码数据化任务,也使得Code LLM数据准备变得轻松容易。
CodeFuse-Query(Sparrow)开源地址:https://github.com/codefuse-ai/CodeFuse-Query
## 扩展MFT开源框架
我们开发了一个多任务微调框架MFTCoder,并已经开源。该框架可用于微调我们内部开发的CodeFuse-13B和新兴的开源代码LLM,如StarCoder和CodeLLaMA。我们在收集的数据集上使用MFT-Coder框架微调了StarCoder和CodeLLaMA模型,并将微调版本开源为CodeFuse-CodeLlama-34B和CodeFuse-StarCoder-15B。CodeFuse-CodeLlama-34B在HumanEval上获得了74.4%的pass@1,超过了GPT4和ChatGPT-3.5的分数,在当时,领先其他开源语言模型模型(LLM)。同样明显的是,CodeFuse中的数据准备策略极大地增强了其他代码LLM的性能。
MFTCoder开源地址:https://github.com/codefuse-ai/MFTCoder
## 部署优化
CodeFuse以IDE插件和基于网络的聊天的形式部署在蚂蚁集团的生产环境中。为了促进模型响应时间和服务吞吐量,我们为模型服务引入了一系列优化,包括(1)使用自动迭代精炼的GPTQ将模型int4量化,精度损失可以忽略不计;(2)利用Nvidia TensorRT-LLM 5提供的软件优化;(3)通过语义缓存和流输出执行服务优化。该产品现在支持蚂蚁集团中超过5K工程师的日常软件开发。
# CodeFuse相关资料链接
Github:https://github.com/codefuse-ai/codefuse
Huggingface:https://huggingface.co/codefuse-ai/CodeFuse-13B
arXiv:https://arxiv.org/abs/2310.06266
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









