







ThreadLocal详解
1. ThreadLocal入门
1.1 官方介绍
/**
* <p>这个类提供线程局部变量。 这些变量与其正常的对应方式不同,因为访问一个的每个线程(通过其get或set方法)
* 都有自己独立初始化的变量副本。ThreadLocal实例通常是希望将状态与线程关联的类中的私有静态字段(例如,用户ID或事务ID)。
*
* <p>例如,下面的类生成每个线程本地的唯一标识符。 线程的ID在第一次调用ThreadId.get()时被分配,并在后续调用中保持不变。
* <pre>
* import java.util.concurrent.atomic.AtomicInteger;
*
* public class ThreadId {
* // Atomic integer containing the next thread ID to be assigned
* private static final AtomicInteger nextId = new AtomicInteger(0);
*
* // Thread local variable containing each thread's ID
* private static final ThreadLocal<Integer> threadId =
* new ThreadLocal<Integer>() {
* @Override
* protected Integer initialValue() {
* return nextId.getAndIncrement();
* }
* };
*
* // Returns the current thread's unique ID, assigning it if necessary
* public static int get() {
* return threadId.get();
* }
* }
* </pre>
*
* <p>只要线程存活并且ThreadLocal实例可以访问,每个线程都保存对其线程局部变量副本的隐式引用;
* 线程消失后,线程本地实例的所有副本都将被垃圾收集(除非存在对这些副本的其他引用)。
*/
public class ThreadLocal<T> {
...
通过源码中的注释(代码中的注释已翻译,需要看原版的同学请参考源码)我们可以得知,ThreadLocal类用来提供线程内部的局部变量,在多线程环境中能保证各个线程变量的相对独立于其他线程内的变量,不同的线程之间互不干扰,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或组件之间一些公共变量传递的复杂度。
1.1.1 总结特征如下:
1. 线程并发: 在多线程并发的场景下
2. 传递数据: 我们可以通过ThreadLocal保证在同一线程中,不同的对象中、方法中(也就是不同组件)传递公共变量
3. 线程隔离: 每个线程的变量都是独立的,不会互相影响
1.2. ThreadLocal基本用法
我们先来看一下ThreadLocal常用的场景,感受一下ThreadLocal线程隔离的特点
public class ThreadLocalTest {
private String context;
public String getContext() {
return context;
}
public void setContext(String context) {
this.context = context;
}
public static void main(String[] args) {
ThreadLocalTest tlt = new ThreadLocalTest();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(() -> {
tlt.setContext(Thread.currentThread().getName() + "的数据");
System.out.println("------------------------");
System.out.println(Thread.currentThread().getName() + "--->" + tlt.getContext());
});
t.setName("线程" + i);
t.start();
}
}
}
运行结果如下:
------------------------
线程0--->线程1的数据
------------------------
线程1--->线程3的数据
------------------------
线程3--->线程4的数据
------------------------
线程2--->线程4的数据
------------------------
线程4--->线程4的数据
我们希望打印的结果是线程名和数据是对应的。通过观察运行结果可知这和我们期望的运行结果不一样,问什么呢?作为代码老司机一眼就能看出来端倪,是线程安全的问题。
下面我们来看下采用ThreadLocal的方式来解决这个问题。
public class ThreadLocalTest {
// 这里不使用 static 也是可以的
private static ThreadLocal<String> tl = new ThreadLocal<>();
public String getContext() {
// 在同一个线程内要先调用 ThreadLocal 的 set方法进行值的绑定。否则get方法会返回null
return tl.get();
}
public void setContext(String context) {
tl.set(context);
}
public static void main(String[] args) {
ThreadLocalTest tlt = new ThreadLocalTest();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(() -> {
tlt.setContext(Thread.currentThread().getName() + "的数据");
System.out.println("------------------------");
System.out.println(Thread.currentThread().getName() + "--->" + tlt.getContext());
});
t.setName("线程" + i);
t.start();
}
}
}
运行结果如下:(运行的结果可能打印的顺序不一样但是,线程名和数据是对上的就可以)
------------------------
线程0--->线程0的数据
------------------------
线程3--->线程3的数据
------------------------
线程2--->线程2的数据
------------------------
线程1--->线程1的数据
------------------------
线程4--->线程4的数据
在代码中我们使用了ThreadLocal来代替原来的context变量。从结果来看这样就很好的解决了线程安全的问题,很是简单方便。
1.3 ThreadLocal和synchronized比较
有些同学看到这里可能会想,我使用synchronized也能解决线程安全的问题啊。是的使用synchronized确实也能解决线程安全的问题,下面我们就来看看使用synchronized怎么来解决上面线程安全的问题的。
public class ThreadLocalTest {
private String content;
public String getContext() {
return content;
}
public void setContext(String context) {
this.content = context;
}
public static void main(String[] args) {
ThreadLocalTest tlt = new ThreadLocalTest();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(() -> {
synchronized (ThreadLocalTest.class) {
tlt.setContext(Thread.currentThread().getName() + "的数据");
System.out.println("------------------------");
System.out.println(Thread.currentThread().getName() + "--->" + tlt.getContext());
}
});
t.setName("线程" + i);
t.start();
}
}
}
运行结果如下:
------------------------
线程0--->线程0的数据
------------------------
线程4--->线程4的数据
------------------------
线程3--->线程3的数据
------------------------
线程2--->线程2的数据
------------------------
线程1--->线程1的数据
从运行结果上看,使用synchronized也解决了这里的线程安全的问题,但是在这里我们强调的是线程数据隔离的问题,并不是多线程共享数据的问题, 在这个案例中使用synchronized关键字是不合适的。而且在synchronized代码块内部的代码同时只能有一个线程访问,势必降低了一定的性能,而使用ThreadLocal就不会,因为使用ThreadLocal不存在线程竞争的问题使用程序具有更高的并发性。
总的来说ThreadLocal和synchronized各有各的有点,要根据实际的场景来使用。
2. 使用场景
经过上面的介绍,我们对ThreadLocal的使用方法和特点已经有了基础的了解,但是实际应用中该怎么使用呢?下面我们就来进行一下实际的应用:数据库事务的操作(以经典的转账案例来说)。
2.1 转账案例
2.1.1 项目准备
数据
-- 如果不存在 test 数据库就创建
create database if not exists test;
-- 使用 test 数据库
use test;
-- 如果已经存在了 account 表就先删除这个表然后再创建
drop table if exists account;
create table account(
id int primary key auto_increment,
name varchar(40),
money float
)character set utf8 collate utf8_general_ci;
insert into account(name, money) values('aaa',1000);
insert into account(name, money) values('bbb',2000);
insert into account(name, money) values('ccc',3000);
项目结构
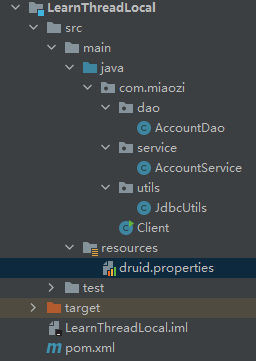
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.miaozi</groupId>
<artifactId>LearnThreadLocal</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.13</version>
</dependency>
</dependencies>
</project>
druid的配置文件:druid.properties
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///test
username=root
password=123456
initialSize=10
maxActive=15
JDBC工具类:JdbcUtils.java
public class JdbcUtils {
private static DataSource dataSource = null;
static {
try {
Properties props = new Properties();
InputStream is = ClassLoader.getSystemResourceAsStream("druid.properties");
props.load(is);
dataSource = DruidDataSourceFactory.createDataSource(props);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("数据源初始化失败");
}
}
// 获取连接
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
// 释放资源
public static void release(AutoCloseable... la) {
for (AutoCloseable closeable : la) {
if (closeable != null) {
try {
closeable.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static void commitAndClose(Connection conn) {
if (conn != null) {
try {
// 提交事务
conn.commit();
//关闭连接
conn.close();
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
}
}
}
public static void rollbackAndClose(Connection conn) {
if (conn != null) {
try {
// 回滚事务
conn.rollback();
//关闭连接
conn.close();
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
}
}
}
}
dao层代码:AccountDao.java
public class AccountDao {
public boolean out(String name, int money) throws SQLException {
String sql = "update account set money = money - ? where name = ?";
Connection conn = JdbcUtils.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, money);
ps.setString(2, name);
int updateCount = ps.executeUpdate();
JdbcUtils.release(ps, conn);
return updateCount == 1;
}
public boolean in(String name, int money) throws SQLException {
String sql = "update account set money = money + ? where name = ?";
Connection conn = JdbcUtils.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, money);
ps.setString(2, name);
int updateCount = ps.executeUpdate();
JdbcUtils.release(ps, conn);
return updateCount == 1;
}
}
service层代码:AccountService.java
public class AccountService {
public boolean transfer(String outName, String inName, int money) {
AccountDao dao = new AccountDao();
try {
// 转出
boolean out = dao.out(outName, money);
int i = 1 / 0; // 这里会报错,但是上面的语句已经执行成功啦,就会导致数据库数据不一致的情况
// 转入
boolean in = dao.in(inName, money);
} catch (SQLException e) {
e.printStackTrace();
return false;
}
return true;
}
}
web层代码:这里使用Client.java来进行模拟前端的请求
public class Client {
public static void main(String[] args) {
String outName = "aaa";
String inName = "bbb";
int money = 100;
AccountService as = new AccountService();
boolean res = as.transfer(outName, inName, money);
if (res) {
System.out.println("转账成功");
} else {
System.out.println("转账失败");
}
}
}
2.1.2 使用事务
在上面的转账案例中涉及到了两个DML操作:一个转出,一个转入。然而转账操作要具备原子性的,不可分割的,不然在发生错误的时候就会数据就会出现异常,比如A用户想B用户转账100元。我们首先更新了A用户的账户余额减少100,但是由于其他的原因,导致B用户的账户余额没有增加100,这是不允许发生的。
- 所以这就需要操作事务,来保证转出和转入操作具备原子性,要么全部同时成功要么全部同时失败,就是要么全部执行要么全部都不执行。
JDBC中关于事务的常见操作如下:
// conn 是一个 Connection 对象
// 设置不自动提交
conn.setAutoCommit(false);
// 提交事务
conn.commit();
// 事务回滚
conn.rollback();
- 开启事务的注意点:
为了保证所有的操作都在一个事务中,所以在一个事务中的操作都必须使用同一个连接;service层开启事务的connection需要和访问数据库的dao层使用同一个connection对象;线程并发的情况下,每一个线程只能操作各自的connection。
2.2 常规解决方案
综合上面事务的说明,我们首先想到的解决方案就是:
- 使用传参的方式:从
service层将connection对象向dao层传递并且加锁
首先需要修改dao层代码,connection不能直接在dao层里获取了,需要在service层传入,所以也能在这里释放连接,如果在这里释放的话会导致错误。
public class AccountDao {
public boolean out(String name, int money, Connection conn) throws SQLException {
String sql = "update account set money = money - ? where name = ?";
// 注释从连接池获取连接的代码,使用从service中传递过来的connection
// Connection conn = JdbcUtils.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, money);
ps.setString(2, name);
int updateCount = ps.executeUpdate();
// JdbcUtils.release(ps, conn);
// 不能在 dao 释放connection
JdbcUtils.release(ps);
return updateCount == 1;
}
public boolean in(String name, int money, Connection conn) throws SQLException {
String sql = "update account set money = money + ? where name = ?";
// 注释从连接池获取连接的代码,使用从service中传递过来的connection
// Connection conn = JdbcUtils.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, money);
ps.setString(2, name);
int updateCount = ps.executeUpdate();
//JdbcUtils.release(ps, conn);
// 不能在 dao 释放connection
JdbcUtils.release(ps);
return updateCount == 1;
}
}
下面来修改service层代码
public class AccountService {
public boolean transfer(String outName, String inName, int money) {
AccountDao dao = new AccountDao();
Connection conn = null;
try {
conn = JdbcUtils.getConnection();
// 开启事务
conn.setAutoCommit(false);
// 转出
boolean out = dao.out(outName, money, conn);
if (!out) {
throw new SQLException("转账,转出失败");
}
// 模拟出现异常
int i = 1 / 0;
// 转入
boolean in = dao.in(inName, money, conn);
if (!in) {
throw new SQLException("转账,转入失败");
}
// 提交事务并关闭连接
JdbcUtils.commitAndClose(conn);
} catch (SQLException e) {
e.printStackTrace();
// 发生异常的时候就回滚事务
JdbcUtils.rollbackAndClose(conn);
return false;
}
return true;
}
}
这种方案的弊端,上述方式我们看到的确按要求解决了问题,但是仔细观察,会发现这样实现的弊端:
- 直接从
service层传递connection到dao层, 造成代码耦合度提高。 - 加锁会造成线程失去并发性,程序并发性能降低。
2.3 ThreadLocal解决方案
通过上面的介绍我们可以得知,ThreadLocal具有线程隔离的特性,而在我们上面转账的案例中,对于connection正好有这种需求。下面我们就来使用ThreadLocal来解决该问题
首先修改JDBC工具类:JdbcUtils.java,加入ThreadLocal,使用ThreadLocal来维护Connection对象
public class JdbcUtils {
private static DataSource dataSource = null;
//ThreadLocal对象将connection绑定在当前线程中
private static final ThreadLocal<Connection> tl = new ThreadLocal();
// 静态代码块
static {
try {
Properties props = new Properties();
InputStream is = ClassLoader.getSystemResourceAsStream("druid.properties");
props.load(is);
dataSource = DruidDataSourceFactory.createDataSource(props);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("数据源初始化失败");
}
}
// 获取连接
public static Connection getConnection() throws SQLException {
//取出当前线程绑定的connection对象
Connection conn = tl.get();
if (conn == null) {
//如果没有,则从连接池中取出一个
conn = dataSource.getConnection();
//再将connection对象绑定到当前线程中
tl.set(conn);
}
return conn;
}
// 释放资源
public static void release(AutoCloseable... la) {
for (AutoCloseable closeable : la) {
if (closeable != null) {
try {
closeable.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static void commitAndClose() {
try {
Connection conn = getConnection();
// 提交事务
conn.commit();
//关闭连接
conn.close();
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
}
}
public static void rollbackAndClose() {
try {
Connection conn = getConnection();
// 回滚事务
conn.rollback();
//关闭连接
conn.close();
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
}
}
}
修改dao层代码,dao不在需要冲service层传递connection,而是由工具类直接获取
public class AccountDao {
public boolean out(String name, int money) throws SQLException {
String sql = "update account set money = money - ? where name = ?";
Connection conn = JdbcUtils.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, money);
ps.setString(2, name);
int updateCount = ps.executeUpdate();
// JdbcUtils.release(ps, conn);
// 不能在 dao 释放connection
JdbcUtils.release(ps);
return updateCount == 1;
}
public boolean in(String name, int money) throws SQLException {
String sql = "update account set money = money + ? where name = ?";
Connection conn = JdbcUtils.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, money);
ps.setString(2, name);
int updateCount = ps.executeUpdate();
//JdbcUtils.release(ps, conn);
// 不能在 dao 释放connection
JdbcUtils.release(ps);
return updateCount == 1;
}
}
service层AccountService类的修改:不需要传递connection对象,而是重新回到由dao层获取connection
public class AccountService {
public boolean transfer(String outName, String inName, int money) {
AccountDao dao = new AccountDao();
try {
Connection conn = JdbcUtils.getConnection();
// 开启事务
conn.setAutoCommit(false);
// 转出
boolean out = dao.out(outName, money);
if (!out) {
throw new SQLException("转账,转出失败");
}
// 模拟出现异常
int i = 1 / 0;
// 转入
boolean in = dao.in(inName, money);
if (!in) {
throw new SQLException("转账,转入失败");
}
// 提交事务并关闭连接
JdbcUtils.commitAndClose();
} catch (SQLException e) {
e.printStackTrace();
// 发生异常的时候就回滚事务
JdbcUtils.rollbackAndClose();
return false;
}
return true;
}
}
ThreadLocal方案的好处,在一些特定场景下,ThreadLocal方案有两个突出的优势:
- 传递数据 : 保存每个线程绑定的数据,在需要的地方可以直接获取, 避免参数直接传递带来的代码耦合问题
- 线程隔离 : 各线程之间的数据相互隔离却又具备并发性,避免同步方式带来的性能损失
3. ThreadLocal的内部结构
经过上面的介绍,我们应该对ThreadLocal的使用和特性有了一定的了解。下面我们就来详细的讲解一下其内部原理。
3.1 常见的误解
如果不看源码的话,大部分人可能会猜测ThreadLocal的内部应该是依赖于一个Map的数据结构,每一个ThreadLocal都创建一个Map,然后使用线程或者使用线程id作为Map的key,我们要存储的变量作为Map的value,这样就能达到各个线程的局部变量隔离的效果啦。这是最简单的设计方法,JDK最早期的ThreadLocal 确实是这样设计的,但现在早已不是了。(我自己的看法:直接使用上面的这种设计存在一定的问题,比如我们在操作ThreadLocal时是存在线程安全问题的,尤其是在调用set、get和remove方式时)
3.2 ThreadLocal发展
早在JDK 1.2的版本中就有提供 java.lang.ThreadLocal,但是在之前的版本中都存在一些不足的情况,经过 JDK后面的优化,在 JDK 8 中 ThreadLocal的设计是:每一个Thread维护一个 ThreadLocalMap(ThreadLocal的一个静态内部类,类似一个 Map ) 的对象。这个Map的key是ThreadLocal实例本身,value才是真正要存储的值Object。
具体的设计如下:
1 每一个Thread线程内部都有一个 Map (ThreadLocalMap) 对象,变量名为 threadLocals(下面用 map 代称)
2 这个 map 里面存储 ThreadLocal 对象(作为key)和线程的变量副本(作为value)
3 Thread 内部的 map 是由 ThreadLocal 来维护的,有 ThreadLocal 负责对 map 设置和获取线程的变量值
4 对于不同的线程,每次获取变量副本值时,别的线程并不能获取当前线程的副本值,形成了副本的隔离,互不干扰。
3.3 这样设计的好处
-
这样设计之后每一个
Map存储的Entry数量就会比较少 ,因为存储的数量是由使用ThreadLocal的数量来决定的。而在实际运用中,往往ThreadLocal的数量是少于Thread的数量的。 -
当
Thread销毁之后,对应的ThreadLocalMap也会随之销毁,这样就能减少内存的使用。
4. 源码
4.1 ThreadLocal的四个核心方法
ThreadLocal类接口很简单,只有4个方法,在JDK5.0之前这四个方法如下:
void set(Object value)设置当前线程的线程局部变量的值。public Object get()该方法返回当前线程所对应的线程局部变量。public void remove()将当前线程局部变量的值删除,目的是为了减少内存的占用,该方法是JDK 5.0新增的方法。需要指出的是,当线程结束后,对应该线程的局部变量将自动被垃圾回收,所以显式调用该方法清除线程的局部变量并不是必须的操作,但它可以加快内存回收的速度。protected Object initialValue()返回该线程局部变量的初始值,该方法是一个protected的方法,显然是为了让子类覆盖而设计的。这个方法是一个延迟调用方法,在线程第1次调用get()或set(Object)时才执行,并且仅执行1次。ThreadLocal中的缺省实现直接返回一个null。
值得一提的是,在JDK5.0中,ThreadLocal已经支持泛型,该类的类名已经变为ThreadLocal<T>。API方法也相应进行了调整,新版本的API方法分别是void set(T value)、T get()以及T initialValue()。
4.1.1set方法
在调用ThreadLocal的set`方法时的执行流程如下:
- 首先获取当前线程,并根据当前线程获取一个
ThreadLocalMap的对象实例map - 如果获取的Map不为空,则将参数设置到Map中(当
ThreadLocal的引用作为key) - 如果Map为空,则给该线程创建 Map,并设置初始值
/**
* 设置当前线程对应的ThreadLocal的值
* @param value 将要存储在前线程对应的 ThreadLocal 中的变量副本的值
*/
public void set(T value) {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 判断map是否存在
if (map != null)
// 存在则调用map.set设置此实体entry
map.set(this, value);
else
// 当前线程Thread不存在ThreadLocalMap对象时
// 则调用createMap进行ThreadLocalMap对象的初始化
// 并将t(当前线程)和value(t对应的值)作为第一个entry存放至ThreadLocalMap中
createMap(t, value);
}
/**
* 获取当前线程Thread对应维护的ThreadLocalMap
* @param t 当前线程
* @return 当前线程Thread对应维护的ThreadLocalMap
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
/**
* 创建当前线程Thread对应维护的ThreadLocalMap
* @param t 当前线程
* @param firstValue 存放到map中第一个entry的值
*/
void createMap(Thread t, T firstValue) {
//这里的this是调用此方法的threadLocal
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
4.1.2initialValue方法
如果在调用set方法前调用get方法,就会调用这个方法来初始化当前线程中保存ThreadLocal的初始化值。并且仅执行1次。
这个方法缺省实现直接返回一个null
如果想要一个除null之外的初始值,可以重写此方法。(备注: 该方法是一个protected的方法,显然是为了让子类覆盖而设计的)
/**
* 返回当前线程中保存ThreadLocal的初始化值
* 如果在调用set方法前调用get方法,就会调用这个方法来初始化当前线程中保存ThreadLocal的初始化值
* 默认为 null
* @return 返回当前线程中保存ThreadLocal的初始化值
*/
protected T initialValue() {
return null;
}
4.1.3get方法
在调用ThreadLocal的get方法时的执行流程如下:
- 首先获取当前线程, 根据当前线程获取一个
Map - 如果获取的
Map不为空,则在Map中以ThreadLocal的引用作为key来在Map中获取对应的Entry e,否则转到 4 - 如果
e不为null,则返回e.value,否则转到 4 Map为空或者e为空,则通过initialValue函数获取初始值value,然后用ThreadLocal的引用和value作为firstKey和firstValue创建一个新的Map
总结: 先获取当前线程的ThreadLocalMap 变量,如果存在则返回值,不存在则创建并返回初始值。
/**
* 如果当前线程没有此ThreadLocal变量
* 则它会通过调用 initialValue方法进行初始化值
* @return 返回当前线程中保存ThreadLocal的值
*/
public T get() {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 如果此map存在
if (map != null) {
// 以当前的ThreadLocal 为 key,调用getEntry获取对应的存储实体e
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
// 获取存储实体 e 对应的 value 值
// 即为我们想要的当前线程对应此ThreadLocal的值
T result = (T) e.value;
return result;
}
}
// 初始化 : 有两种情况有执行当前代码
// 第一种情况: map不存在,表示此线程没有维护的ThreadLocalMap对象
// 第二种情况: map存在, 但是没有与当前ThreadLocal关联的entry
return setInitialValue();
}
/**
* 初始化
* @return the initial value 初始化后的值
*/
private T setInitialValue() {
// 调用initialValue获取初始化的值
// 此方法可以被子类重写, 如果不重写默认返回null
T value = initialValue();
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 判断map是否存在
if (map != null)
// 存在则调用map.set设置此实体entry
map.set(this, value);
else
// 1)当前线程Thread 不存在ThreadLocalMap对象
// 2)则调用createMap进行ThreadLocalMap对象的初始化
// 3)并将 t(当前线程)和value(t对应的值)作为第一个entry存放至ThreadLocalMap中
createMap(t, value);
// 返回设置的值value
return value;
}
4.1.4remove方法
在调用ThreadLocal的remove方法时的执行流程如下:
- 首先获取当前线程并且根据当前线程获取其对应的
ThreadLocalMap对应的map - 如果
map不为空就移除当前ThreadLocal对象对应entry
// 删除当前线程中保存的ThreadLocal对应的实体entry
public void remove() {
// 获取当前线程对象中维护的ThreadLocalMap对象
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// 存在则调用map.remove
// 以当前ThreadLocal为key删除对应的实体entry
m.remove(this);
}
5. ThreadLocal 静态内部类ThreadLocalMap源码分析
我们在上面介绍ThreadLocal的时候也有说到其内部类ThreadLocalMap,ThreadLocal的操作实际上都是围绕着ThreadLocalMap展开的。
ThreadLocalMap是ThreadLocal静态内部类,虽然没有实现Map接口,但是用类似于HashMap的方式独立的实现了Map的功能,其内部的Entry也是独立实现的。下面我们就来详细介绍一下。
5.1 基本内部结构
5.1.1 成员变量
其中的成员变量的功能和HashMap类似。INITIAL_CAPACITY为ThreadLocalMap的初始容量, table是一个存放数据的Entry数组,size代表ThreadLocalMap中的存储的实际数量,threshold代表需要扩容时的阈值。
/**
* 初始容量 —— 必须是2的整次幂
*/
private static final int INITIAL_CAPACITY = 16;
/**
* 存放数据的 table,Entry类型的数组,Entry的定义在下面分析
* 根据需要调整大小。table.length必须始终为2的幂。
*/
private Entry[] table;
/**
* table数组里面 entrys 的个数,可以用于判断 table 当前使用量是否超过阈值。
*/
private int size = 0;
/**
* 进行扩容的阈值,表使用量大于它的时候进行扩容。
* 默认为 0
*/
private int threshold; // Default to 0
5.1.2 内部类 - Entry
在ThreadLocalMap中也使用了和HashMap中的Entry类似的存储结构,不同的是,ThreadLocalMap里Entry的Key只能是ThreadLocal对象,这里已经在Entry的构造方法中限定死了。
值得注意的是Entry继承自WeakReference ,使用了弱引用,也就是key(ThreadLocal)是弱引用的,其目的是将ThreadLocal对象的生命周期和线程的生命周期解绑,持有对ThreadLocal的弱引用可以使得在没有其他的强引用的时候被回收掉,这样可以避免因为线程得不到销毁导致ThreadLocal对象无法被回收。
/*
* Entry继承WeakReference,并且用ThreadLocal作为key.
* 如果key为null(entry.get() == null),意味着key不再被引用,
* 因此这时候entry也可以从table中清除。
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** 与此ThreadLocal关联的值。 */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
5.1.2 番外篇 - 弱引用和内存泄漏
有一些程序员在使用ThreadLocal的过程中会发现有内存泄漏的情况发生,就认为内存泄漏和这里的Entry中使用了弱引用有关系。其实这种理解是有问题的。下面我们先来了解一下几个概念
- 内存泄漏有关概念
- Memory overflow :内存溢出,没有足够的内存提供申请者使用。
- Memory leak : 内存泄漏是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。内存泄漏的堆积终将导致内存溢出。
- 弱引用相关概念
Java中的引用有4种类型: 强、软、弱、虚。当前这个问题主要涉及到强引用和弱引用:
-
强引用(Strong Reference),就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾回收器就不会回收这种对象。
-
弱引用(Weak Reference),垃圾回收器一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
- 如果key使用强引用
具体参照HashMap内存泄漏
假设在业务代码中使用完了ThreadLocal,ThreadLocal 就被回收了。但是因为在ThreadLocalMap的Entry的Key是强引用了ThreadLocal,造成会造成ThreadLocal无法被回收。
在没有手动删除这个Entry以及CurrentThread依然运行的前提下,始终有强引用链 threadRef->currentThread->threadLocalMap->entry,Entry就不会被回收(Entry中包括了ThreadLocal实例和value),导致Entry内存泄漏。
也就是说,ThreadLocalMap中的key使用了强引用, 是无法完全避免内存泄漏的。
- 如果key使用弱引用
那么ThreadLocalMap中的key使用了弱引用,会出现内存泄漏吗?
此时ThreadLocal的内存图(实线表示强引用,虚线表示弱引用)如下:
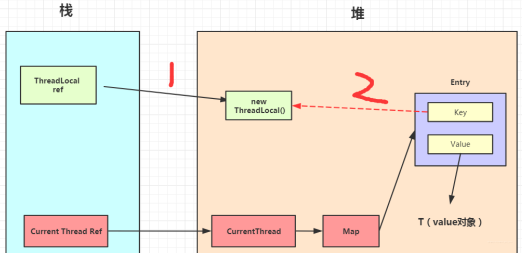
由于ThreadLocalMap只持有ThreadLocal的弱引用,没有任何强引用指向threadlocal实例, 所以threadlocal就可以顺利被gc回收,此时Entry中的key=null。
但是在没有手动删除这个Entry以及CurrentThread依然运行的前提下,也存在有强引用链 threadRef->currentThread->threadLocalMap->entry -> value ,value不会被回收, 而这块value永远不会被访问到了,导致value内存泄漏。
也就是说,ThreadLocalMap中的key使用了弱引用, 也有可能内存泄漏。
-
出现内存泄漏的真实原因
经过上面的比较,我们就会发现,内存泄漏的原因跟
ThreadLocalMap的Key是否使用弱引用是没有关系的。那么内存泄漏的真正原因是什么呢?根据上面的分析,上面发生内存泄漏情况是有前提的:
key使用强引用,当ThreadLocal使用完成时,就会被回收掉,但是因为ThreadLocalMap里的Entry的Key强引用了ThreadLocal救会导致ThreadLocal不能被回收。但是在ThreadLocalMap外部,该ThreadLocal的引用已经没有了,就无法获取到ThreadLocalMap里的Entry的引用,进而发生内存泄漏。key使用弱引用,当ThreadLocal使用完成时,不会像1中那样阻止GC回收,ThreadLocal就会被回收掉。尽管此时ThreadLocal被回收掉,但是其对应的value不会被回收,进而发生内存泄漏。
第一点很好理解,只要在使用完
ThreadLocal,调用其remove方法删除对应的Entry,就能避免内存泄漏。第二点稍微复杂一点, 由于
ThreadLocalMap是Thread的一个属性,被当前线程所引用,所以它的生命周期跟Thread一样长。那么在使用完ThreadLocal的使用,如果当前Thread也随之执行结束,ThreadLocalMap自然也会被gc回收,从根源上避免了内存泄漏。综上,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏。 -
为什么使用弱引用
根据上面的分析, 我们知道了: 无论ThreadLocalMap中的key使用哪种类型引用都无法完全避免内存泄漏,跟使用弱引用没有关系。
要避免内存泄漏有两种方式:
- 使用完
ThreadLocal,调用其remove方法删除对应的Entry - 使用完
ThreadLocal,当前Thread也随之运行结束
相对第一种方式,第二种方式显然更不好控制,特别是使用线程池的时候,线程结束是不会销毁的。
也就是说,只要记得在使用完ThreadLocal及时的调用remove,无论key是强引用还是弱引用都不会有问题。那么为什么key要用弱引用呢?
事实上,在ThreadLocalMap中的set/getEntry方法中,会对key为null(也即是ThreadLocal为null)进行判断,如果为null的话,就会对value置为null的。
这就意味着使用完ThreadLocal,CurrentThread依然运行的前提下,就算忘记调用remove方法,弱引用比强引用可以多一层保障:弱引用的ThreadLocal会被回收,对应的value在下一次ThreadLocalMap调用set,get,remove中的任一方法的时候会被清除,从而避免内存泄漏。
5.3 ThreadLocalMap-hash冲突的解决
(1)首先从ThreadLocal的set()方法入手
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocal.ThreadLocalMap map = getMap(t);
if (map != null)
//调用了ThreadLocalMap的set方法
map.set(this, value);
else
createMap(t, value);
}
ThreadLocal.ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
//调用了ThreadLocalMap的构造方法
t.threadLocals = new ThreadLocal.ThreadLocalMap(this, firstValue);
}
这个set方法我们上面已经分析过了,作用是设置当前线程绑定的局部变量 :
A. 首先获取当前线程,并根据当前线程获取一个Map
B. 如果获取的Map不为空,则将参数设置到Map中(当前ThreadLocal的引用作为key)
(这里调用了(这里调用了ThreadLocalMap的构造方法)的set方法)
C. 如果Map为空,则给该线程创建 Map,并设置初始值
(这里调用了ThreadLocalMap的构造方法)
这段代码有两个地方分别涉及到ThreadLocalMap的两个方法, 我们接着分析这两个方法。
**(2)构造方法ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) **
/*
* firstKey : 本ThreadLocal实例(this)
* firstValue : 要保存的线程本地变量
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//初始化table
table = new ThreadLocal.ThreadLocalMap.Entry[INITIAL_CAPACITY];
//计算索引(重点代码)
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//设置值
table[i] = new ThreadLocal.ThreadLocalMap.Entry(firstKey, firstValue);
size = 1;
//设置阈值
setThreshold(INITIAL_CAPACITY);
}
构造函数首先创建一个长度为16的Entry数组,然后计算出firstKey对应的索引,然后存储到table中,并设置size和threshold。
重点分析: int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1)。
a. 关于firstKey.threadLocalHashCode:
private final int threadLocalHashCode = nextHashCode();
//AtomicInteger是一个提供原子操作的Integer类,通过线程安全的方式操作加减,适合高并发情况下的使用
private static AtomicInteger nextHashCode = new AtomicInteger();
//特殊的hash值
private static final int HASH_INCREMENT = 0x61c88647;
//计算下一个HashCode
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
这里定义了一个AtomicInteger类型,每次获取当前值并加上HASH_INCREMENT,HASH_INCREMENT = 0x61c88647,这个值跟斐波那契数列(黄金分割数)有关,其主要目的就是为了让哈希码能均匀的分布在2的n次方的数组里, 也就是Entry[] table中,这样做可以尽量避免hash冲突。
b. 关于& (INITIAL_CAPACITY - 1)
计算hash的时候里面采用了hashCode & (size - 1)的算法,这相当于取模运算hashCode % size的一个更高效的实现。正是因为这种算法,我们要求size必须是2的整次幂,这也能保证在索引不越界的前提下,使得hash发生冲突的次数减小。
(3)ThreadLocalMap中的set方法
private void set(ThreadLocal<?> key, Object value) {
ThreadLocal.ThreadLocalMap.Entry[] tab = table;
int len = tab.length;
//计算索引(重点代码,刚才分析过了)
int i = key.threadLocalHashCode & (len-1);
/**
* 使用线性探测法查找元素(重点代码)
*/
for (ThreadLocal.ThreadLocalMap.Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
//ThreadLocal 对应的 key 存在,直接覆盖之前的值
if (k == key) {
e.value = value;
return;
}
// key为 null,但是value不为 null,说明之前的 ThreadLocal 对象已经被回收了,
// 当前数组中的 Entry 是一个陈旧(stale)的元素
if (k == null) {
//用新元素替换陈旧的元素,这个方法进行了不少的垃圾清理动作,防止内存泄漏
replaceStaleEntry(key, value, i);
return;
}
}
//ThreadLocal对应的key不存在并且没有找到陈旧的元素,则在空元素的位置创建一个新的Entry。
tab[i] = new Entry(key, value);
int sz = ++size;
/**
* cleanSomeSlots用于清除那些e.get()==null的元素,
* 这种数据key关联的对象已经被回收,所以这个Entry(table[index])可以被置null。
* 如果没有清除任何entry,并且当前使用量达到了负载因子所定义(长度的2/3),那么进行
* rehash(执行一次全表的扫描清理工作)
**/
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
/**
* 获取环形数组的下一个索引
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
代码执行流程:
A. 首先还是根据key计算出索引 i,然后查找i位置上的Entry,
B. 若是Entry已经存在并且key等于传入的key,那么这时候直接给这个Entry赋新的value值,
C. 若是Entry存在,但是key为null,则调用replaceStaleEntry来更换这个key为空的Entry,
D. 不断循环检测,直到遇到为null的地方,这时候要是还没在循环过程中return,那么就在这个null的位置新建一个Entry,并且插入,同时size增加1。
最后调用cleanSomeSlots,清理key为null的Entry,最后返回是否清理了Entry,接下来再判断sz 是否>= threshold达到了rehash的条件,达到的话就会调用rehash函数执行一次全表的扫描清理。
重点分析 : ThreadLocalMap使用线性探测法来解决哈希冲突的。
该方法一次探测下一个地址,直到有空的地址后插入,若整个空间都找不到空余的地址,则产生溢出。
举个例子,假设当前table长度为16,也就是说如果计算出来key的hash值为14,如果table[14]上已经有值,并且其key与当前key不一致,那么就发生了hash冲突,这个时候将14加1得到15,取table[15]进行判断,这个时候如果还是冲突会回到0,取table[0],以此类推,直到可以插入。
按照上面的描述,可以把Entry[] table看成一个环形数组。
6. 引用
HashMap内存泄漏
ThreadLocal全面解析
面试官:知道ThreadLocal嘛?谈谈你对它的理解?(基于jdk1.8)
Java8 中文API文档
Spring学习笔记
















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









