







博主这个系列是根据李沐老师的路线更新,自从看了现在的GPT-4与国内的文心一言对比,博主越来越觉得要接触新技术就需要从国外来了解一手资料就需要阅读英文文献,李沐老师的课正好有这个契机来让我完成这个想法。博主会在其中加入英译汉的版本,基本上就是有四级的水平来锻炼自己的能力。
数据(一)
数据获取
Flow chart for data acquisition(数据采集流程图)
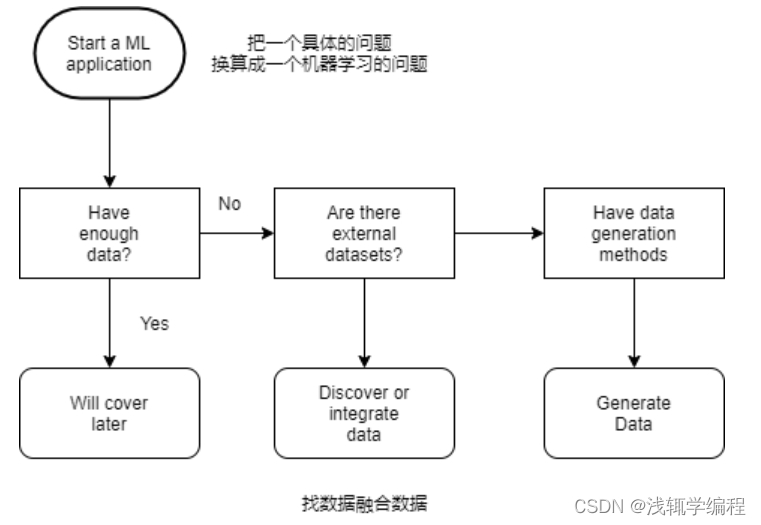
Discover what data is available
-
ldentify existing datasets(数据集)
-
Find benchmark(基准) datasets to evaluate(评价) a new idea
-
E.g.A diverse(不同) set(多样化) of small to medium datasets for a new hyper-parameter tuning algorithm(超参数调优算法)
-
E.g. Large scale datasets for a very big deep neural network(非常大的深度神经网络的大规模数据集)
-
-
Collect new data
-
E.g.driving videos covering different driving scenarios(涵盖不同驾驶场景的驾驶视频)
-
Popular ML datasets
-
MNIST:digits written by employees of the US Census Bureau(r人手写收集的数据集)
-
ImageNet:millions of images from image search engines(图片搜索引擎得到的)
-
AudioSet:YouTube sound clips for sound classification(YouTube上的音频切片)
-
LibriSpeech:1000 hours of English speech from audiobook(有声读物)
-
Kinetics:YouTube videos clips for human actions classification
-
KITTl:traffic scenarios recorded by cameras and other sensors(无人驾驶通过sensor记录下来的的数据集)
-
Amazon Review:customer reviews and from Amazon online shopping(亚马逊用户评论)
-
SQuAD:question-answer pairs derived from Wikipedia(抽出问题答案)
做数据集的两大常用办法
一.爬网站
二.采集数据(手写数字,无人驾驶)通过人的行为去记录数据
Where to Find Datasets
自己手动做数据集,去哪里找数据?
-
Paperswithcodes Datasets:academic datasets with leaderboard(学术方面的数据集)
-
Kaggle datasets:ML datasets uploaded by data scientists(科学家上传的)
-
Google Dataset search:search datasets in the Web
-
Various toolkits datasets:tensorflow,huggingface
-
Various conference/company ML competitions
-
Open Data on AWS:100+large-scale raw data
-
Data lakes in your own organization
Datasets Comparison(比较)
| 优点 | 缺点 | |
|---|---|---|
| Academic datasets(学术数据集) | 干净,适当的难度 | 选择也有限,简化,通常规模较小 |
| Competition datasets(竞赛数据集) | 更接近真实的 机器应用程序 | 仍然简化,仅适用于热门话题 |
| Raw Data(原始数据集) | 极大的灵活性 | 需要付出很多努力过程 |
-
You often need to deal with raw data in industrial settings(您经常需要在工业环境中处理原始数据)
-
Data curation can be a big projection involving multiple teams Processing pipeline,storage,legal issue,privacy,..(数据管理可能是一个涉及多个团队的大投影处理管道,存储,法律问题,隐私,..)
Data Integration(集成)
-
Combine data from multiple sources into a coherent dataset(将来自多个来源的数据合并到一个连贯的数据集中)
-
Product data is often stored in multiple tables(产品数据通常存储在多个表中)
-
E.g.a table for house information,a table for sales,a table for listing agents
-
-
Join tables by keys, which are often entity IDs

表之间的级联查找 -
Key issues: identify IDs, missing rows, redundant columns, value conflicts(识别 ID、缺少行、冗余列,值冲突)
总结
-
Finding the right data is challenging
-
Raw data in industrial settings VS academic datasets
-
Data integration combines data from multiple sources
-
Data augmentation a common practice
-
Synthesizing data is getting popular
-
我们找到一个合适的数据集是有挑战性的
-
上文讲述到工业届是原始的数据,学术界一般都是已经处理好的数据
-
从不同的地方收集数据,整合归纳好一个信息丰富的数据集
-
做数据增强
-
人工合成数据















 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









