







AlexNet8原理
AlexNet是一种深度卷积神经网络,由Alex Krizhevsky等人在2012年提出,它是第一个在ImageNet比赛中取得显著优势的卷积神经网络。AlexNet有着比LeNet5更深、更宽的网络结构,并且采用了Dropout、ReLU等多种技术来防止过拟合,提高模型的泛化能力。
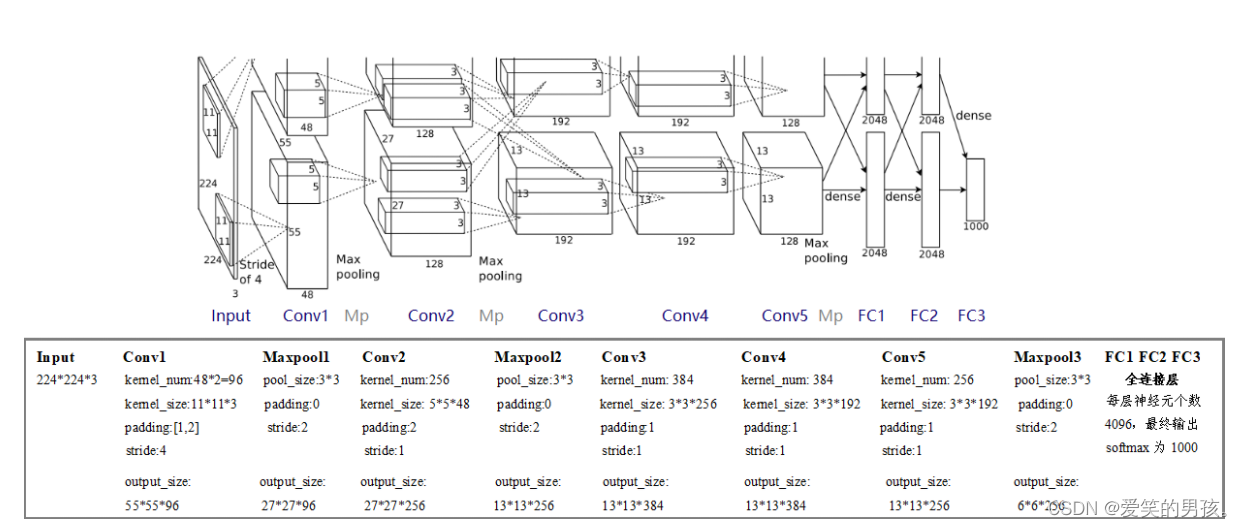
AlexNet的网络结构包含了8个层:
-
输入层:224*224的彩色图像。
-
第一层卷积层:96个卷积核,每个卷积核的大小为11*11。采用ReLU作为激活函数。
-
第一层池化层:3*3的最大池化,步长为2。
-
第二层卷积层:256个卷积核,每个卷积核的大小为5*5。采用ReLU作为激活函数。
-
第二层池化层:3*3的最大池化,步长为2。
-
第三层卷积层:384个卷积核,每个卷积核的大小为3*3。采用ReLU作为激活函数。
-
第四层卷积层:384个卷积核,每个卷积核的大小为3*3。采用ReLU作为激活函数。
-
第五层卷积层:256个卷积核,每个卷积核的大小为3*3。采用ReLU作为激活函数。
-
全连接层1:4096个神经元,采用ReLU作为激活函数。采用Dropout技术来防止过拟合。
-
全连接层2:4096个神经元,采用ReLU作为激活函数。采用Dropout技术来防止过拟合。
-
输出层:1000个神经元,采用softmax函数作为激活函数,用于分类。
AlexNet在ImageNet比赛中取得了远超其他模型的成绩,将分类误差降低到了16.4%!。(MISSING)它的成功启示了后来更加深入的卷积神经网络的发展。AlexNet的结构和思想成为了现代卷积神经网络的基础,它对于深度学习的发展具有重要的推动作用。
AlexNet8源码(tensorflow版)
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
# np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
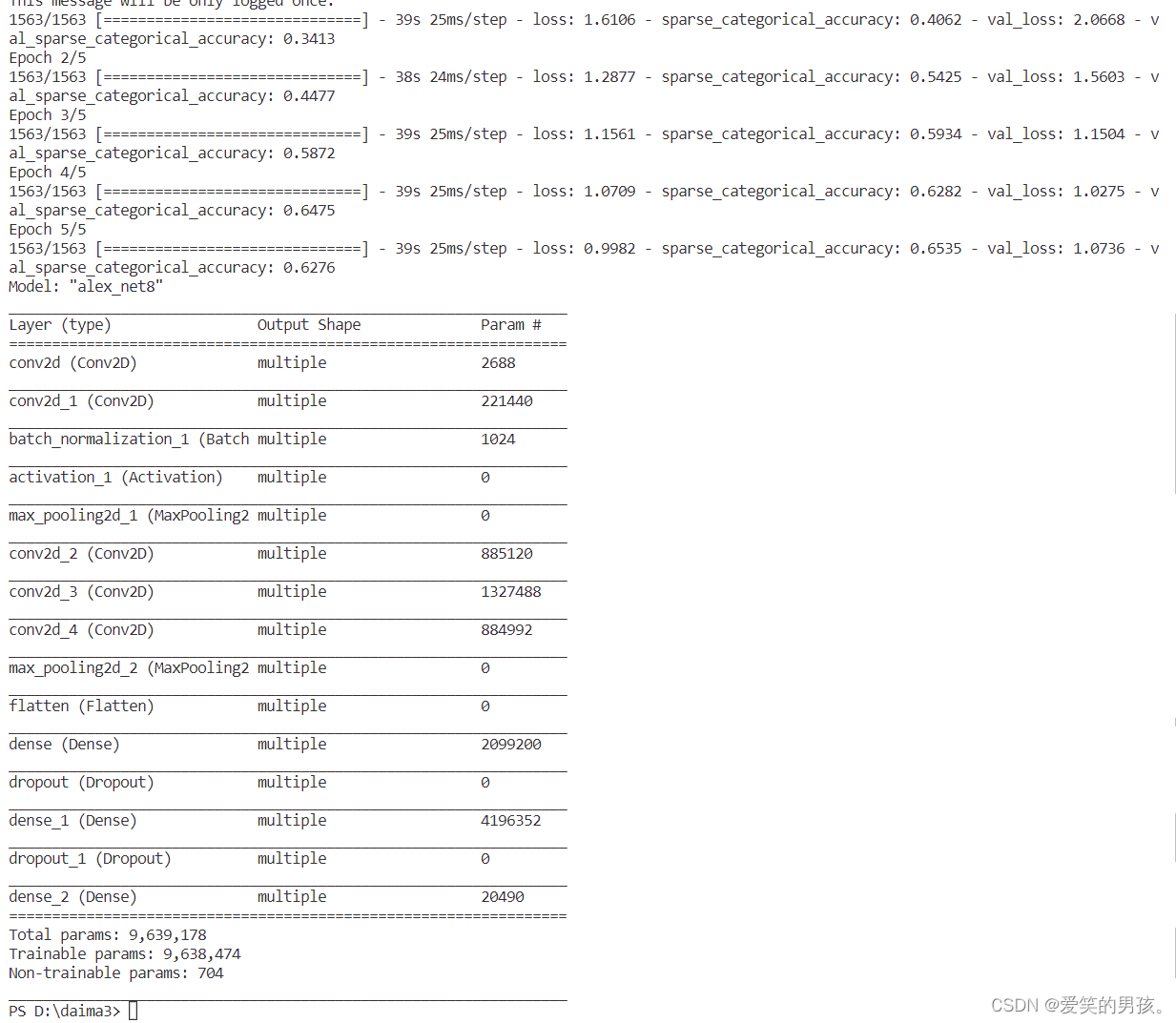
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
############################################### show ###############################################
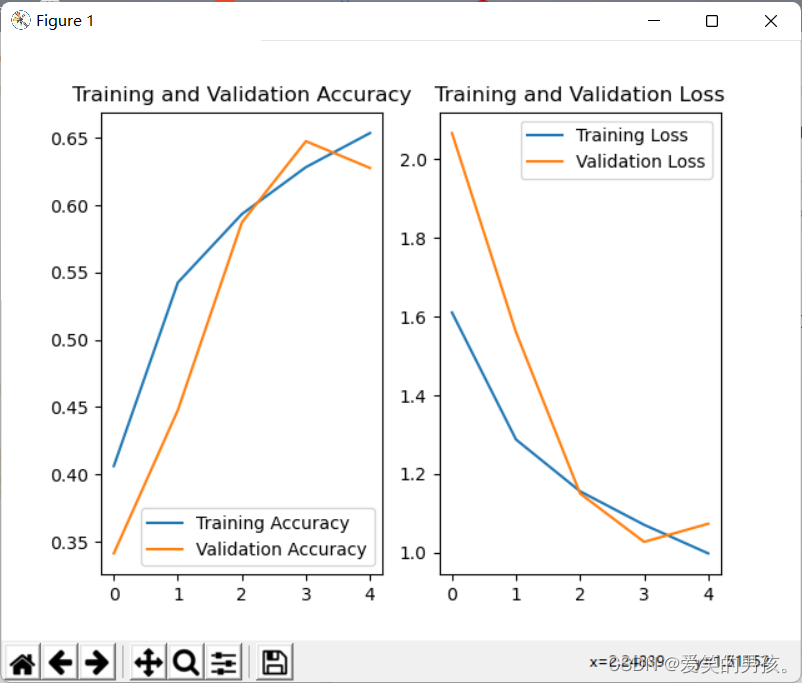
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
训练5个epoch的效果
















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











