









Scala
1. Scala概述
1.1 什么是scala
Scala是一种多范式的编程语言 , 其设计的初衷是要集成面向对象编程和函数式编程的各种特性 . Scala运行于Java平台(Java虚拟机) , 并兼容现有的Java程序 . 详情查看官网http://www.scala-lang.org
1.2 为什么要学Scala
- 优雅
- 速度快 : 表达能力强 ,一行代码抵得上Java多行,开发速度快;Scala是静态编译的,所以和JRuby,Groovy比起来速度会快很多。
- 能融合到Hadoop生态圈
3 Scala编译器安装
3.1 安装JDK
因为Scala是运行在JVM平台上的 , 所以安装Scala之前要安装JDK
3.2 安装Scala
3.2.1 Windows安装Scala编译器
访问Scala官网http://www.scala-lang.org/下载Scala编译器安装包 , 目前最新版本是2.12.x , 这里下载scala-2.11.8.msi点击下一步就可以了(会自动配置环境变量) . 也可以下载scala-2.11.8.zip , 解压后配置上环境变量就可以了 .
3.2.2 Linux安装Scala编译器
下载Scala地址 https://www.scala-lang.org/download/2.11.8.html
然后解压到Scala指定目录
配置环境变量 , 将Scala加入到PATH中
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin:/usr/java/scala-2.11.8/bin
3.2.3 Scala开发工具安装
目前目前Scala的开发工具主要有两种:Eclipse和IDEA,这两个开发工具都有相应的Scala插件,如果使用Eclipse,直接到Scala官网下载即可http://scala-ide.org/download/sdk.html
由于IDEA的Scala插件更优秀,大多数Scala程序员都选择IDEA,可以到http://www.jetbrains.com/idea/download/下载,点击下一步安装即可,安装时如果有网络可以选择在线安装Scala插件。
这里我们使用离线安装Scala插件 :
- 安装IDEA,点击下一步即可
- 下载IEDA的scala插件
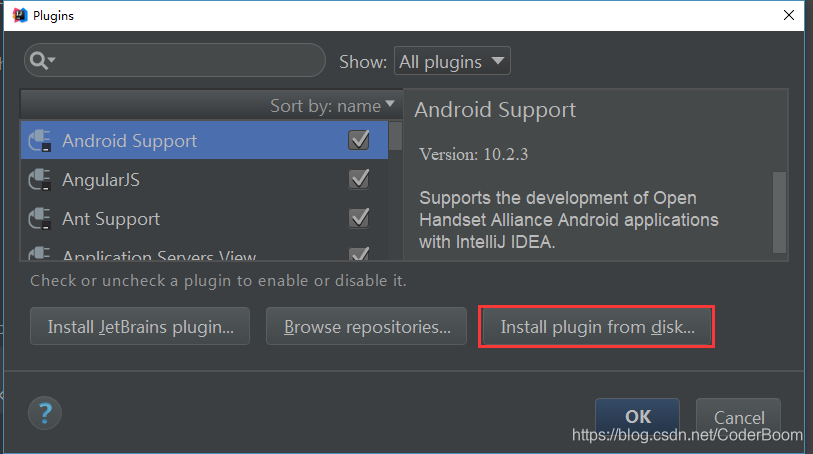
- 1.安装Scala插件:
Configure -> Plugins -> Install plugin from disk -> 选择Scala插件 -> OK -> 重启IDEA



4. Scala基础
4.1 声明变量
//使用val定义的变量值是不可变的,相当于java里用final修饰的变量
val i = 1
//使用var定义的变量是可变得,在Scala中鼓励使用val
var s = "hello"
//Scala编译器会自动推断变量的类型,必要的时候可以指定类型
//变量名在前,类型在后
val str: String = "itcast"
4.2 常用类型
Scala 和 Java 一样,有 7 种数值类型 Byte、Char、Short、Int、Long、Float、Double类型和 1 个 Boolean 类型。
4.3 条件表达式
就是在申明一个变量的时候,通过加上一些if elseif else这些逻辑,跟java基本上是一样
val a=1
val b=if(a<0) -1 else 1
val b=if(a<0) -1 else "itcast"
val b=if(a<0) -1 else if(a==1) 0 else "itcast"
4.4 块表达式
定义变量时用 {} 包含一系列表达式,其中块的最后一个表达式的值就是块的值。
val b={
val c=a+1
val d=c+1
100
}
4.5 循环
在 scala 中有 for 循环和 while 循环,用 for 循环比较多
for 循环语法结构: for (i <- 表达式/数组/集合)
for(i <- 1 to 10){
if(i%2==0){
println(i)
}
}
for(i <- 1 to 10 if i%2==0)println(i)
for(i <- 1 to 3 ; j <- 1 to 3 if i!=j) println(i+10*j)
for(i <- 1 to 9; j <- 1 to i){
print(i+"*"+j+"="+i*j+"\t")
if(i==j){
println()
}
}
//for 推导式:如果 for 循环的循环体以 yield 开始,则该循环会构建出一个集合
//每次迭代生成集合中的一个值
for(i <- a if i%2==0) yield i*10
while循环语法结构 : while(返回结果是boolean类型的表达式)
4.6 调用方法和函数
Scala 中的+ - * / %等操作符的作用与 Java 一样,位操作符& | ^ >> <<也一样。只是有一点特别的:这些操作符实际上是方法。例如:
a + b 是如下方法调用的简写: a.+(b)
a 方法 b 可以写成a.方法(b)
4.7 定义方法和函数
- 定义方法
def m1(x:Int,y:Int):Int=x+y
m1(1,2)

方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归函数,必须指定返回类型
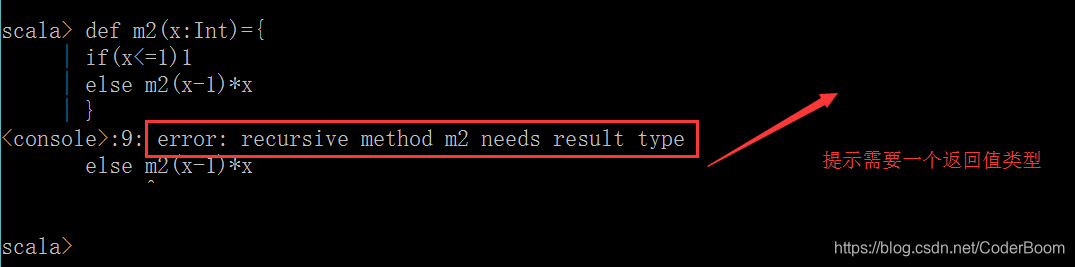
- 定义函数
在函数式编程语言中,函数是“头等公民”,它可以像任何其他数据类型一样被传递和操作,函数是一个对象,继承自 FuctionN , 当函数中参数是几 , N就是几 , N的最大值为22
函数对象有 apply、curried、toString、tupled 这些方法。而方法不具有这些特性。
val f1=(x:Int,y:Int)=>x+y
f1(1,2)
将函数作为参数传入到方法中
def m2(f:(Int,Int) => Int)=f(2,6)
val f2 = (x:Int,y:Int) => x-y
m2(f2)

将方法转成函数
如果想把方法转换成一个函数,可以用方法名跟上下划线的方式
def m1(x:Int,y:Int):Int = x*y
val f1 = m1 _

tips: 方法和函数的区别
- 函数是一个对象,这个函数有N个参数,就继承成FunctionN类
- 它具备该对象中的一些方法
- 方法就是对象中的方法,它是不具备函数这种特性。
- 方法转换成函数
函数= 方法 _关于下划线在scala有很多不同的应用场景
5. 数组、映射、元组、集合
5.1 数组
-
定长数组
- 格式 :
val arr=new Array[T](数组长度)/val arr=Array(1,2,3,4,5)
val array=new Array[Int](5) val array=Array(1,2,3,4,5) //获取元素 array(下标)--------java是array[下标] 例子 : array(0) ===> 1 //定长数组申明好之后它的长度是不可以发生改变--------就是不可以添加元素和删除元素 //定长数组追加元素后是形成了一个新的数组 , 原数组没有改变 - 格式 :
-
变长数组
- 格式 :
val arr = ArrayBuffer[T]() - 注意需要导包 :
import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ListBuffer val list=ListBuffer(1) //添加元素 list +=2 list.append(3) list.append(4,5) list ++=List(6,7) list ++=ListBuffer(8,9) //在数组某个位置插入元素用 insert,从某下标插入 ab.insert(0, -1, 0) //删除 list -=1 list --=List(2,3) list --=ListBuffer(4,5,6) - 格式 :
-
遍历数组
- 增强 for 循环 :
for( i <- array) println(i) - until 会生成脚标,0 until 10
包含 0 不包含 10:for(i <- 0 until array.length) println(array(i))/for(i <- (0 until array.length).reverse) println(array(i))

val arr = Array (1,2,3,4,5,6,7,8) //增强 for 循环 for(i <- arr) println (i)//=>(1,2,3,4,5,6,7,8) //until 会生成一个 Range //reverse 是将前面生成的 Range 反转 for(i <- (0 until arr.length).reverse) println (arr(i))//==>(8,7,6,5,4,3,2,1) } - 增强 for 循环 :
-
数组转换
yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变

//定义一个数组
val arr = Array (1, 2, 3, 4, 5, 6, 7, 8, 9)
//将偶数取出乘以 10 后再生成一个新的数组
val res = for (e <- arr if e % 2 == 0) yie ld e * 10
println (res.toBuffer)
//更高级的写法
//filter 是过滤,接收一个返回值为 boolean 的函数
//map 相当于将数组中的每一个元素取出来,应用传进去的函数
val r = arr.filter(_ % 2 == 0).map(_ * 10)
println (r.toBuffer)
val array=Array(1,2,3,4,5,6,7,8)
for( i <- array if i %2==0) yield i
for( i <- array if i %2==0) yield i*10
val f1=(x:Int)=>x%2==0
array.filter(f1)
array.filter((x:Int)=>x%2==0)
array.filter(x =>x%2==0)
array.filter( _%2==0)
val f2=(x:Int)=>x*10
array.filter( _%2==0).map(f2)
array.filter( _%2==0).map((x:Int)=>x*10)
array.filter( _%2==0).map(x=>x*10)
array.filter( _%2==0).map(_*10)
tips : 此时
_代表的是数组中每一个元素
-
数组中常用算法
- 定义数组
val arr= Array(2,5,1,4,3) - 求和
sum
arr.sum //==> 15- 求最大值
max
arr.max //==> 5- 求最小值
min
arr.min //==>1- 排序
sorted
arr.sorted //==>(1,2,3,4,5)5.2 映射
- 定义数组
-
映射 : 在Scala中 , 把哈希表这种数据结构叫做映射 .
-
构建映射
- 格式1 :
val map = Map(键 -> 值,键 -> 值,键 -> 值......) - 格式2 : 利用
元组构建 ,val map=Map ((键,值),(键,值),(键,值)......)
- 格式1 :
-

-
获取和修改映射中的值
- 获取映射中的值 :
值 = map(键)
- 获取映射中的值 :
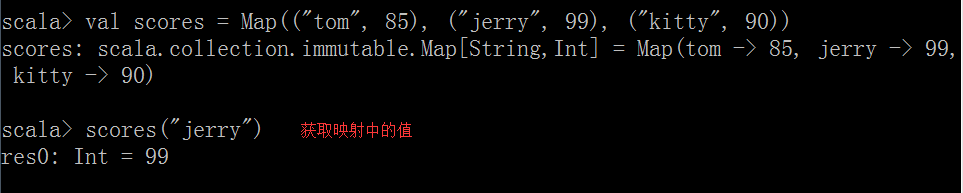
- getOrElse获取 , 会有一个默认值 , 当该元素不存在数组中是生效

tips : 在 Scala 中,有两种 Map,一个是
immutable包下的 Map,该 Map 中的内容不可变;另一个是mutable包下的 Map,该 Map 中的内容可变
- 例子如下
import scala.collection.mutable.HashMap
val hmap=HashMap("zhangsan" -> 30,"lisi" -> 40)
//获取key对应的value
hmap(键)
hmap.getOrElse(键,默认值)
//添加和更新键值对
hmap+=("wangwu" -> 60)
hmap+=("wangwu" -> 80,"zhaoliu" ->70)
hmap("lisi")=50
//删除
hmap -=("lisi")
hmap.remove("zhangsan")

tips : 通常我们在创建一个集合时会用val这个关键字修饰一个变量(相当于java中的final) , 那么就意味着该变量的引用不可变 , 该引用的内容是不是可变的取决于这个引用指向的集合的类型 .
5.3 元组
-
元组 : 映射是
K/V对偶的集合 , 对偶是元组的最简单形式 , 元组可以装有多个不同类型的值 .- 创建元组
- 元组是不同类型的值的聚集;对偶是最简单的元组
- 元组表示通过将不同的值用小括号括起来,即表示元组
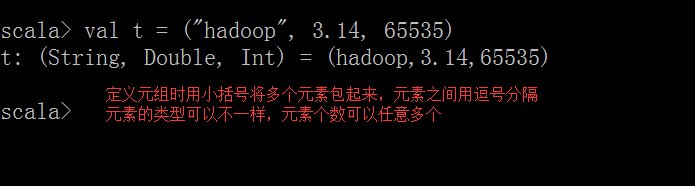
- 格式 :
val tuple ={元素,元素......}
- 创建元组
val t = ("hadoop",3.14,65535)
-
获取元组中的值
- 格式 : 使用下划线加脚标 ==>
t._1 , t._2 , t._3 ...... - 注意 : 元组中的元素脚标是从1开始的
- 格式 : 使用下划线加脚标 ==>

-
将对偶的集合转换成映射
- 使用
toMap方法
val arr = Array(("tom",88),("jerry",95)) arr.toMap //==> Map(tom -> 88,jerry -> 95) - 使用
-
拉链操作
- 使用
zip命令可以将多个值绑定在一起
- 使用

5.4 集合
Scala 的集合有三大类:序列 Seq、Set、映射 Map,所有的集合都扩展自 Iterable特质,在Scala中集合有可变(mutable)和不可变(immutable)两种类型,immutable类型的集合初始化后就不能改变了(注意与 val 修饰的变量进行区别)。
在包名后面的
_表示当前包下的所有依赖
-
List
- 不可变的序列
import scala.collection.immutable._, 默认的
在 Scala 中列表要么为空(Nil 表示空列表) 要么是
一个 head 元素加上一个 tail 列表。即除了head元素之外的都是tail列表9 :: List(5, 2)
::操作符是将给定的头和尾创建一个新的列表注意:
::操作符是右结合的,如 9 :: 5 :: 2 :: Nil 相当于 9 :: (5 :: (2 :: Nil))- list中常用的操作符 : 即类似于方法
+: (elem: A): List[A] 在列表的头部添加一个元素 :: (x: A): List[A] 在列表的头部添加一个元素 :+ (elem: A): List[A] 在列表的尾部添加一个元素 ++[B](that: GenTraversableOnce[B]): List[B] 从列表的尾部添加 另外一个列表 ::: (prefix: List[A]): List[A] 在列表的头部添加另外一个列表 val left = List(1,2,3) val right = List(4,5,6) //以下操作等价 left ++ right // List(1,2,3,4,5,6) right.:::(left) // List(1,2,3,4,5,6) //以下操作等价 0 +: left //List(0,1,2,3) left.+:(0) //List(0,1,2,3) //以下操作等价 left :+ 4 //List(1,2,3,4) left.:+(4) //List(1,2,3,4) //以下操作等价 0 :: left //List(0,1,2,3) left.::(0) //List(0,1,2,3)exmple :
/* * 不可变 List 集合操作 */ object ImmutListDemo { def main(args: Array[String]) { //创建一个不可变的集合 val lst1 = List(1,2,3) //补充:另一种定义 list 方法 val other_lst=2::Nil //获取集合的第一个元素 val first=lst1.head //获取集合中除第一个元素外的其他元素集合, val tail=lst1.tail //补充:其中如果 List 中只有一个元素,那么它的 head 就是这个元素,它的 tail 就是 Nil; println(other_lst.head+"----"+other_lst.tail) //将 0 插入到 lst1 的前面生成一个新的 List val lst2 = 0 :: lst1 val lst3 = lst1.::(0) val lst4 = 0 +: lst1 val lst5 = lst1.+:(0) //将一个元素添加到 lst1 的后面产生一个新的集合 val lst6 = lst1 :+ 3 val lst0 = List(4,5,6) //将 2 个 list 合并成一个新的 List val lst7 = lst1 ++ lst0 //将 lst0 插入到 lst1 前面生成一个新的集合 val lst8 = lst1 ++: lst0 //将 lst0 插入到 lst1 前面生成一个新的集合 val lst9 = lst1.:::(lst0) println(other_lst) println(lst1) println(first) println(tail) println(lst2) println(lst3) println(lst4) println(lst5) println(lst6) println(lst7) println(lst8) println(lst9) } }- 可变的序列 :
import scala.collection.mutable._ - 可变和不可变操作大致一样 , 除了能否对List进行增删改之外
example
import scala.collection.mutable.ListBuffer object MutListDemo extends App{ val list=ListBuffer(1) //添加元素 list +=2 list.append(3) list.append(4,5) list ++=List(6,7) list ++=ListBuffer(8,9) //删除 list -=1 list --=List(2,3) list --=ListBuffer(4,5,6) //构建一个可变列表,初始有 3 个元素 1,2,3 val lst0 = ListBuffer[Int](1,2,3) //创建一个空的可变列表 val lst1 = new ListBuffer[Int] //向 lst1 中追加元素,注意:没有生成新的集合 lst1 += 4 lst1.append(5) //将 lst1 中的元素添加到 lst0 中, 注意:没有生成新的集合 lst0 ++= lst1 //将 lst0 和 lst1 合并成一个新的 ListBuffer 注意:生成了一个集合 val lst2= lst0 ++ lst1 //将元素追加到 lst0 的后面生成一个新的集合 val lst3 = lst0 :+ 5 //删除元素,注意:没有生成新的集合 val lst4 = ListBuffer[Int](1,2,3,4,5) lst4 -= 5 //删除一个集合列表,生成了一个新的集合 val lst5=lst4--List(1,2) //把可变 list 转换成不可变的 list 直接加上 toList val lst6=lst5.toList //把可变 list 转变数组用 toArray val lst7=lst5.toArray println(lst0) println(lst1) println(lst2) println(lst3) println(lst4) println(lst5) println(lst6) println(lst7) }扩展 :
创建一个List
val list0=List(1,7,9,8,0,3,5,4,6,2)- 将list0中的每一个元素乘以10后生成一个新的集合
map - map是一个方法 , 需要一个函数 , 函数的参数是一个Int类型的 , 返回的是自定义的类
- 此处下划线表示list集合中的每一个元素
val list1=list0.map(x=>x*10) / val list1=list0.map(_*10) println("list1==== "+list1)- 将list0中的偶数取出来生成一个新的集合
filter - 也是一个方法 , 方法中需要一个函数 , 函数的参数是一个Int类型 , 返回的是Boolean
val list2=list0.filter(x=>x%2==0) / val list2=list0.filter(_%2==0) println("list2==== "+list2)- 将list0排序后生成一个新的集合
sorted(升序) ,sortBy(Int):B,sortWith(Int,Int) : Boolean
val list3=list0.sorted val list4=list0.sortBy(x=>x)//按照当前list元素自身大小排序 val list5=list0.sortWith((x,y)=>x<y)//根据某一规则排序 , 类似于冒泡 println("list3==== "+list3) println("list4==== "+list4) println("list5==== "+list5) /* list4==== List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) list5==== List(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) list6==== List(9, 8, 7, 6, 5, 4, 3, 2, 1, 0) */- 将list0中的元素4个一组,类型为
Iterator[List[Int]]grouped()==>得到的是迭代器
val list7=list0.grouped(4) println("list7==== "+list7)//list7==== non-empty iterator- 将Iterator转换成List==>
toList
val list8=list7.toList println("list8==== "+list8) //list8==== List(List(1, 7, 9, 8), List(0, 3, 5, 4), List(6, 2))- 将多个list压扁成一个List ===>
flatten
//如果List中还有list , 就可以使用flatten //如下格式 : List(List(1, 7, 9, 8), List(0, 3, 5, 4), List(6, 2)) val list9=list8.flatten println("list9==== "+list9) //转换后格式 : List(1, 7, 9, 8, 0, 3, 5, 4, 6, 2)- 先按空格切分,在压平
flatMap
val lines = List("hello tom hello jerry", "hello jerry", "hello kitty") val result1=lines.flatMap(_.split(" ")) println("result1==== "+result1) //结果 : result1==== List(hello, tom, hello, jerry, hello, jerry, hello, kitty)- 并行计算求和
par指的是多个线程并行工作
val result2=list0.par.sum println("result2==== "+result2)- 化简
reduce, 将非特顺序的二元操作应用到所有元素
val result3=list0.reduce((x,y) => x + y)//x为累加的和,y表示list中的元素 //简写 : list0.reduce(_+_) //第一个下划线表示累加之后的结果 , 第二个下划线表示依次取出的元素 println("result3==== "+result3) //结果 : result3==== 45- 按照特定的顺序
reduceLeft,reduceRight - reduceLeft表示从左往右加 , reduceRight表示从右往左加
val result4 = list0.reduceLeft(_+_)//1+2+3+4 val result5= list0.reduceRight(_+_)//1+(2+(3+4)) println("result4==== "+result4) println("result5==== "+result5) //减法类似- reduce源码分析
val list=List(1,2,3,4) list.reduce((x,y)=>x+y)----->list.reduceLeft((x,y)=>x+y) var first = true var acc=0 for (x <- self) { if (first) { acc = x first = false } else acc = op(acc, x) } 第一次循环: acc=1 first = false 第二次循环: acc=op(1,2)=1+2=3 第三次循环: acc=op(3,3)=3+3=6 第四次循环: acc=op(6,4)=6+4=10- 折叠:有初始值(无特定顺序)
flod(默认初始值)
val result6 = list0.fold(100)((x,y)=>x+y) println("result6==== "+result6) //result6==== 145==>100+45- 折叠:有初始值(有特定顺序)
foldLeft(默认初始值),foldRight(默认初始值)
val result7 = list0.foldLeft(100)((x,y)=>x+y)//100+1+...=145 println("result7==== "+result7) //从右往左 : 1+(...+8+(9+100))=145- 聚合
aggregate(默认初始值), 并行聚合par.aggregate(默认初始值)
val list10= List(List(1, 2, 3), List(4, 5, 6), List(7,8), List(9,0)) val result8 = list10.par.aggregate(10)(_+_.sum,_+_) println("result8==== "+result8) //result8==== 75 or result8==== 85 **具体取决于并行是的线程数 , 有一个就加10** //_.sum表示进行局部求和 ,_+_表示对局部求和的结果再进行累加 //_+_.sum,_+_表示对最终结果进行求和- 获取到参与并行计算的线程
println(list10.par.collect{ case _=>Thread.currentThread().getName }.distinct) //获取并行线程名且去重- 求并集
l1.union(l2)
val l1 = List(5,6,4,7) val l2 = List(1,2,3,4) val r1=l1.union(l2) println("r1=== "+r1) //r1=== List(5, 6, 4, 7, 1, 2, 3, 4)- 求交集
l1.intersect(l2)
val r2=l1.intersect(l2) println("r1=== "+r2) //r1=== List(4)- 求差集
l1.diff(l2)
val r3=l1.diff(l2) println("r3=== "+r3) //r3=== List(5, 6, 7)- reduce扩展
reduceLeft(op), reduceLeft(op), foldLeft(init)(op), foldRight(init)(op) 是将操作应用到同一集合的相邻元素 定义 val list = List(1,2,3,4) #运算# list.reduceLeft(_-_) //1-2-3-4=-8 #运算# list.reduceRight(_-_)//1-(2-(3-4))=-2 #运算# list.foldLeft(0)(_-_)//0-1-2-3-4=-10 #运算# list.foldRight(0)(_-_)//1-(2-(3-(4-0)))=-2 - 不可变的序列
-
查看源码注意事项 :
由于scala开始时源码是不够完整的 , 点击查看源码时 , 右上角会弹出两个选项, 一个是在线下载 , 一个是用本地下载好的 , 我们将官网下载的源码包导入到idea即可 -
Set
- 不可变的 Set
import scala.collection.immutable._
Set 代表一个没有重复元素的集合;将重复元素加入 Set 是没有用的,而且 Set 是不保证插入顺序的,即 Set 中的元素是乱序的。
定义 :
val set=Set(元素,元素,.....)//定义一个不可变的Set集合 scala> val set =Set(1,2,3,4,5,6,7) set: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 4) //元素个数 scala> set.size res0: Int = 7 //取集合最小值 scala> set.min res1: Int = 1 //取集合最大值 scala> set.max res2: Int = 7 //将元素和set1合并生成一个新的set,原有set不变 scala> set + 8 res3: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 8, 4) scala> val set1=Set(7,8,9) set1: scala.collection.immutable.Set[Int] = Set(7, 8, 9) //两个集合的交集 scala> set & set1 res4: scala.collection.immutable.Set[Int] = Set(7) //两个集合的并集 scala> set ++ set1 res5: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 9, 2, 7, 3, 8, 4) //在第一个set基础上去掉第二个set中存在的元素 scala> set -- set1 res6: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4) //返回第一个不同于第二个set的元素集合 scala> set &~ set1 res7: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4) //计算符合条件的元素个数 scala> set.count(_ >5) res8: Int = 2 /返回第一个不同于第二个的元素集合 scala> set.diff(set1) res9: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4) /返回第一个不同于第二个的元素集合 scala> set1.diff(set) res10: scala.collection.immutable.Set[Int] = Set(8, 9) //取子set(2,5为元素位置, 从0开始,包含头不包含尾) scala> set.slice(2,5) res11: scala.collection.immutable.Set[Int] = Set(6, 2, 7) //迭代所有的子set,取指定的个数组合 scala> set1.subsets(2).foreach(x=>println(x)) Set(7, 8) Set(7, 9) Set(8, 9)- 可变的 Set
import scala.collection.mutable._
//导入包 scala> import scala.collection.mutable import scala.collection.mutable //定义一个可变的 Set scala> val set1=new HashSet[Int]() set1: scala.collection.mutable.HashSet[Int] = Set() 北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090 25 //添加元素 scala> set1 += 1 res1: set1.type = Set(1) //添加元素 add 等价于+= scala> set1.add(2) res2: Boolean = true scala> set1 res3: scala.collection.mutable.HashSet[Int] = Set(1, 2) //向集合中添加元素集合 scala> set1 ++=Set(1,4,5) res5: set1.type = Set(1, 5, 2, 4) //删除一个元素 scala> set1 -=5 res6: set1.type = Set(1, 2, 4) //删除一个元素 scala> set1.remove(1) res7: Boolean = true scala> set1 res8: scala.collection.mutable.HashSet[Int] = Set(2, 4) - 不可变的 Set
-
Map
-
不可变的 Map
import scala.collection.immutable._ -
定义Map集合
- 方式1 :
val map = Map(键 -> 值,键 -> 值...) - 方式2 : 利用元组构建
val map=Map((键,值),(键,值).....)
- 方式1 :
-
操作map集合
- 获取值 :
值=map(键) - 原则 : 通过先获取键 , 再获取键对应的值
- 获取值 :
-
遍历Map集合
- 方式一 : 显示所有的key :
imap.keys - 方式二 : 显示所有的key :
imap.keySet - 通过key获取value :
imap("lisi") - 通过key获取value , 有key对应的值则返回 , 否则返回默认的0
imap.getOrElse("zhangsan",0) - 方式一 : 显示所有的key :
-
可变的Map :
import scala.collection.mutable._
import scala.collection.mutable.HashSet val set=HashSet(1,2) //添加元素 set +=3 set.add(4) set++=Set(5,6) set++=HashSet(7,8) //删除元素 set -=3 set.remove(4) set --=Set(5,6) set --=HashSet(7,8) //导入包 scala> import scala.collection.mutable import scala.collection.mutable //定义一个可变的Set scala> val set1=new HashSet[Int]() set1: scala.collection.mutable.HashSet[Int] = Set() //添加元素 scala> set1 += 1 res1: set1.type = Set(1) //添加元素 add等价于+= scala> set1.add(2) res2: Boolean = true scala> set1 res3: scala.collection.mutable.HashSet[Int] = Set(1, 2) //向集合中添加元素集合 scala> set1 ++=Set(1,4,5) res5: set1.type = Set(1, 5, 2, 4) //删除一个元素 scala> set1 -=5 res6: set1.type = Set(1, 2, 4) //删除一个元素 scala> set1.remove(1) res7: Boolean = true scala> set1 res8: scala.collection.mutable.HashSet[Int] = Set(2, 4) -

















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









