







SQL 优化前传:SQL监控与通知
0. 前言
人民生活幸福,经济稳步向前。社会飞速发展,速度如闪电般迅猛。我们开发团队也都成了快男,开发进度远超产品提需求的速度。因此,我们开启了代码优化模式:专门抽出一段时间,对我们当前产品的代码进行优化。
同事们干得热火朝天:有做登录验证优化的,有做卡片优化的,有做代码格式优化的…而我,就接到了半个SQL 优化的任务:在系统层面做业务或SQL监听,为日后SQL优化做准备。
技术选型
一提到SQL监控,毋庸置疑,我们都会首先想到:Druid
经过几小时的奋战,我实现了基本的 Druid 配置、慢业务与慢SQL监听 以及 慢SQL 或慢业务通知到开发者。本文将这个解决过程记录下来,以供总结、回顾以及读者参考。
前提条件
我们的测试环境已集成部分Druid
除了可以对Druid进行配置,由于是系统集成的问题,其它条件都不能变
学习目标
学习Druid 相关概念
学习并使用Druid实现慢SQL或慢业务的监听和通知
至于 Druid 的原理、源码与思想,作为长期任务,日后慢慢学习、积累
注意
由于 Druid 本身作为一个辅助监听SQL等性能的工具,本身会产生一定开销,会影响性能,实际使用中,建议使用多环境对Druid进行配置。尽量不要在生产环境使用!
1. Druid 简述
数据库连接池负责分配、管理和释放数据库连接。通过数据库连接池能明显提高数据库操作的性能。
Druid 是 阿里 提供的一个开源连接池,除了连接池之外,还提供了非常优秀的数据库监控和拓展功能。
Druid 主要包括:
- DruidDriver:代理类Driver,提供FilterChains模式的插件体系。
- DruidDataSource:高效可管理的数据库连接池
- SQLParser:SQL 分析等
我们可以通过Druid实现:
- 数据库监控:即本文的重点实战对象,慢SQL监控
- 替换传统的DBCP等连接池中间件,提供高效、功能强大、可拓展性强的数据库连接池
- SQL执行日志
等等等等。
由于功能强大,Druid被称为Java最好的数据库连接池!
详情请参考:
alibaba-druild-github:https://github.com/alibaba/druid
更多的解决方案,可在上述参考链接的 wiki 寻找官方Q & A。
2. Druid 配置
默认本文读者可自行查询或理清 JAVA版本、SpringBoot版本、以及Druid版本之间的兼容关系,可自行解决自己配置的过程中报错或报红问题,本文取其中一个版本来示例。
pom.xml
<!-- Druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
2.1 Druid yml
yml 参考配置。
以 yml 配置已在注释作了一定程度的详解。如果还是疑问比较多,篇幅有限,请读者自行查阅更多的关于 Druid 的博客等文档。
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
# MySql、PostgreSQL、SqlServer校验
validation-query: select 1
validation-query-timeout: 2000
# 初始化大小、最大、最小
initial-size: 5
max-active: 20
min-idle: 5
# 配置获取连接等待超时的时间
max-wait: 60000
# 默认是false,应用向连接池申请连接时,连接池会判断这条连接是否可用
test-on-borrow: false
# 默认false,当使用完,连接池回收连接的时候会判断该连接是否还可用
test-on-return: false
# 申请连接,且testOnBorrow为false时,判断验证这条连接是否可用
test-while-idle: true
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
# 配置StatViewServlet(监控页面),用于展示Druid的统计信息
stat-view-servlet:
enabled: true
login-username: username
login-password: password
# 配置WebStatFilter,用于采集web关联监控的数据
web-stat-filter:
# 启用WebStatFilter
enabled: true
# 对所有请求进行监控
url-pattern: /*
# 排除静态资源的监控
exclusions: '*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*'
# session统计功能
session-stat-enable: true
# session统计最大数量,默认1000
session-stat-max-count: 10
# 回收线程
remove-abandoned: true
remove-abandoned-timeout-millis: 600
log-abandoned: false
filters: stat,wall
filter:
stat:
# 慢 SQL 监控, 超过 2s的SQL 记录
log-slow-sql: true
slow-sql-millis: 2000
merge-sql: true
# 开启
enabled: true
# 防止SQL 注入
wall:
config:
alter-table-allow: true
2.2 监控效果
经过上一小节的配置,我们已经可以使用 Druid 监控面板了:
启动项目,访问:地址:端口号/druid/login.html
例如localhost:8082/druid.html
进入登录界面:
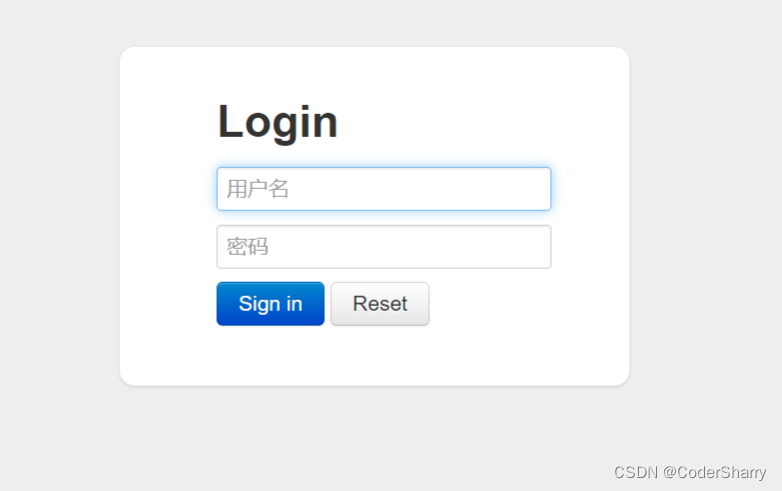
当我们参考上一小节的配置时,已经填写了用户名密码,就是这个用户名密码登录。
SQL监控页面
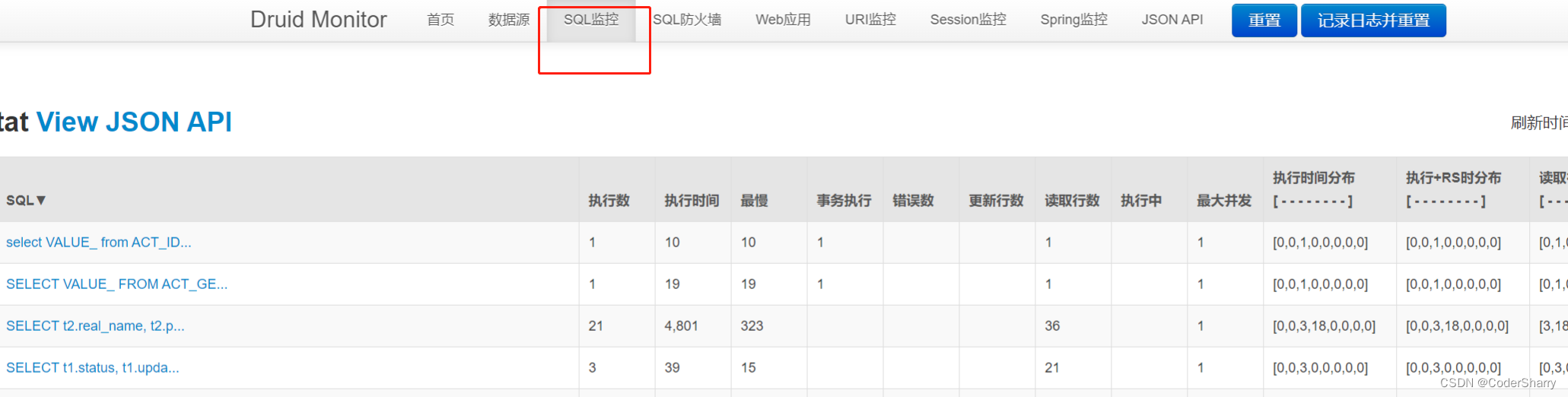
慢SQL监控
进入监控页面后,我们可以自己写一个慢SQL触发监控,查看效果。例如,我们可以尝试写一个全表查询SELECT * FROM或复杂且慢的子查询:
- 触发日志:
2023-07-23 15:14:04.965 ERROR 29480 --- [ XNIO-1 task-1] c.alibaba.druid.filter.stat.StatFilter : slow sql 93007 millis. SELECT id, user_id, dept_id_list, dept_name_all, real_name, longitude, latitude...... - 监控界面截图:

通过以上,我们就已经可以通过 Druid 实现基本的开发/测试环境 慢SQL监控了。
可是,这样可能会产生一些衍生问题,例如,当我们定时任务较多,日志刷新较快的时候,开发者不一定能第一时间注意到慢SQL日志提醒,不一定会第一时间打开 druid 监控面板查看,此时,我们就需要用其他方式将慢SQL第一时间通知到开发者。下面章节,我们将自己写一个Filter ,将信息通知到开发者。
3. Druid 自定义Filter
首先,官方提供了自定义 Filter 实现慢SQL 监控,并 打印到日志的解决方案,详情请见:
官方wiki:https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
官方提供了FilterChains ,但是为什么还是要自定义Filter呢,这是因为,当我使用官方的Filter时,发现可能会影响项目原有的配置。而我们在开头的时候就提到过,由于整体项目较为复杂,我们不能修改别的配置。因此我最终使用自定义Filter 加入到 FilterChians 的方式进行自定义的监听动作。
代码示例
- Spring Filter:
/**
* @author Sharry
* @since 2023/7/20
*/
@Slf4j
public class DruidFilter implements Filter {
/**
* default threshold is 2000 ms
*/
private final static long THRESHOLD_NANO = 2000L * 1000 * 1000;
private final MailUtil mailUtil;
public DruidFilter(MailUtil mailUtil) {
this.mailUtil = mailUtil;
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
// Filter逻辑处理方法
long startTime = System.nanoTime();
filterChain.doFilter(servletRequest, servletResponse);
long endTime = System.nanoTime();
long executeTime = endTime - startTime;
if (executeTime >= THRESHOLD_NANO) {
// 获取请求路径
String url = servletRequest.getServerName() + ":" + servletRequest.getServerPort() + servletRequest.getServletContext().getContextPath() + servletRequest.getServletContext().getRealPath("/");
log.warn("慢SQL或业务整体缓慢 警告: 执行时间{} ms, 详细信息请查阅Druid监控及日志", executeTime / 1000 / 1000);
// 发送邮件
mailUtil.sendSimpleMail("emailaddr@gmail.com", "慢SQL或业务整体缓慢 警告", "执行时间" + executeTime / 1000 / 1000 + " ms, 详细信息请查阅Druid监控及日志, 接口路径"+url);
}
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// Filter初始化方法
}
@Override
public void destroy() {
// Filter销毁方法
}
}
- yml 注册自定义 Filter
# 自定义 filter 配置
filter:
druidFilter:
enabled: true
- 配置类
注意配置类不要影响原本其他任何配置
/**
* Druid filter config, add DruidFilter to filter chains
* @author Sharry
* @since 2023/7/20
*/
@Configuration
public class DruidFilterConfig {
private final MailUtil mailUtil;
@Autowired
public DruidFilterConfig(MailUtil mailUtil) {
this.mailUtil = mailUtil;
}
@Bean
public DruidFilter druidFilter() {
return new DruidFilter(mailUtil);
}
@Bean
@ConditionalOnProperty(prefix = "filter.druidFilter", name = "enabled", havingValue = "true")
public FilterRegistrationBean<Filter> druidFilterRegistration() {
FilterRegistrationBean<Filter> registration = new FilterRegistrationBean<>();
registration.setFilter(druidFilter());
registration.addUrlPatterns("/*");
registration.setName("DruidFilter");
// order of filter
registration.setOrder(1);
return registration;
}
}
通过以上自定义Filter ,我们实现了 慢SQL或慢业务信息 第一时间用邮件发送到开发者。
4. 日志拆分
本次我做SQL监控及通知工作最后一步,便是日志拆分。
日志拆分主要解决的问题:将监听的慢SQL日志,单独用一个Durid日志文件存储,方便开发者查询。本小节结合我们项目实际使用的logback进行示例。
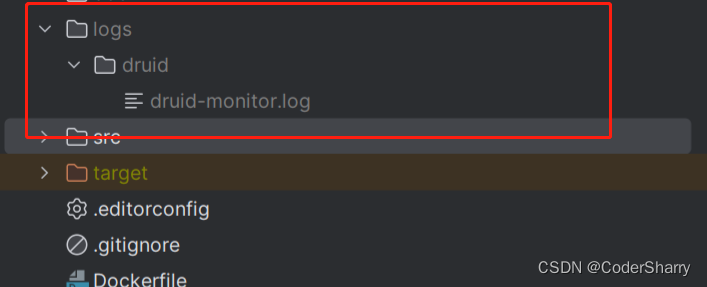
拆分很简单,就是将druid 的日志输出级别及配置信息 配置到 logback xml 配置文件中:
<!-- 配置Druid监控日志输出到单独的文件 -->
<appender name="DRUID" class="ch.qos.logback.core.FileAppender">
<file>logs/druid/druid-monitor.log</file>
<encoder>
<pattern>%date [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="com.alibaba.druid" level="WARN">
<appender-ref ref="DRUID" />
</logger>
效果示例

5. 总结
本文通过一些代码示例,将我最近一次druid 实现SQL监听及通知的解决过程记录了一遍。
主要解决问题:
- Druid 概念的学习,Druid 基本配置
- 不影响原本Spring 配置的情况下,自定义Filter 实现 慢SQL 监听、邮件发送通知
- 日志拆分,方便开发者查看














 4263
4263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









