







情况描述
HeidiSQL管理数据库很方便,但是一条条添加数据比较麻烦。可以先利用Excel文件生成CSV格式数据,然后再进行导入。这样相对来说比较方便。
具体操作
1.打开Excel,写入数据。
列名不一定要和表中的字段名称相同,但是顺序要一样,不然导入的时候数据会出现错误。这里写上列名也是方便自己看。如果数据库里标明了不允许NULL,那就一定要完善数据。
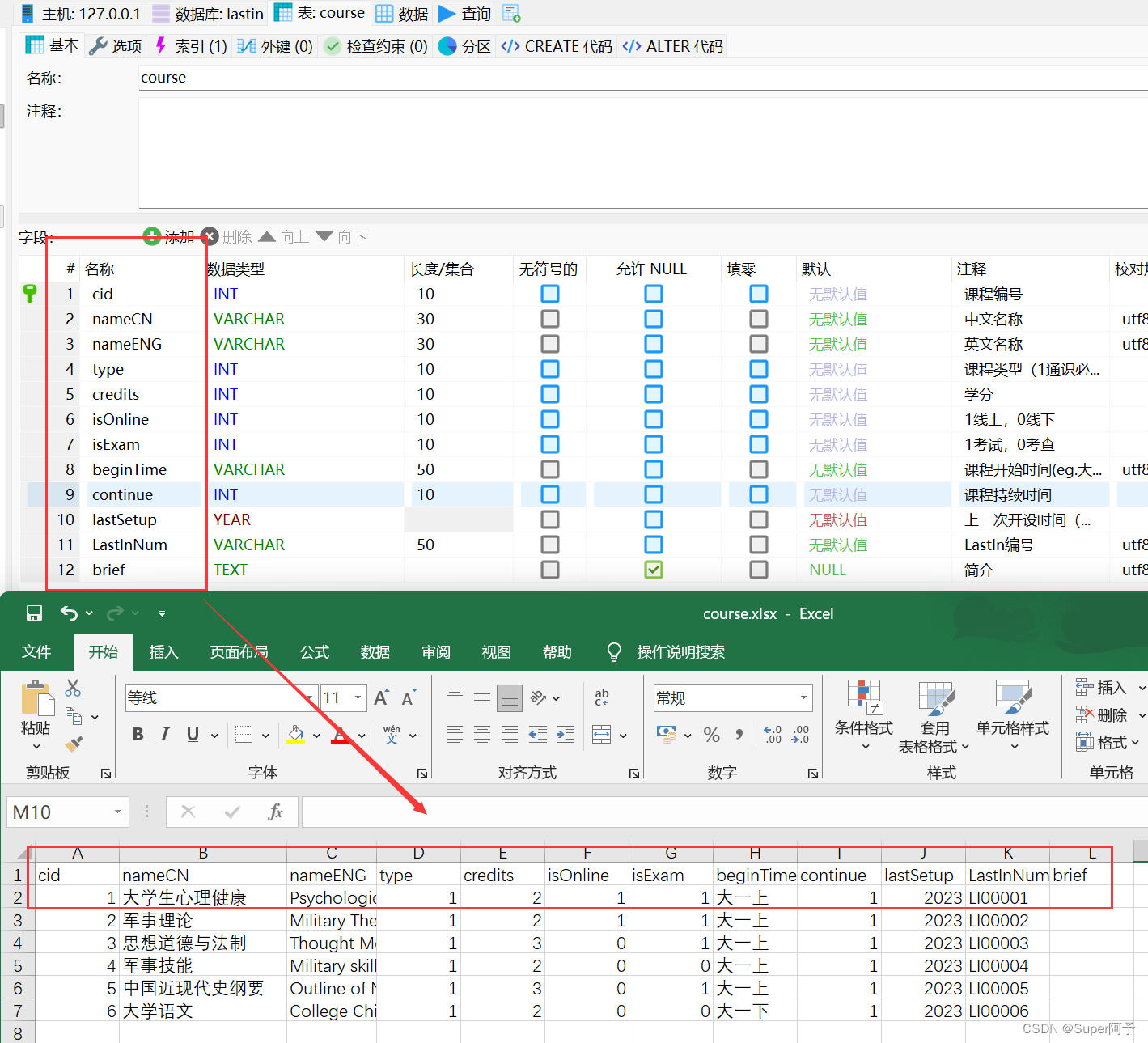
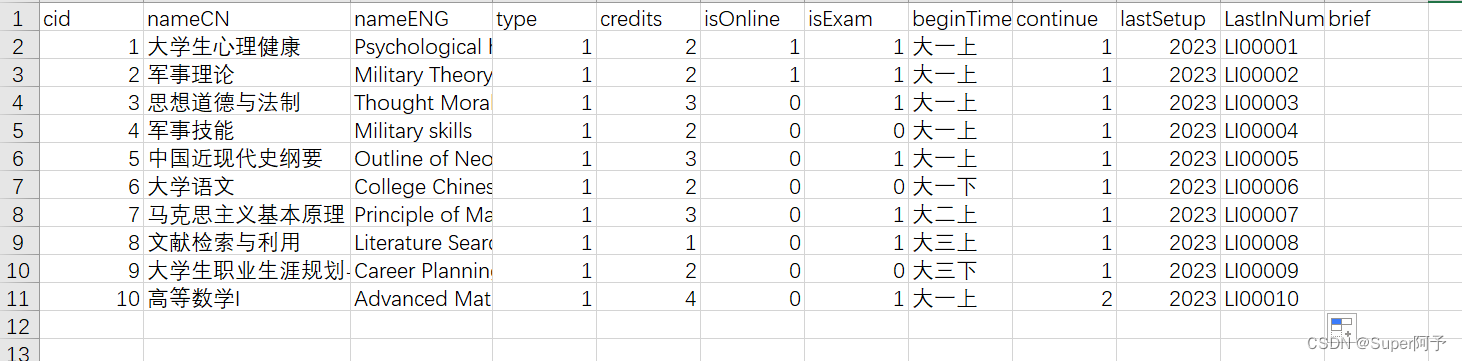
补充数据
2.另存为CSV格式

3.回到HeidiSQL界面,工具栏点开“导入CSV文件”
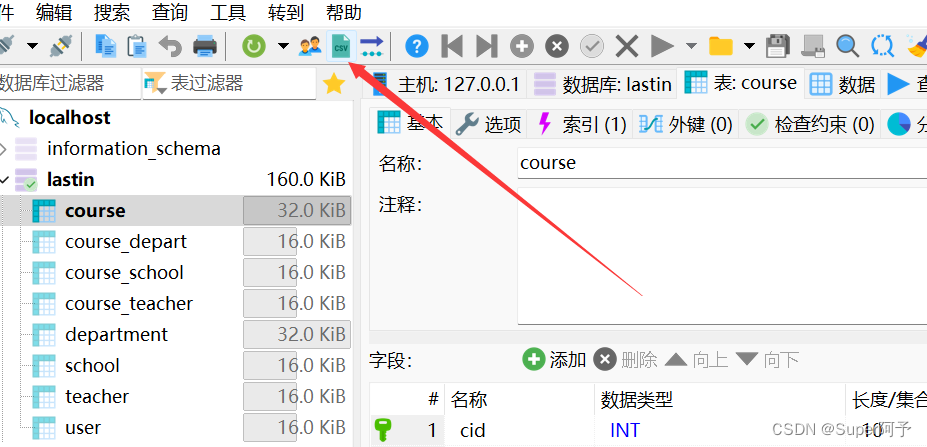
4.导入文本文件
忽略第一行(因为是表头),字段分隔符改为,号,方式改为客户端解析数据。
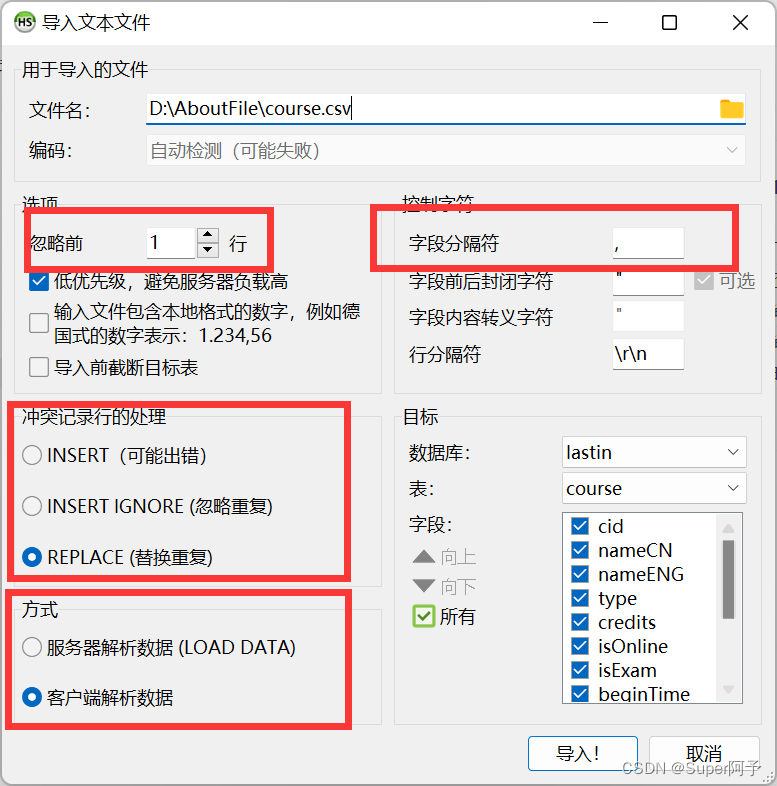
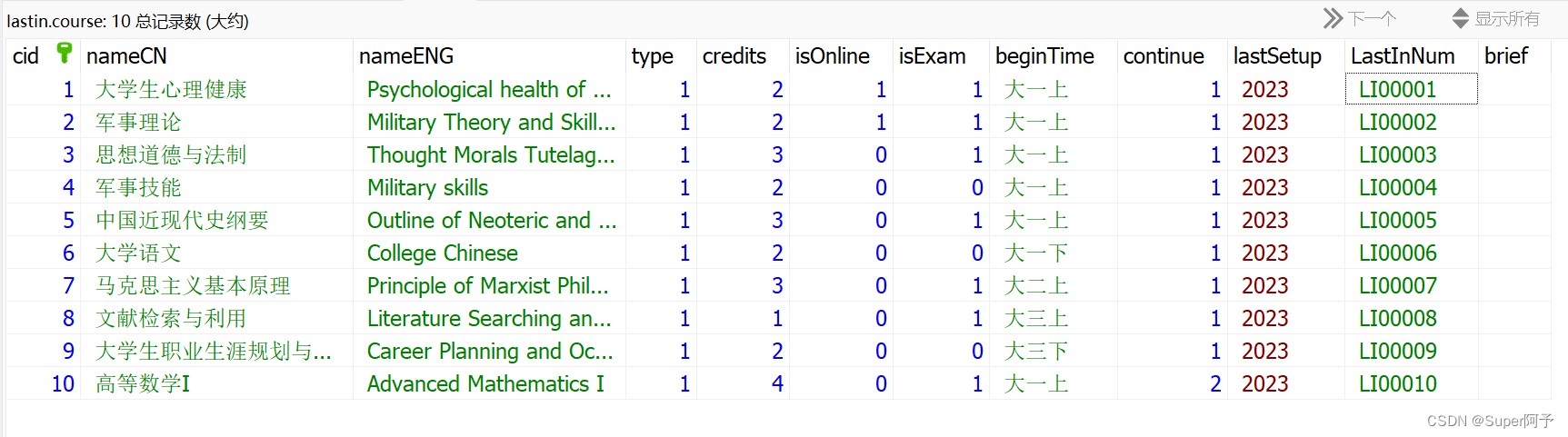
5.成功导入!


















 4942
4942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











