







上一篇博客,我们已经复习了Hadoop的HDFS组件。那么另外一个重要的组件MapReduce也必须要介绍一下了。在本篇博客中,我会详细讲解MapReduce的相关概念。
分布式并行计算
提到MapReduce就不得不先说分布式并行计算,就像提到HDFS必须先提一嘴分布式文件系统。
MapReduce是分布式并行计算概念的具体实现。什么是分布式并行计算?
- 分布式并行计算将计算任务分布到多个计算机上并行执行。
- 一个人在厨房做饭,刷碗、洗菜、切菜、炒菜,按照顺序一个一个执行这是串行;多来了两个人,三个人分工,一个人刷碗洗菜、一个人切菜、一个人炒菜,洗完一个菜就能去切菜,切完菜就能炒菜。有人可能说,啊,那这有顺序的呀,除了每个人任务量减少了,没有什么特别的优势啊?假如我们要做三道菜呢?切完第一道菜就能炒第一道菜,炒第一道菜的同时,又可以切第二道菜。是不是这样呢?如果任务量变大(做的菜品变多),在同一时刻每个人都在工作,那么并行的优势就凸显出来了。

可见,如果是一个人做这些事情,那么做三个菜需要4*3=12个时间段;
如果是三个人做这些事情,那么做三个菜只需要5个时间段。
MapReduce是什么
作为Hadoop组件,我们已经了解了如何存储数据(HDFS), 存储完了肯定不能干放着啊,那不然就是数据浪费,空占资源。数据处理,是大数据必经之路,MapReduce就是来干这个的。(注意,MapReduce不止可以处理HDFS的数据,其他数据库或文件系统的数据也是可以处理的;同理HDFS的数据也可以用其他分布式并行计算框架处理。HDFS和MapReduce是紧密集成的,其他的可能还要额外配置,所以这里配套学习。原装就是香!)
从名称就能看出来,MapReduce主要是由两个函数来执行:Map和Reduce。
两个函数也可以看作是两个步骤,下面简单介绍:
Map阶段
在这个阶段,输入数据被分割成独立的小数据块,然后并行地处理。Map的任务是处理输入数据(通常是键值对形式),并为每一条输入数据生成一个或多个中间键值对。
Reduce阶段
在这个阶段,所有具有相同键的中间数据被送到同一个Reduce函数。Reduce函数处理这些数据,合并它们为更小的数据集或汇总结果。最终,输出结果通常是处理过的数据总结或报告。
我们前面说,MapReduce是分布式并行计算框架,并行意味着同一个计算任务可能分布在不同的节点上,那么Map处理得到的键值对也就分布在不同的节点上。如果我们需要处理某一类键值对,是不是得先将相同的键值对进行汇总呢?可以看前面写的Reduce阶段任务——“所有具有相同键的中间数据被送到同一个Reduce函数”。那么这个过程就是由Shuffle来完成。
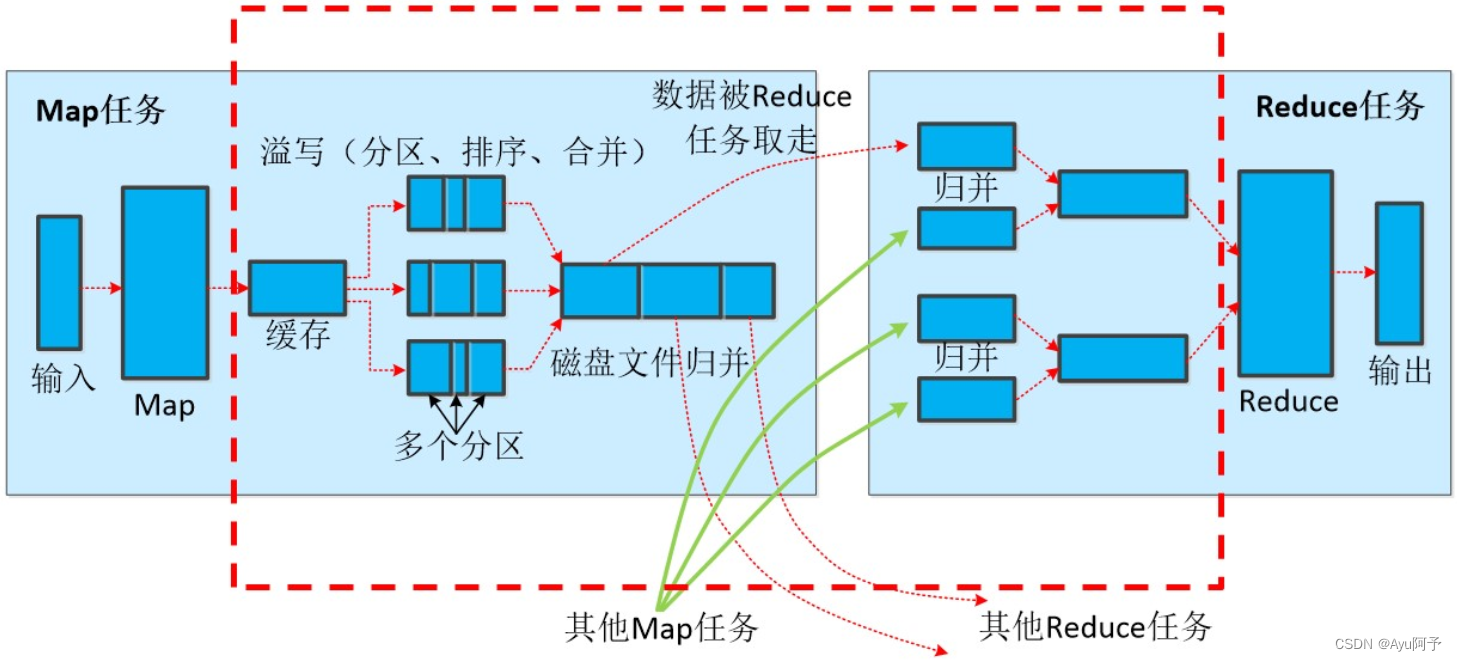
Shuffle阶段
系统自动处理Map生成的所有中间数据,将具有相同键的数据分组,为接下来的Reduce阶段做好准备。通过将相同键的所有数据值汇总到一个 Reduce 任务,可以确保在数据处理时的完整性和一致性。
具体工作:
1. 排序(Sorting):Map 任务完成后,每个节点上的输出被排序。如果一个 Map 任务处理了多个键,那么输出会按键的字典顺序排序。
2. 分组(Partitioning):排序后的数据根据键被分配到特定的 Reduce 任务。这通常是通过使用哈希函数来完成的,确保所有相同键的数据都会发送到同一个 Reduce 任务。
3. 传输(Transfer):一旦数据被排序和分组,它们就会被发送到相应的 Reduce 节点。这一步涉及网络传输,因为 Map 任务和 Reduce 任务可能不在同一个物理节点上。

MapReduce的节点
采用Master/Salve框架,包括1个Master和若干个Slave。是不是感觉和HDFS很像?不要和HDFS的NameNode&DataNode搞混噢。在集群中,一个节点是既可以作为HDFS的数据节点/名称节点,也可以作为MapReduce的Master节点/Slave节点的。但是这之间并没有必然的联系,没有“NameNode必须执行Master节点的工作”这一说。具体怎么部署的要看实际情况,是否将 Master 节点和 NameNode 放在同一台服务器上取决于具体的配置和集群的规模。(这里简单提一嘴,放在一起的优势和缺点:对于小型或初级的 Hadoop 集群,将 Master 节点的多个组件放在同一台服务器上可以降低硬件成本;但是NameNode和Master执行的任务都是资源密集型应用,在同一台机器上运行时可能会互相竞争CPU、内存和网络带宽资源,从而影响性能。)
Master上运行JobTracker, Slave上运行TaskTracker

JobTracker
在旧版Hadoop中,JobTracker负责管理MapReduce作业的调度和资源分配;在Hadoop 2.x及更高版本中,这一角色由YARN的ResourceManager担任。
JobTracker主要以下几个功能:
- 作业管理
JobTracker 是所有 MapReduce 作业的中心管理点。当客户端提交一个 MapReduce 作业时,JobTracker 负责接收作业,并初始化作业的执行环境。 - 任务调度
JobTracker 根据作业的需求和集群的资源状况决定作业的调度和执行。它决定何时运行作业、在哪些 TaskTracker 节点上运行作业的 Map 和 Reduce 任务。JobTracker 需要平衡集群负载,优化作业执行的效率。 - 监控和状态更新
JobTracker 持续监控所有 MapReduce 任务的进展,包括 Map 任务和 Reduce 任务。它记录每个任务的状态,并向客户端提供状态更新。如果 TaskTracker 失败或任务执行失败,JobTracker 负责重新调度任务到其他节点。这个也像NameNode和DataNode之间发送心跳信号汇报存活状态一样,存在这种心跳信号机制。这种机制是 MapReduce 框架中的一部分,用于维持 JobTracker 对集群中各个 TaskTracker 状态的实时了解,并管理集群的健康状况。同时心跳信息也可以用来向JobTracker 报告节点的资源使用情况,如 CPU 和内存使用率,这有助于 JobTracker 更好地调度作业和管理资源。 - 故障恢复
在任务执行过程中,如果某个 TaskTracker 节点出现故障,JobTracker 将重新调度该节点上的任务到其他健康的 TaskTracker 节点上。这保证了即使部分节点失败,作业也能继续执行,从而提高了整个系统的可靠性。 - 资源管理
虽然 JobTracker 不像 Hadoop 2.x 中的 YARN 那样具有高级的资源管理器,但它依然需要管理和分配资源,如 CPU、内存和磁盘空间,确保 MapReduce 作业能有效利用集群资源。 - 通信
如前文所说,JobTracker 与每个 TaskTracker 保持定期的心跳通信,以监控集群中各节点的健康状况。此外,它还处理来自客户端的查询,例如作业状态查询或停止作业的请求。
TaskTracker
在旧版Hadoop中,TaskTracker负责执行MapReduce作业中的任务;在Hadoop 2.x及更高版本中,这一角色由NodeManager担任,负责管理单个节点上的资源使用情况和任务执行。
TaskTracker是JobTracker和Task之间的桥梁。JobTracker于TaskTracker, Task之间采用RPC协议进行通信。
主要功能如下:
- 任务执行
TaskTracker 负责在其所在节点上执行 JobTracker 分配的 Map 和 Reduce 任务。每个 TaskTracker 可以并行执行多个任务,具体数量取决于其配置的容量和可用资源。拿前面做饭的例子来说,某个节点是负责“切菜”的,那么它是不是可以同时切两个菜呢?答案是可以的。它甚至可以同时切三个、四个或者更多的菜,这都取决于JobTracker给它分配的任务情况。 - 状态汇报
发送心跳。TaskTracker 定期向 JobTracker 发送心跳信号,这不仅表明它还活跃,同时也汇报正在执行的任务的状态。这包括任务的进度、成功或失败的状态等。 - 资源管理
TaskTracker 管理其所在节点的资源,如 CPU、内存和磁盘空间的使用。它需要确保在不超过节点能力的情况下运行任务,合理调配资源以最大化节点的工作效率。 - 数据本地化
TaskTracker 尽可能在数据所在节点上执行 Map 任务,这样可以减少网络传输,提高处理速度。这意味着如果一个节点既存储了数据块,又执行了处理这些数据块的 Map 任务,那么这个过程不需要网络传输,因为数据已经在本地节点的 HDFS 部分上。JobTracker 在分配任务时会考虑数据的位置,尽量将任务分配到存储相应数据块的节点上。 - 错误处理
如果在执行任务时遇到错误,TaskTracker 会尝试重启任务。如果重试次数超过预定阈值,它会标记任务失败,并将错误信息报告给 JobTracker。 - 日志记录
TaskTracker 为其执行的每个任务保留详细的日志信息,这对于调试和优化作业执行是必需的。
















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











