







虚拟内存
出现
为了更加有效的管理内存并且减少出错,现代系统提供了一种对主存的抽象概念—虚拟内存(VM)。
虚拟内存提供的三个重要能力
-
它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效的使用了主存
-
它为每个进程提供了一致的地址空间,从而简化了内存管理
-
它保护了每个进程的地址空间不被其他进程破坏
物理寻址
计算机系统主存被组织成一个由M个连续的字节大小的单元组成的数组。每字节都有一个唯一的物理地址(PA)。
CPU访问内存最直接的方法就是直接使用物理地址。
下图展示了一个使用物理寻址的例子:
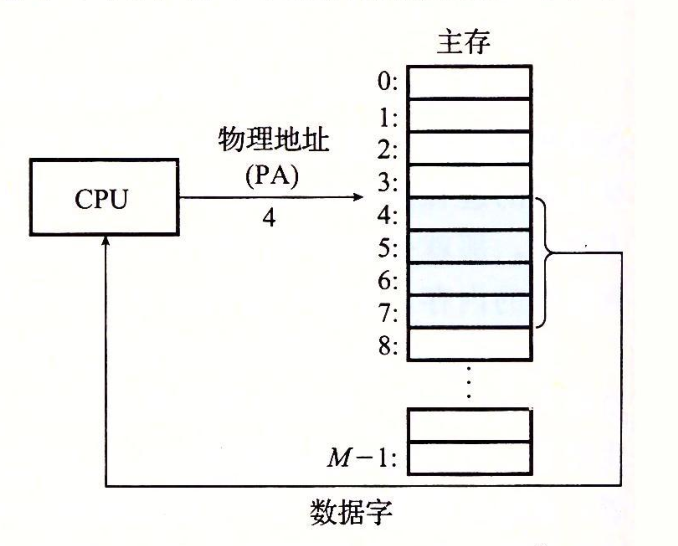
该例子上下文为一条加载指令,它读取从物理地址4处开始的4字节字,当CPU执行这条加载指令时,会生成一个有效的物理地址,通过内存总线,把它传递给主存。主存取出从物理地址4处开始的4字节字,并将它返回给CPU。
当这种方式有很大缺陷,比如:
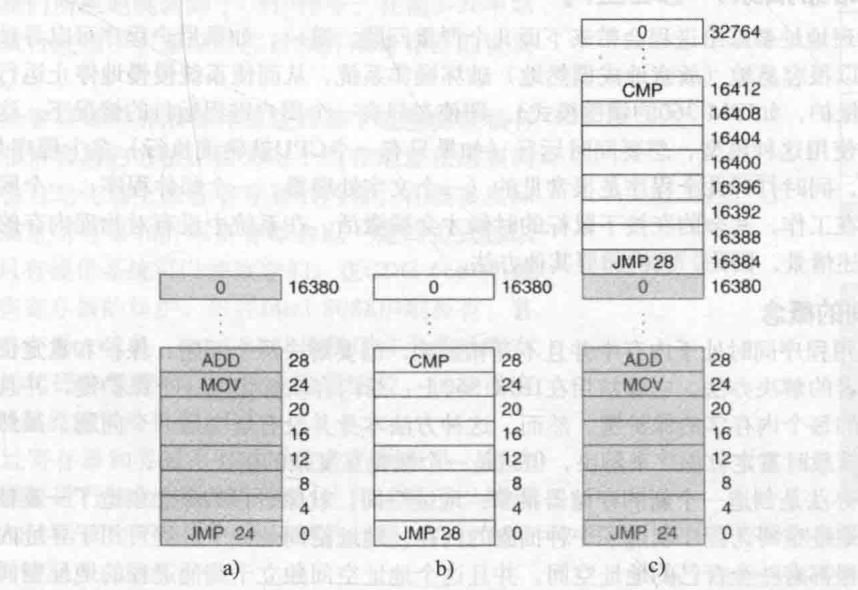
上图有两个程序,分别为图中a和b,a加了阴影表示它与b使用不同的内存键。当程序转入内存后就会发生问题,a中执行指令JMP 24,按照指令跳到了对应的位置,此时第二个程序也运行了,b执行指令 JMP 28,会跳到a中的ADD指令处,而不是CMP指令,这种对内存的不正确访问可能导致程序直接奔溃。
上面的关键问题就是直接使用了物理地址。
虚拟寻址
现代处理器使用的是一种虚拟寻址的寻址形式,如下图:
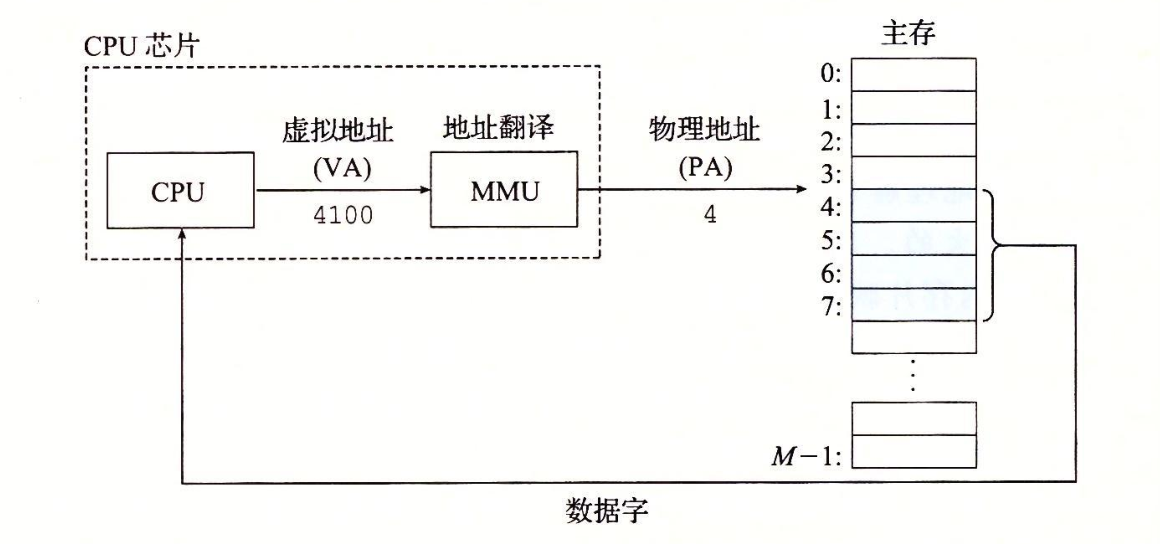
CPU通过生成一个虚拟地址(VA)来访问主存,这个虚拟地址在被送到内存之前先转换成适当的物理地址,这个过程叫地址翻译,通过CPU芯片上的内存管理单元(MMU)完成。
地址空间
地址空间是一个进程可用于寻址内存的一套地址集合。每个进程都有一个自己的地址空间,并且这个地址空间独立于其他进程的地址空间。
地址空间的概念在很多场合有使用。比如电话号码,在一些国家,一个本地电话号码通常为一个7位数字,所以,电话号码的地址空间从0 000 000 到 9 999 999。IPV4的地址是32位的数字,所以它的地址空间为2^32-1.。
虚拟内存作为缓存的工具
概念而言,虚拟内存被组织为一个由存放在磁盘上的N个连续的字节大小的单元组成的数组。
VM系统通过将虚拟内存分割为虚拟页(VP)的大小固定的块来处理。
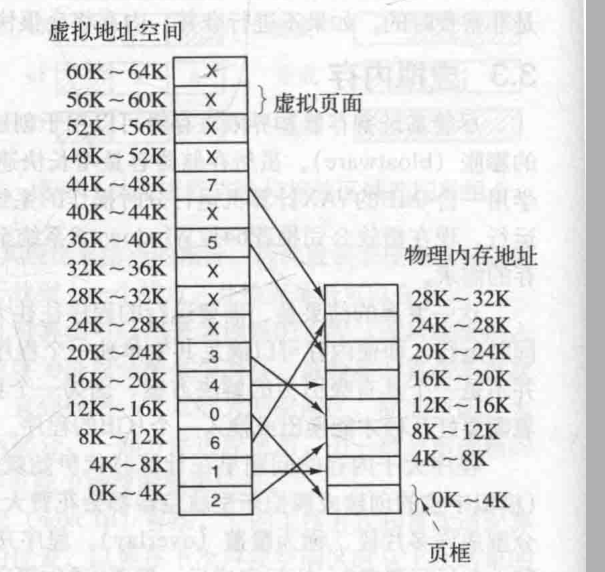
虚拟地址空间按照固定大小划分成被称为页面的若干单元,在物理内存中对应的单元称为页框
任意时刻,虚拟页面的集合都分三个不相交的子集:
-
未分配的
-
缓存的
-
未缓存的
下图展示了一个有8个虚拟页的小虚拟内存
-
0和3没有被分配,在磁盘上还不存在
-
1 4 6被缓存在物理内存
-
2 5 7 已经被分配了,但并未缓存在主存
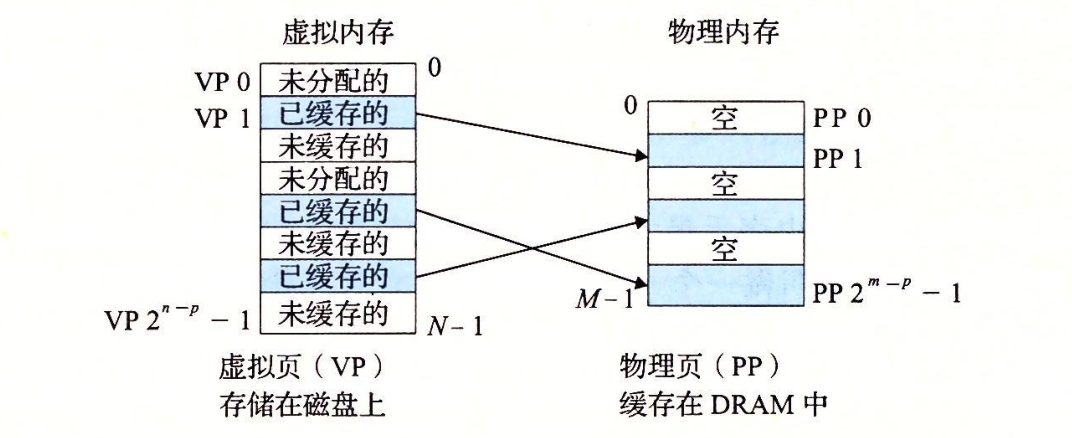
页表
虚拟内存系统需要判断一个虚拟页是否缓存在主存中,如果是,那么这个虚拟页存放在哪个物理页,如果不命中,系统要判断这个虚拟页在磁盘的什么位置,进行后续处理。
页表,存放在物理内存中的数据结构,将虚拟页映射到物理页,每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。
页表的目的是把虚拟页面映射为页框,可以把页表看成一个函数,它的参数是虚拟页号,结果是物理页框号,通过这个函数可以把虚拟地址中的虚拟页面替换成页框,从而形成物理地址。
上图展示了一个页表的基本组织结构。
页表就是一个页表条目(PTE)的数组。虚拟地址空间中的每个页在页表中一个固定偏移量处都有一个PTE,每个PTE由一个有效为和一个n位地址字段组成。上图中展示了一个有8个虚拟页和4个物理页的系统的页表。
-
VP1 VP2 VP4 VP7 当前被缓存在DRAM
-
VP0 VP5 未分配
-
VP3 VP6 分配了当未缓存
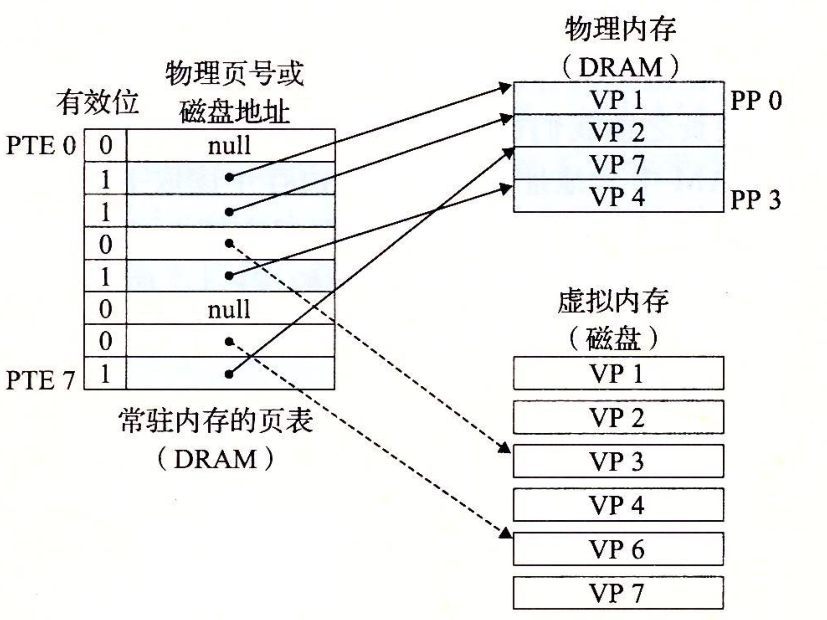
页命中
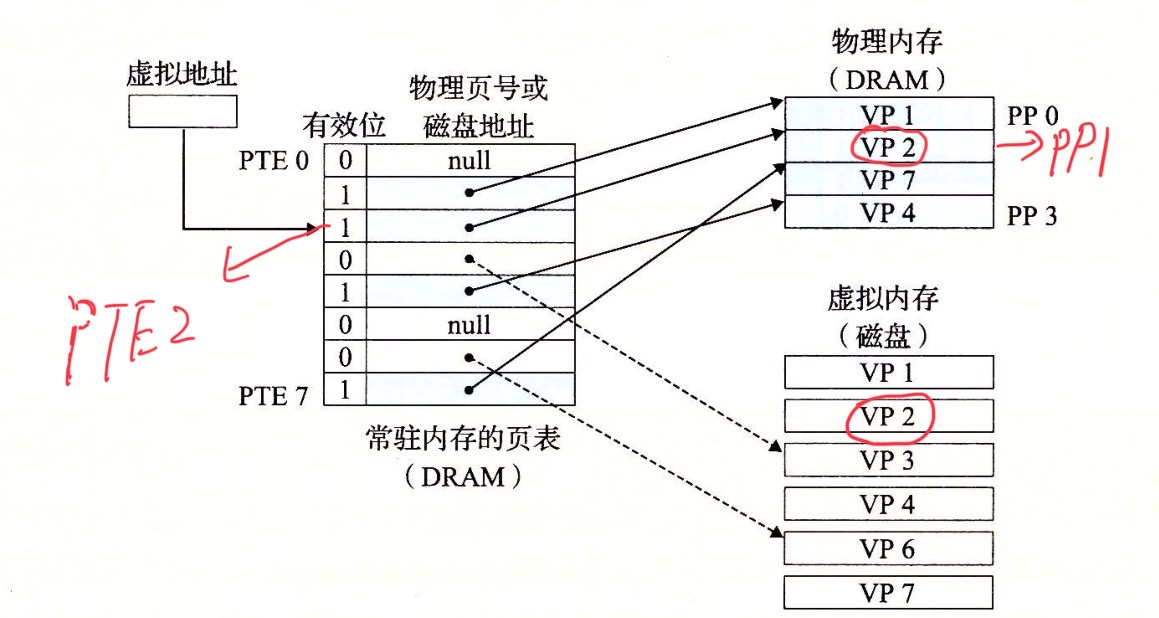
上图中,CPU读取包含在VP2中的虚拟内存的一个字会发生什么?
VP2被缓存在DRAM中,地址翻译硬件将虚拟地址作为一个索引来定位PTE2,从内存中读取它,因为设置了有效位,则地址翻译硬件知道VP2缓存在内存了,所以它使用PTE中的物理内存地址,构造出这个字的物理地址。
缺页
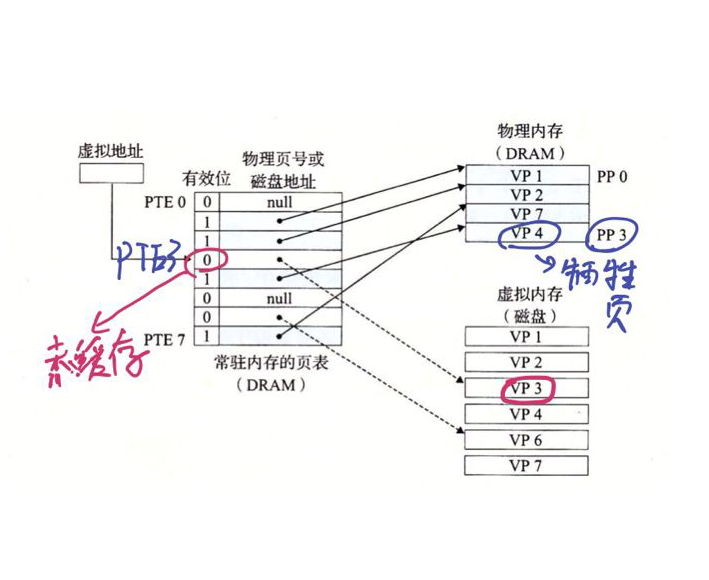
DRAM缓存不命中叫做缺页
上图,CPU引用VP3中一个字,VP3没有缓存在DRAM,地址翻译硬件从内存中读取PTE3,从有效位推断出VP3未被缓存,并且触发一个缺页异常。缺页异常调用内核的缺页异常处理程序,程序选择一个牺牲页,此例子中为PP3的VP4
虚拟内存作为内存管理的工具
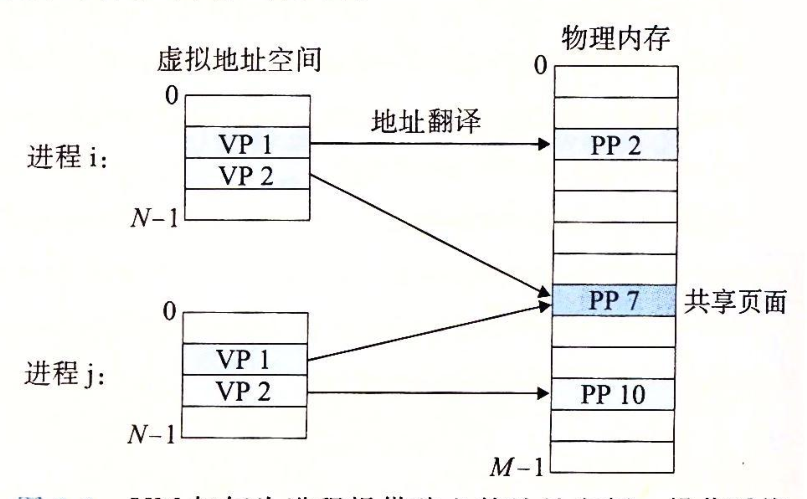
操作系统为每个进程提供了一个独立的页表,也就是一个独立的虚拟地址空间。
上图中,进程i的页表将VP1映射到PP2,VP2映射到PP7,相似的,进程j的页表将VP1映射到PP7,VP2映射到PP10。
多个虚拟页面可以映射到同一个共享物理页面上
按需页面调度和独立的虚拟地址空间的结合,有很大的意义:
-
简化链接
-
简化加载
-
简化共享
-
简化内存分配
虚拟内存作为内存保护的工具
现代计算机系统必须为操作系统提供手段来控制对内存系统的访问。
因为每次CPU生成一个地址时,地址翻译硬件都会读一个PTE,所以通过在PTE上添加一些额外的许可位来控制对一个虚拟页面内容的访问十分简单。
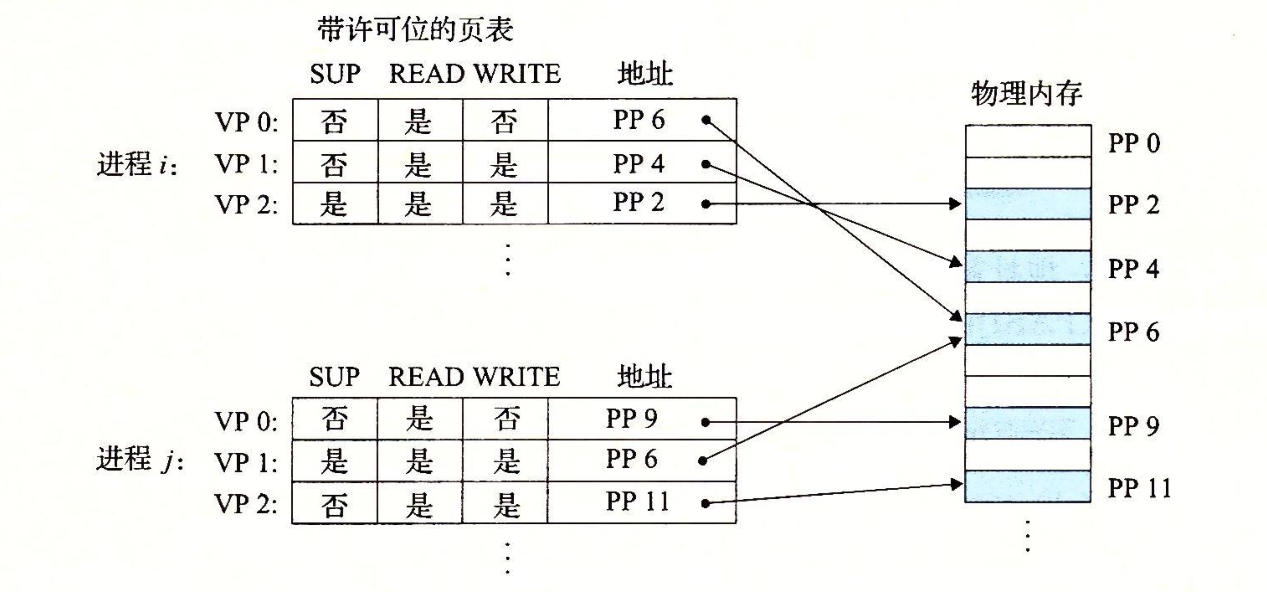
上图中,每个PTE已经添加了三个许可位
-
SUP位表示进程是否必须运行在内核模式下才可以访问该页
-
READ位和WRITE位控制对页面的读和写访问
地址翻译
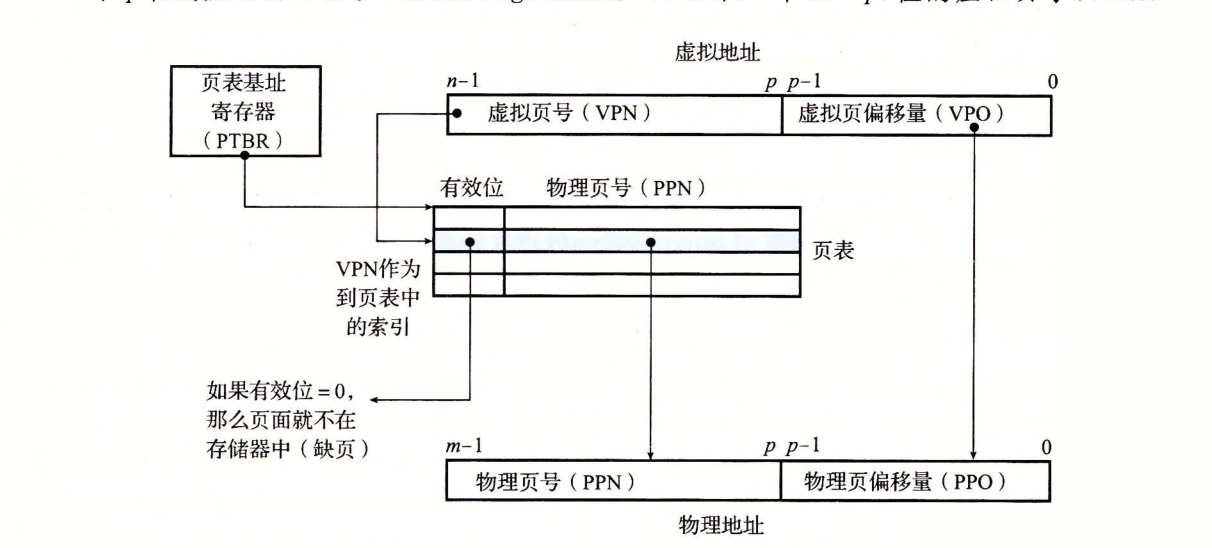
上图展示了MMU如何利用页表来实现地址映射
CPU中的一个控制寄存器,页表基址寄存器(PTBR)指向当前页表。n位的虚拟地址包含两个部分
-
一个p位的虚拟页面偏移(VPO)
-
一个(n-p)位的虚拟页号(VPN)
MMU利用VPN选择适当的PTE,如:VPN 0选择PTE 0,VPN 1选择PTE 1。将页表条目中物理页号(PPN)与虚拟地址中的VPO串联起来,得到相应的物理地址。
因为物理和虚拟页面都是P字节的,所以物理页面偏移(PPO)和VPO是一样的。
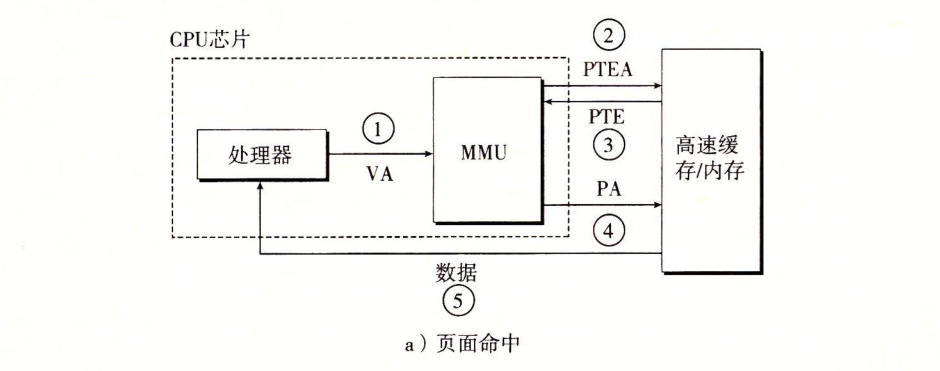
上图展示了页面命中时,CPU硬件的执行步骤
-
1 处理器生成一个虚拟地址,传给MMU
-
2 MMU生成PTE地址,从高速缓存/主存请求得到它
-
3 高速缓存/主存向MMU返回PTE
-
4 MMU构造物理地址,把它传送给高速缓存/主存
-
5 高速缓存/主存返回请求的数据字给处理器
利用TLB加速地址翻译
每次CPU产生一个虚拟地址,MMU都必须查阅一个PTE,以便将虚拟地址翻译为物理地址,这一过程有时太耗费时间了。所以在MMU中加入一个关于PTE的小的缓存,叫做翻译后备缓冲器(TLB)
TLB是一个小的,虚拟寻址的缓存,其中每一行都保存着一个由单个PTE组成的块。

上图展示了TLB命中时的步骤,关键点在于:所有的地址翻译步骤都是在芯片上的MMU执行的,因此速度很快。
-
1 CPU产生一个虚拟地址
-
2和3 MMU从TLB中取出相应PTE
-
4 MMU将这个虚拟地址翻译成一个物理地址,将它发送到高速缓存/主存
-
5 高速缓存/主存将所请求的数据字返回给CPU
多级页表
在使用单级页表时,假设我们的地址空间为32位,也就是4GB,每个页面大小为4KB,则我们需要(4GB/4KB=1M)1M个页面,其中假设每个PTE需要占用4个字节,那一个页表需要(4B*1M=4MB)4MB的空间大小,当系统中进程增大到一定数量时,就太耗费内存了。
这个时候我们考虑使用二级页表
同样的条件,一级页表映射4MB大小,二级页表映射4KB大小。则需要1K个一级页表项(4GB / 4MB = 1K)、每个一级页表项对应1K个二级页表项(4MB / 4KB = 1K)。
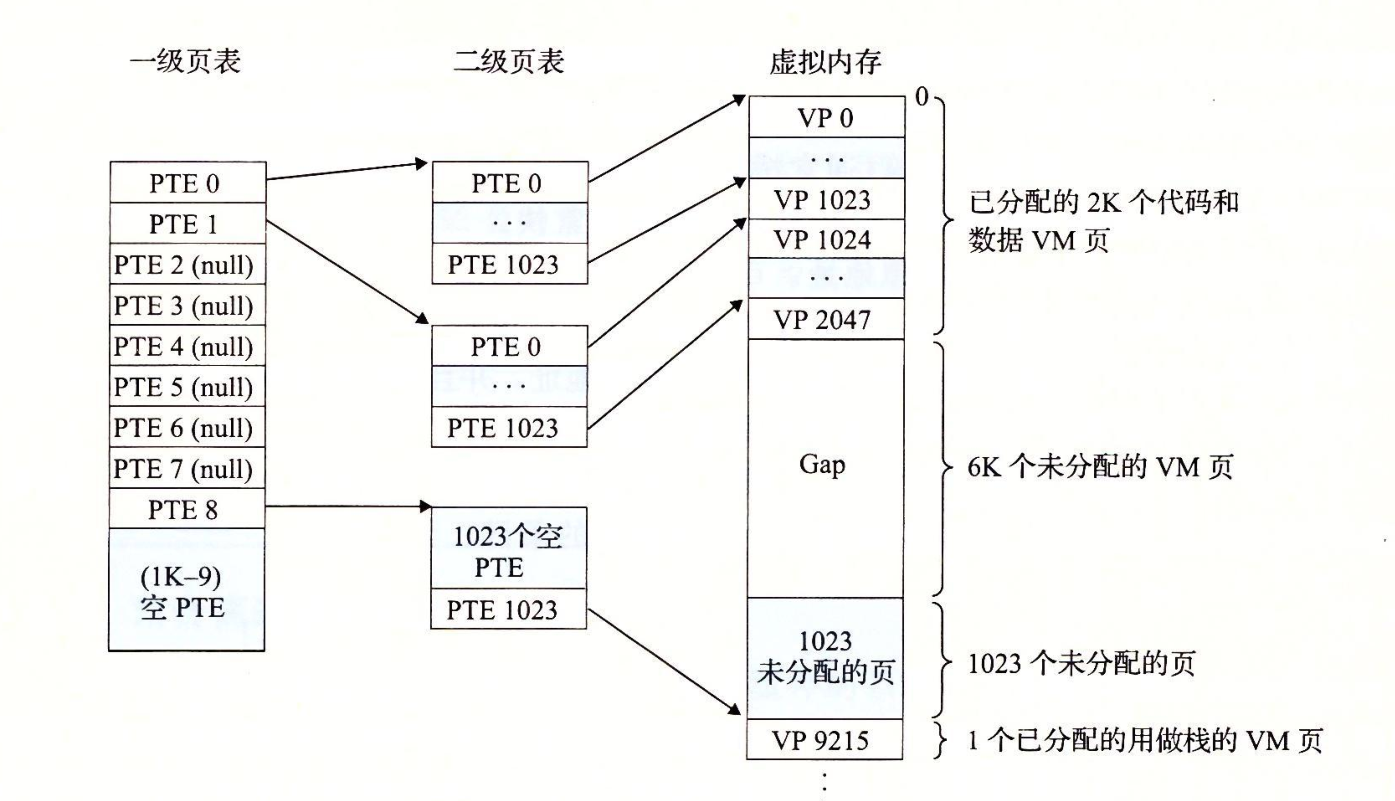
如上图所示,一级页表中的每个PTE负责映射虚拟地址空间中的一个4MB的片,每一片又由1024个连续的页面组成,如:PTE 0映射第一片,PTE 1映射接下来的一片。
假设片i中每个页面都没分配,那么一级PTE i 为空,如上图:片2-7未被分配,但如果片i中至少有一个页是分配了的,那么一级PTE i就指向一个二级页表的基址。
如上图:0 1 8的所有或者部分已经被分配好了。
这种设计从两个方面减少了内存需求:
-
如果一级页表中一个PTE为空,那么就不会存在相应的二级页表。对于一个典型的程序来说,4GB的虚拟地址空间大部分是未分配的
-
只有一级页表才需要在主存,虚拟内存系统可以在需要时创建,页面调入或调出二级页表,减少主存压力。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









