







题目一:递归调用
函数的参数:
def dump(index, default=0, *args, **kw):
print('打印函数参数')
print('---')
print('index:', index)
print('default:', default)
for i, arg in enumerate(args):
print(f'arg[{i}]:', arg)
for key,value in kw:
print(f'keyword_argument {key}:{value}')
print('')if __name__=='__main__':
dump(0)
dump(0,2)
dump(0,2,"Hello","World")
dump(0,2,"Hello","World", install='Python', run='Python Program')Python函数的参数十分灵活,例如上面的例子:
index: 按顺序位置指定的参数
default=0: 带有默认值的参数
*args: 0个或多个可选的参数
**kw: 0个或多个关键字参数
查看打印结果可以增加对此的理解,语句 `` 的输出是:
打印函数参数
---
index: 0
default: 2
arg[0]: Hello
arg[1]: World
keyword_argument install:Python
keyword_argument run:Python Program
Python 的函数可以调用别的函数,当调用的是自己本身时,就形成了递归调用。以下是一个待完成的递归调用程序,功能需求是:
- 循环打印"Hello,World!"的每个字符
- 循环5次。
# -*- coding: UTF-8 -*-
def circulate_print(str, count=0):
if count == 5:
return
for char in str:
print(char)
# TODO(You): 请在此完成函数递归调用if __name__ == '__main__':
str = "Hello,World!"
circulate_print(str)
实现
# 第一种 count = count+1 circulate_print(str, count) # 第二种 circulate_print(str, count=count+1) # 第三种 circulate_print(str, count+1)主要在参数的传递和函数调用的形式上有区别。
- 第一种实际上改变了count值
- 第二种用关键字参数形式来传参(将当前count值+1后作为参数传给函数),不会改变count值,要求函数定义中的参数名必须匹配
- 第三种用位置参数传参,不改变count值
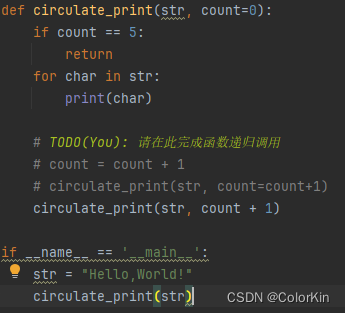
错误答案分析
circulate_print(str, count)
# 循环时count不改变,陷入死循环
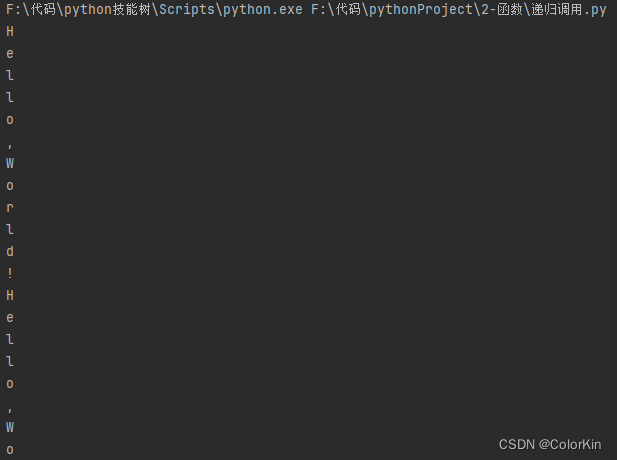
改进
竖版字母输出更改为横板展示更舒适。
将 print(char) 更改为 print(char,end=' ')

题目二:非递归阶乘实现
0,1,2,3,4,5,6,7,8,9,10! 令人惊讶的是,6个星期的秒数居然也等于10!
不使用函数递归,实现一个阶乘计算函数(n<=170):
# -*- coding: UTF-8 -*-
def fact(n):
r = 1
# TODO(You): 请在此编写代码
return rif __name__ == '__main__':
print(fact(10))
实现
# 第一种 for i in range(0, n): r *= (i+1) # 第二种 import math r = math.factorial(n) # 第三种 while n > 0: r *= n n -= 1
- 第一种(
for循环)和第三种(while循环)在本质上是相似的,都需要手动实现阶乘的计算逻辑,不同之处在于循环的类型和如何索引循环变量。- 第二种最优,直接用math库内函数,代码更简洁,且factorial()方法可能经过优化,性能上可能更好。
- 第三种在循环中直接修改了
n的值,如果n的原始值在循环后还需要使用,这种方法可能不适合。
错误答案分析
import math
z = n + 1
p = [1.000000000190015, 76.18009172947146, -86.50532032941677,
24.01409824083091, -1.231739572450155, 1.208650973866179E-3, -5.395239384953E-6]d1 = math.sqrt(2 * math.pi) / z
i = 1
d2 = p[0]
while i <= 6:
d2 += p[i] / (z + i)
i += 1d3d4 = math.pow((z + 5.5), (z + 0.5))*math.exp(-(z + 5.5))
d = d1 * d2 * d3d4
r = int(d)# 上面三种是直接计算阶乘,而不涉及任何近似或估计。第四种是斯特林近似,用于近似阶乘的数学公式,特别是在处理大数的阶乘时,这个近似公式非常有用。虽然也能运行出同样结果,但是题目给出的n条件是≤170。
题目三:函数递归的方式写阶乘计算
# -*- coding: UTF-8 -*-
# TODO(You): 请实现递归计算阶乘
if __name__ == '__main__': print(fact(998))
实现
# 第一种 def inner_fact(n, m): if m == n: return n return m*inner_fact(n, m+1) def fact(n): return inner_fact(n,1) # 第二种 def fact(n): if n == 1: return 1 return n*fact(n-1) # 第三种 def inner_fact(n, r): if n == 1: return r return inner_fact(n-1, r*n) def fact(n): return inner_fact(n, 1)
- 第一种:inner_fact函数通过递归方式从m增加到n,并在每一步乘以m,缺点是n非常大时容易导致栈溢出。
- 第二种:从
n开始,每次递归调用自己计算n-1的阶乘,直到达到基础情况n == 1。缺点同上。- 第三种:利用了尾递归(指递归调用是函数体中的最后一个操作)。
inner_fact利用一个额外的参数r来累积结果,每次递归将其乘以n,减少n的值,直到n为1。
错误答案分析
def inner_fact(n, m, r):
if m == n:
return r
return inner_fact(n, m+1, r*m)
def fact4(n):
return inner_fact(n, 1, 1)# 函数名错误
题目四:斐波那契(Ⅰ)
数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子引入了数列0、1、1、2、3、5、8、13、21、34...,称为斐波那契数列(Fibonacci sequence),又称“黄金分割数列”或者“兔子数列”。使用函数递归或非递归的方式都可以方便地计算斐波那契函数:F(0)=0,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2)
# -*- coding: UTF-8 -*-
# TODO(You): 请实现递归计算斐波那契函数
if __name__ == '__main__':
print(fibonacci(6))
实现
# 第一种 def fibonacci(n): if n == 1 or n == 2: return 1 r = [1, 1] for i in range(2, n): r[1],r[0] = r[1]+r[0],r[1] return r[1] # 第二种 def fibonacci_inner(n, m, r0, r1): if m == n: return r1 return fibonacci_inner(n, m+1, r1, r0+r1) def fibonacci(n): return fibonacci_inner(n, 2, 1, 1) # 第三种 def fibonacci(n): if n == 1 or n == 2: return 1 return fibonacci(n-1) + fibonacci(n-2)
- 第一种:迭代。r来存储当前计算的两个斐波那契数,然后通过循环更新这两个数直到达到目标位置。计算斐波那契数较大时,最优。
- 第二种:尾递归。在每一步递归中,只需要更新参数中的值,而不需要保存调用栈。计算斐波那契数不占优势
- 第三种:递归。计算大量的斐波那契数时,会存在重复计算的问题,效率较低。
错误答案分析
def fibonacci_inner(n, r):
if n == 1 or n == 2:
return rreturn fibonacci_inner(n-1, fibonacci_inner(n-2, r))
def fibonacci4(n):
return fibonacci_inner(n, 0)# 函数名错误
题目五:斐波那契(Ⅱ)
递归实现版本有很多冗余计算,可以通过增加缓存来优化
# -*- coding: UTF-8 -*-
def fibonacci_inner(n, cache):
if n == 1 or n == 2:
return 1
r = 0
# TODO(You): 实现缓存def fibonacci(n):
return fibonacci_inner(n, {})if __name__ == '__main__':
print(fibonacci(6))
实现
# 第一种 if cache.get(n) is None: cache[n] = fibonacci_inner(n-2, cache) + fibonacci_inner(n-3, cache) return cache[n] # 第二种 if cache.get(n) is not None: return cache[n] else: cache[n] = fibonacci_inner1(n-1, cache) + fibonacci_inner1(n-2, cache) return cache[n] def fibonacci(n): return fibonacci_inner(n, 2, 1, 1) # 第三种 if cache.get(n) is None: cache[n-2] = fibonacci_inner1(n-2, cache) cache[n-1] = fibonacci_inner1(n-1, cache) cache[n] = cache[n-1]+cache[n-2] return cache[n]
- 第一种:检查缓存中是否有计算过的值,false就计算并缓存。属于自底向上(从更小的值开始计算)的递归。缺点:每次调用只计算并缓存一个值,可能不是最优缓存利用策略。
- 第二种:先检查缓存中是否有值(避免不必要的计算),ture就直接返回,false就计算并缓存。缺点:需要更多的递归调用,每次计算一个新值时,都需要递归地计算n-1、n-2的值,可能导致更多的函数调用堆栈。
- 第三种:在缓存中没找到值时,会同时计算并缓存n-2、n-1的值,然后用它们来计算n的值。(减少递归深度、性能优化)
错误答案分析
if cache.get(n) is None:
fibonacci_inner1(n-2, cache)
fibonacci_inner1(n-1, cache)
cache[n] = cache[n-1]+cache[n-2]
return cache[n]# 未定义赋值cache[n-1]、cache[n-2]
题目六:基于函数的API设计,理解接口与实现分离
使用函数设计一组 “容器API”:init/set/get/exist
# -*- coding: UTF-8 -*-
def init():
# TODO(You): 实现初始化def set(dict, key, value):
# TODO(You): 实现初始化def get(dict, key):
# TODO(You): 实现获取接口def exist(dict, key):
# TODO(You): 实现判断接口if __name__ == '__main__':
dict = init()
for i in range(10):
key = "key_{}".format(i)
value = i
set(dict, key, value)test_key = "key_4"
if exist(dict, test_key):
test_value = get(dict, test_key)
print("key is: {}, value is: {}".format(test_key, test_value))
实现
# 第一种 def init(): return {} def set(dict, key, value): dict[key] = value def get(dict, key): return dict.get(key) def exist(dict, key): return dict.get(key) is not None # 第二种 def init(): return [], [] def set(dict, key, value): keys, values = dict if not key in keys: keys.append(key) values.append(value) def get(dict, key): keys, values = dict if not key in keys: return None else: return values[keys.index(key)] def exist(dict, key): keys, values = dict return key in keys # 第三种 def init(): return [] def set(dict, key, value): if not key in dict or dict.index(key) % 2 != 0: dict.append(key) dict.append(value) def get(dict, key): if key in dict: pos = dict.index(key) if pos % 2 == 0: return dict[pos+1] return None def exist(dict, key): return key in dict and dict.index(key) % 2 == 0
- 第一种:Python内置字典,最优
- 第二种:用两个并行的列表,一个存储键,另一个存储对应的值。在键的数量大时非常低效。
- 第三种:只使用一个列表,偶数索引位置存储键,其紧随其后的奇数索引位置存储值。查找效率低。
错误答案分析
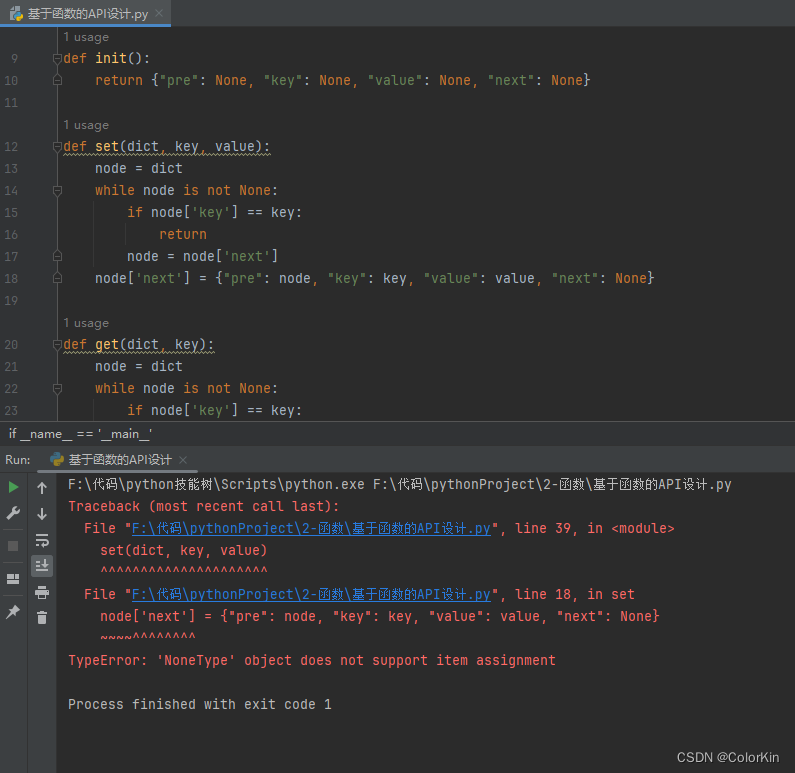
def init():
return {"pre": None, "key": None, "value": None, "next": None}def set(dict, key, value):
node = dict
while node is not None:
if node['key'] == key:
return
node = node['next']
node['next'] = {"pre": node, "key": key, "value": value, "next": None}def get(dict, key):
node = dict
while node is not None:
if node['key'] == key:
return node['value']
node = node['next']def exist(dict, key):
node = dict
while node is not None:
if node['key'] == key:
return True
node = node['next']
return False# set函数的目的是在链表种插入一个新的节点。while结束时,node将为None,不能在None上设置键值对。
修改后:
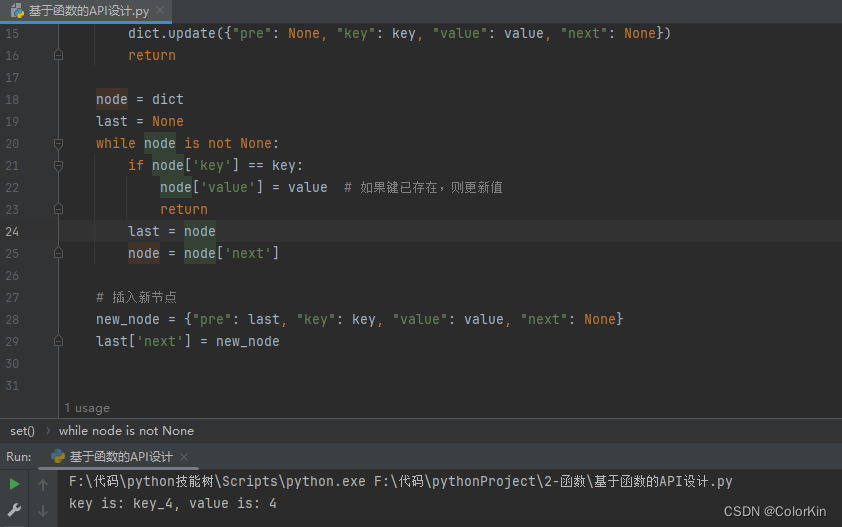
def set(dict, key, value):
if dict['key'] is None: # 处理空链表的情况
dict.update({"pre": None, "key": key, "value": value, "next": None})
returnnode = dict
last = None
while node is not None:
if node['key'] == key:
node['value'] = value # 如果键已存在,则更新值
return
last = node
node = node['next']
# 插入新节点
new_node = {"pre": last, "key": key, "value": value, "next": None}
last['next'] = new_node















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









