







目录
业务问题1:收费App的价格分布是如何的?不同类别之间有关系吗?
案例导入
如今想在手机应用商店上成为成功的应用越来越难,对App下载和评分数据的分析成为帮助App开发者获取和留存用户的重要工具。Play商店应用数据具有巨大的潜力,可以推动应用制作业务取得成功。可以为开发人员提供可操作的见解,以便开发和捕获移动市场。
我们想分析3个问题
- 收费和免费的App都集中在哪些类别?
- 收费App的价格分布是如何的?不同类别的价格分布是怎样的?
- App文件的大小和价格以及用户评分之间有关系吗?
本课程分析流程
核心变量解释
- “id” : 苹果给提供的APP ID,每个app唯一
- “track_name”: APP的名称
- “size_bytes”: 以byte为单位的app大小
- “price”: 定价(单位为美元)
- “rating_count_tot”: 该app所有版本的用户评分数量
- “rating_count_ver”: 该app当前版本的用户评分数量
- “prime_genre”: app的类别
- “user_rating” 该app所有版本的用户评分
- “user_rating_ver”: 该app当前版本的用户评分
- “sup_devices.num”: 支持的ios设备数量
- “ipadSc_urls.num”: app提供的截屏展示数量
- “lang.num”: 支持的语言数量
1.数据导入清洗
导入数据需要注意数据文件的相对位置和绝对位置
#调用基本包
import pandas as pd
#读取数据
app=pd.read_csv('w1_applestore.csv',index_col=0)
#数据的基本信息
app.head()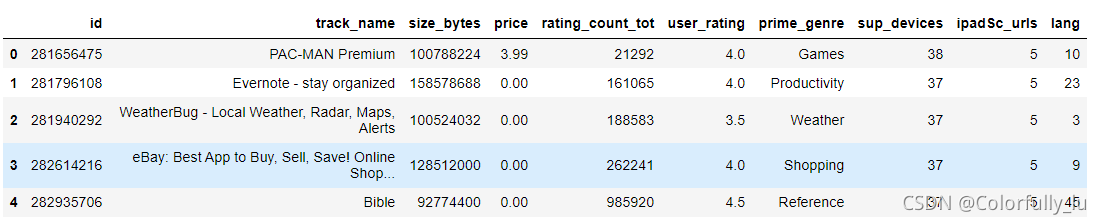
app.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 7197 entries, 0 to 7196
Data columns (total 10 columns):
id 7197 non-null int64
track_name 7197 non-null object
size_bytes 7197 non-null int64
price 7197 non-null float64
rating_count_tot 7197 non-null int64
user_rating 7197 non-null float64
prime_genre 7197 non-null object
sup_devices 7197 non-null int64
ipadSc_urls 7197 non-null int64
lang 7197 non-null int64
dtypes: float64(2), int64(6), object(2)
memory usage: 618.5+ KB没有缺失值
下面对数据进行整体描述,只对数值型有效
app.describe()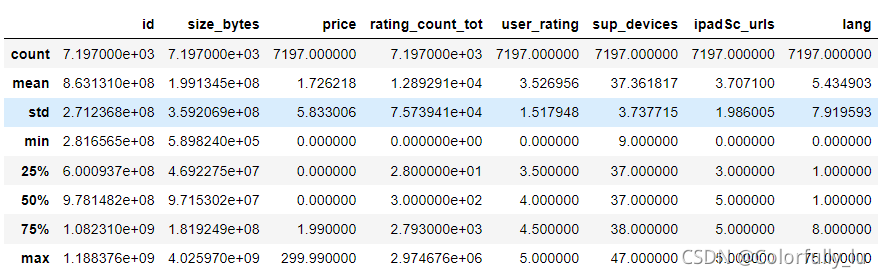
考虑将sizebytes变成mb,新增数据
app['size_mb']=app['size_bytes']/(1024*1024.0)
app.size_mb.describe()cou 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









