







目录
2 linear_model.LogisticRegression
2.4 二元回归与多元回归:重要参数solver & multi_class
1 概述
1.1 名为“回归”的分类器
在过去的四周中,我们接触了不少带
“
回归
”二字的算法,回归树,随机森林的回归,无一例外他们都是区别于分类算法们,用来处理和预测连续型标签的算法。然而逻辑回归,是一种名为
“
回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法。要理解逻辑回归从何而来,得要先理解线性回归。线性回归是机器学习中最简单的的回归算法,它写作一个几乎人人熟悉的方程:
![]()

线性回归的任务,就是构造一个预测函数 来映射输入的特征矩阵
x
和标签值
y
的线性关系,而
构造预测函数的核心
就是找出模型的参数: 和
和 ,著名的最小二乘法就是用来求解线性回归中参数的数学方法。
,著名的最小二乘法就是用来求解线性回归中参数的数学方法。
通过函数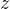 ,线性回归使用输入的特征矩阵
X
来输出一组连续型的标签值
y_pred,以完成各种预测连续型变量的任务(比如预测产品销量,预测股价等等).那如果我们的标签是离散型变量,尤其是,如果是满足
0-1分布的离散型变量,我们要怎么办呢?我们可以通过引入联系函数
(link function)
,将线性回归方程
z
变换为
g(z)
,并且令
g(z)的值分布在
(0,1)
之间,且当
g(z)
接近
0
时样本的标签为类别
0
,当
g(z)
接近
1
时样本的标签为类别
1,这样就得到了一个分类模型。而这个联系函数对于逻辑回归来说,就是
Sigmoid
函数:
,线性回归使用输入的特征矩阵
X
来输出一组连续型的标签值
y_pred,以完成各种预测连续型变量的任务(比如预测产品销量,预测股价等等).那如果我们的标签是离散型变量,尤其是,如果是满足
0-1分布的离散型变量,我们要怎么办呢?我们可以通过引入联系函数
(link function)
,将线性回归方程
z
变换为
g(z)
,并且令
g(z)的值分布在
(0,1)
之间,且当
g(z)
接近
0
时样本的标签为类别
0
,当
g(z)
接近
1
时样本的标签为类别
1,这样就得到了一个分类模型。而这个联系函数对于逻辑回归来说,就是
Sigmoid
函数:
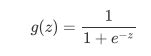
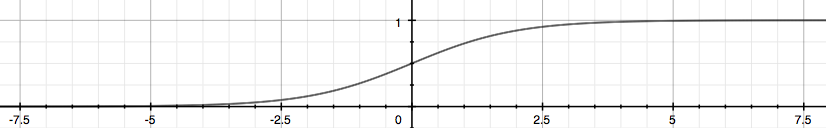
面试高危问题:Sigmoid函数的公式和性质
Sigmoid个
S
型的函数,当自变量z
趋近正无穷时,因变量
g(z)
趋近于
1
,而当
z
趋近负无穷时,
g(z)趋近于
0
,它能够将任何实数映射到
(0,1)
区间,使其可用于将任意值函数转换为更适合二分类的函数。
因为这个性质,
Sigmoid
函数也被当作是归一化的一种方法,与我们之前学过的
MinMaxSclaer同理,是属于数据预处理中的
“
缩放
”
功能,可以将数据压缩到
[0,1]
之内。区别在于,
MinMaxScaler归一化之后,是可以取到
0
和
1
的(最大值归一化后就是
1
,最小值归一化后就是
0
),但
Sigmoid
函数只是无限趋近于
0
和
1
。
线性回归中 ,于是我们将带入,就得到了二元逻辑回归模型的一般形式:
,于是我们将带入,就得到了二元逻辑回归模型的一般形式:
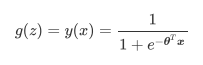
而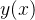 就是我们逻辑回归返回的标签值。此时,
的取值都在
[0,1]之间,因此
和1-
就是我们逻辑回归返回的标签值。此时,
的取值都在
[0,1]之间,因此
和1-
相加必然为1。如果我们令除以1-
可以得到形似几率(odds)的
,在此基础上取对数,可以很容易就得到:

不难发现,
y(x)
的形似几率取对数的本质其实就是我们的线性回归
z,我们实际上是在对线性回归模型的预测结果取对数几率来让其的结果无限逼近
0
和
1
。因此,其对应的模型被称为
”
对数几率回归
“
(
logistic Regression),也就是我们的逻辑回归,这个名为
“
回归
”
却是用来做分类工作的分类器。
之前我们提到过,线性回归的核心任务是通过求解 构建 这个预测函数,并希望预测函数 能够尽量拟合数据,因此逻辑回归的核心任务也是类似的:求解 来构建一个能够尽量拟合数据的预测函数,并通过向预测函数中输入特征矩阵来获取相应的标签值y。
思考:
y(x)
代表了样本为某一类标签的概率吗?
做出如下的解释:
我们让线性回归结果逼近0和1,此时和1-之和为1,因此它们可以被我们看作是一对正反例发生的概率,即是某样本i
的标签被预测为
1的概率,而1-是i
的标签被预测为
0的概率,就是样本
i的标签被预测为1的相对概率。基于这种理解,我们使用最大似然法和概率分布函数推到出逻辑回归的损失函数,并且把返回样本在标签取值上的概率当成是逻辑回归的性质来使用,每当我们诉求概率的时候,我们都会使用逻辑回归。
然而这种理解是正确的吗?概率是度量偶然事件发生可能性的数值,尽管逻辑回归的取值在(0,1)之间,并且和1-之和的确为1,但光凭这个性质,我们就可以认为代表了样本x
在标签上取值为
1的概率吗?设想我们使用
MaxMinScaler
对特征进行归一化后,任意特征的取值也在[0,1]之间,并且任意特征的取值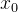 和
和 也能够相加为
1
,但我们却不会认为
0-1
归一化后的特征是某种概率。
逻辑回归返回了概率这个命题,这种说法严谨吗?
也能够相加为
1
,但我们却不会认为
0-1
归一化后的特征是某种概率。
逻辑回归返回了概率这个命题,这种说法严谨吗?
但无论如何,长年以来人们都是以
”
返回概率
“的方式来理解逻辑回归,并且这样使用它的性质。可以说,逻辑回归返回的数字,即便本质上不是概率,却也有着概率的各种性质,可以被当成是概率来看待和使用。
1.2 为什么需要逻辑回归
线性回归对数据的要求很严格,比如标签必须满足正态分布,特征之间的多重共线性需要消除等等,而现实中很多真实情景的数据无法满足这些要求,因此线性回归在很多现实情境的应用效果有限。逻辑回归是由线性回归变化而来,因此它对数据也有一些要求,而我们之前已经学过了强大的分类模型决策树和随机森林,它们的分类效力很强,并且不需要对数据做任何预处理。
何况,逻辑回归的原理其实并不简单。一个人要理解逻辑回归,必须要有一定的数学基础,必须理解损失函数,正则化,梯度下降,海森矩阵等等这些复杂的概念,才能够对逻辑回归进行调优。其涉及到的数学理念,不比支持向量机少多少。况且,要计算概率,朴素贝叶斯可以计算出真正意义上的概率,要进行分类,机器学习中能够完成二分类功能的模型简直多如牛毛。因此,在数据挖掘,人工智能所涉及到的医疗,教育,人脸识别,语音识别这些领域,逻辑回归没有太多的出场机会。
甚至,在我们的各种机器学习经典书目中,周志华的《机器学习》
400页仅有一页纸是关于逻辑回归的(还是一页数学公式),《数据挖掘导论》和《
Python
数据科学手册》中完全没有逻辑回归相关的内容,
sklearn中对比各种分类器的效应也不带逻辑回归玩,可见业界地位。
但是,无论机器学习领域如何折腾,逻辑回归依然是一个受工业商业热爱,使用广泛的模型,因为它有着不可替代的优点:
- 1. 逻辑回归对线性关系的拟合效果好到丧心病狂,特征与标签之间的线性关系极强的数据,比如金融领域中的信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知道数据之间的联系是非线性的,千万不要迷信逻辑回归)
- 2. 逻辑回归计算快:对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表示在大型数据上尤其能够看得出区别 </
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









