







1 背景
考研分数下来后,感觉成绩不错的就要开始联系目标院校的导师了。选择导师要按照自己感兴趣的研究生方向进行选择,如果能按关键字检索导师信息就会方便许多。我报考的是北京交通大学计算机学院,但官网中一栏 导师风采 并没有检索功能,只能按照拼音顺序查找老师。这一页一页点进去看导师的信息效率实在是太低,筛选过程很不方便。所以想着干脆直接用爬虫把导师信息入库,这样就能自己实现检索功能了,想怎么查就怎么查。
下面记录一下我用 Python + BeautifulSoup 爬取导师信息的过程。因为我平时不是做 Python 的,所以也是现学现卖,写的不完善的地方还请指教。
2 网站分析
2.1 导师详情页分析
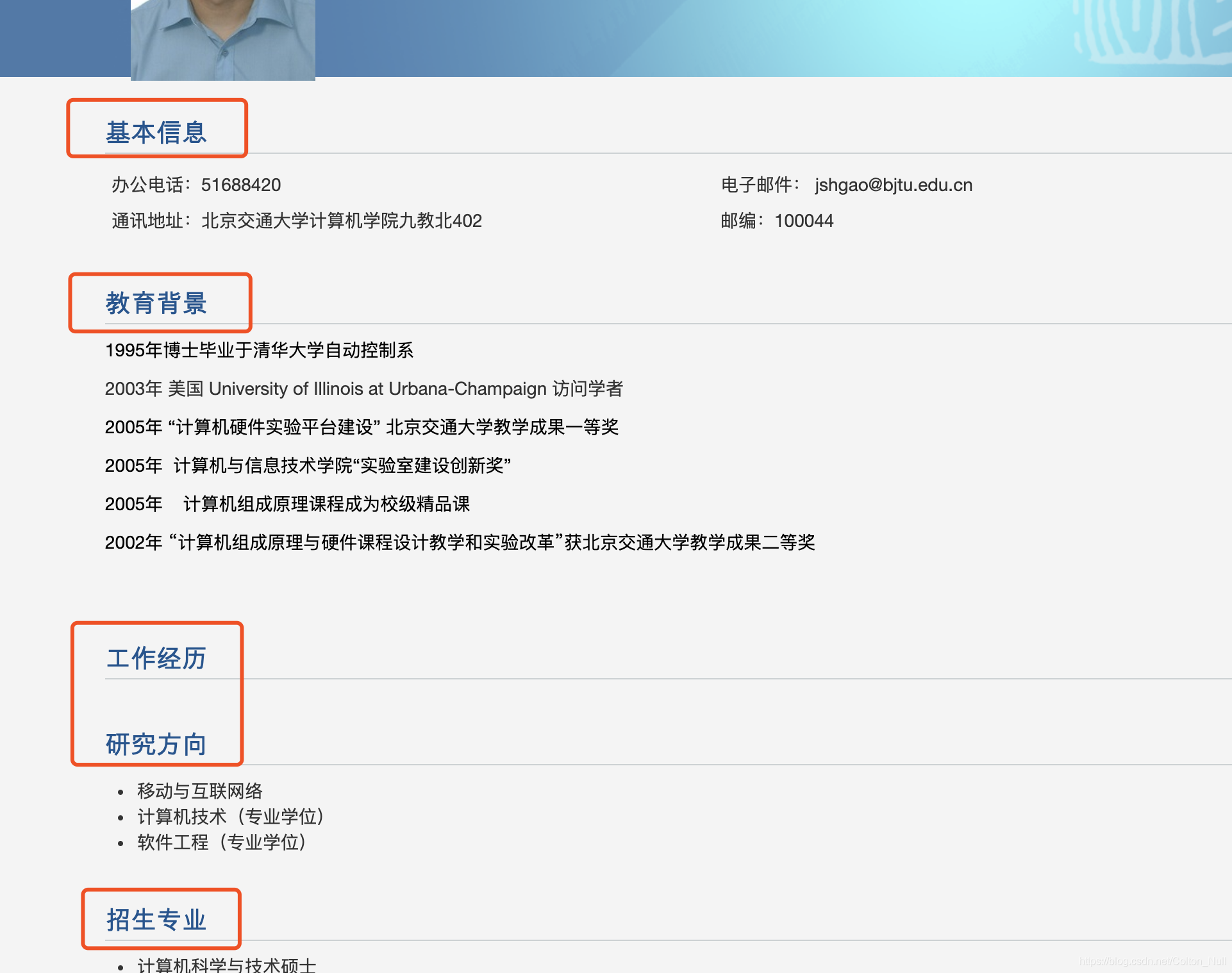
通过观察每个导师的详情页可以发现,导师的介绍页格式是统一的。每个导师的页面都有红框中的类别。这样,对爬虫工作就轻松多了,因为越简单的网站越容易爬取。
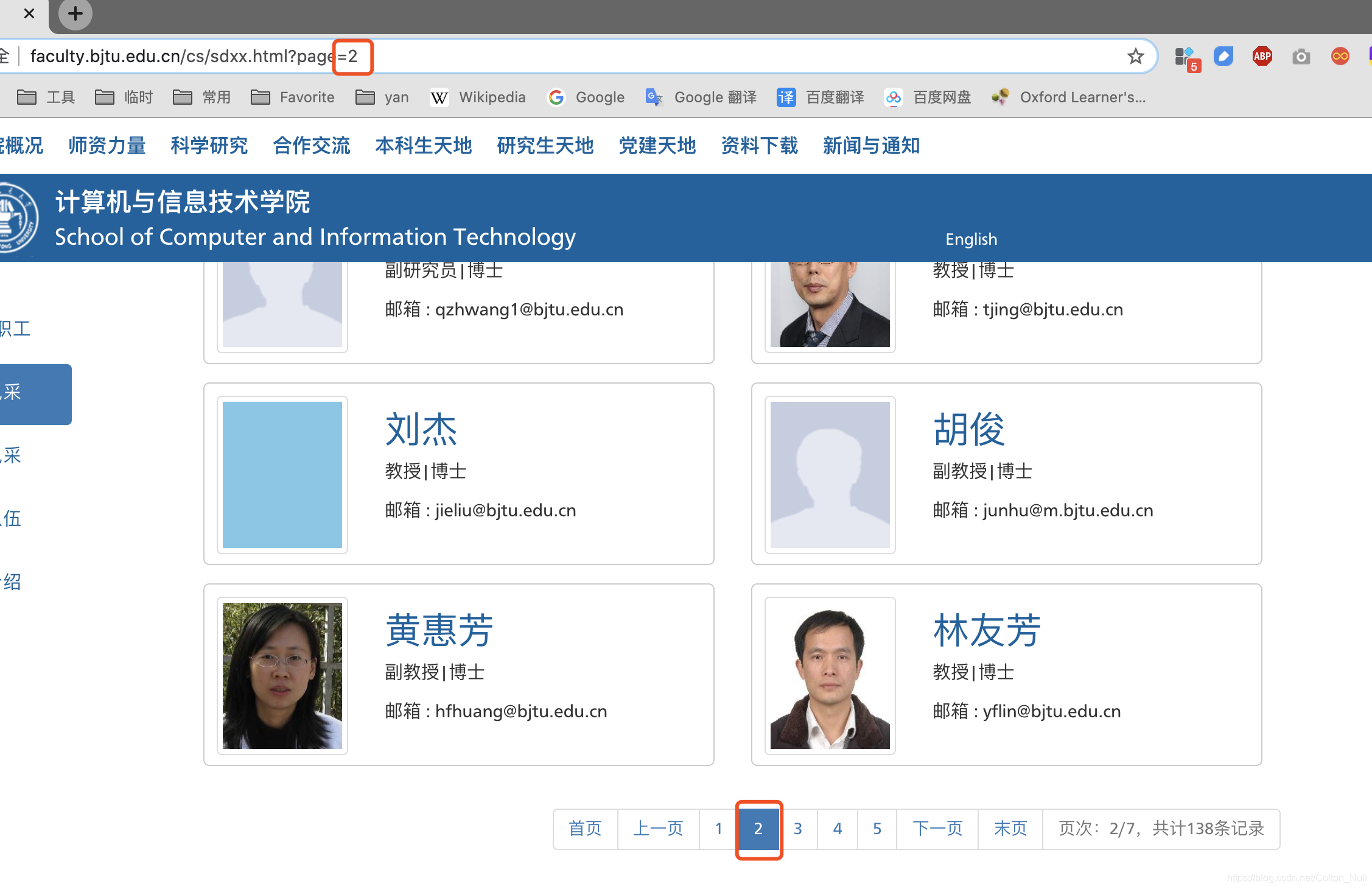
2.2 导师目录页
导师目录页以分页形式展示,分页标识是用 url 中 page 参数区分。这种情况也是比较好处理的,直接在代码中 i++ 循环即可。
2.3 思路
根据分析,可以得出:
- 先遍历目录页
- 解析每个目录页,找到每个老师的编号拼出每个导师详情页的地址
- 根据每个导师详情页地址,获取导师的详细信息并解析入库
3 代码编写
3.1 Python 版本
3.7
3.2 第三方库导入
该爬虫需要引入三个库:requests、BeautifulSoup、MySQLdb
requests:一个 Http 库
BeautifulSoup:用于解析网页数据
MySQLdb:用于与 mysql 连接
如果没有安装这三个库需要先安装。
pip3 install requests
pip3 install beautifulsoup4
pip3 install mysqlclient
3.3 遍历目录页找到每个导师的网址

通过查看目录页的源码,发现每个导师的详情页都对应一个编号。这个编号在一个 <div class="teacher_incard"> 标签下的 <a> 标签里。所以通过解析出 <a> 标签里的 href 的值,前面再拼上网站域名,就可以得到导师详情也的地址了。
具体有关 BeautifulSoup 的用法可以参考 beautifulsoup菜鸟教程。
具体代码:
def main():
# 存放每个导师详情页地址
professorList = []
# 遍历 7 页导师目录页
for i in range(1, 8):
url = 'http://faculty.bjtu.edu.cn/cs/sdxx.html?page=' + str(i)
print("正在爬取第 '%s' 页导师:" % (i))
print(url + '\n')
# 获取网页内容
html = getHTMLText(url, headers)
parseProfessorsList(professorList, html)
print("爬取链接完成")
# 解析目录页,获得每个导师的详情页地址
def parseProfessorsList(professorList, html):
# 域名
url = 'http://faculty.bjtu.edu.cn'
# 创建 soup
soup = BeautifulSoup(html, 'html.parser')
rows = soup.find_all('div', attrs={'class': 'row'})
# 第二个 row 导师信息块,根据 class="teacher_card" 解析
i = rows[1].find_all('div', attrs={'class': 'teacher_card'})
# 遍历
for professors in i:
# 找到 a 标签
a = professors.find("a")
# 拼接导师详情地址
pro = Professor(a.text.strip(), url + a.get('href'))
professorList.append(pro)
3.4 解析详情页

同理,根据分析源码里的标签,可以发现各模块标题有着相同的样式名,所以通过 BeautifulSoup 解析出来,再对内容做一些简单的处理比如:去空格、按回车切分等,即能把数据分门别类地提取出来了。
具体代码:
def parseProfessorsDetail(professor):
professor.base = ''
professor.eduBg = ''
professor.workExp = ''
professor.resOri = ''
professor.resumeMajor = ''
professor.sciResPro = ''
professor.teachWork = ''
professor.paper = ''
professor.treatise = ''
professor.patent = ''
professor.softwarePatent = ''
professor.honor = ''
professor.partTimeJob = ''
html = getHTMLText(professor.url, headers)
soup = BeautifulSoup(html, 'html.parser')
wrap = soup.find(id="wrap")
# 头像
img = wrap.find("img")
professor.img = img.get('src') + ""
# title
title = wrap.find(class_='border_p')
professor.title = title.text.strip() + ""
details = wrap.find_all(class_='mainleft_box')
for detail in details:
column = detail.find(class_='h4border').text.strip()
[s.extract() for s in detail(class_='h4border')]
contentOri = detail.text.strip()
content = ''
for line in contentOri.splitlines():
if line == '':
continue
line = line.strip() + '\n'
content = content + line
content = content.rstrip('\n') + ""
if column == '基本信息':
professor.base = content
elif column == '教育背景':
professor.eduBg = content
elif column == '工作经历':
professor.workExp = content
elif column == '研究方向':
professor.resOri = content
elif column == '招生专业':
professor.resumeMajor = content
elif column == '科研项目':
professor.sciResPro = content
elif column == '教学工作':
professor.teachWork = content
elif column == '论文/期刊':
professor.paper = content
elif column == '专著/译著':
professor.treatise = content
elif column == '专利':
professor.patent = content
elif column == '软件著作权':
professor.softwarePatent = content
elif column == '获奖与荣誉':
professor.honor = content
elif column == '社会兼职':
professor.partTimeJob = content
print(content)
insertProfessor(professor)
3.5 入库
入库的话就比较简单了
主要就是创建 cursor,执行sql,提交即可。
cursor = db.cursor()
cursor.execute(sql)
db.commit()
4 结语
至此,导师的信息就已经被录入到数据库中了。后续的话,可以通过数据库检索,或者制作个 web 页对导师信息进行检索和展示什么的,就看个人的喜好了。
该爬虫源码和建表 sql 我都放在 GitHub 上了,感兴趣的同学可以自取: Github:bjtu_cs_prof_spider。
另外我也做了个简易的在线导师检索工具,方便大家检索:北交大计算机导师在线检索工具
工具源码地址:Github:bjtu_cs_prof_spider_web
原文作者: 一只因特马
原文链接: https://www.interhorse.cn/a/2490095011/
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-ND 许可协议。转载请注明出处!














 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









