







超越编程(逾编程)(Metaprogramming)
目录
28.2.1.1 类型别名(When Not to Use an Alias)
28.2.3 选择函数(Selecting a Function)
28.2.1.1 两种类型之间的选择(Selecting between Two Types)
28.2.1.2 编译时对比运行时(Compile Time vs. Run Time)
28.2.1.3 在几种类型之间选择(Selecting among Several Types)
28.3.2 迭代和递归(Iteration and Recursion)
28.3.2.1 两种类型之间的选择(Recursion Using Classes)
28.3.3 何时使用逾编程(When to Use Metaprogramming)
28.4 条件定义(Conditional Definition): Enable_if
28.4.1 使用Enable_if (Use of Enable_if)
28.4.2 实现Enable_if (Implementing Enable_if)
28.4.3 Enable_if和概念 (Enable_if and Concepts)
28.4.4 更多关于Enable_if的例子 (More Enable_if Examples)
28.5 一个编译时列表:Tuple (A Compile-Time List: Tuple)
28.5.1 一个简单的输出函数 (A Simple Output Function)
28.6 可变参数模板(Variadic Templates)
28.6.1 一种类型安全的printf() (A Type-Safe printf())
28.6.2 技术细节(Technical Details)
28.7 国际标准(SI)单位示例(SI Units Example)
28.7.3 Unit 文字量(Unit Literals)
28.7.4 工具函数(Utility Functions)
28.1 引言(Introduction)
操纵程序实体(例如类和函数)的编程通常称为超越编程(译注:下文称“逾编程”)。我发现将模板视为代码生成器很有用:它们用于创建类和函数。这导致了模板编程的概念,即编写在编译时计算并生成程序的程序。这个思想的变体被称为两级编程、多级编程、生成编程,以及更常见的模板逾编程。
使用逾编程技术有两个主要原因:
• 提高类型安全性:我们可以计算数据结构或算法所需的确切类型,这样我们就不需要直接操作低级数据结构(例如,我们可以消除许多显式类型转换的使用)。
• 提高运行时性能:我们可以在编译时计算值并选择要在运行时调用的函数。这样,我们就不需要在运行时进行这些计算(例如,我们可以解析许多多态行为的示例以直接调用函数)。特别是,通过利用类型系统,我们可以大大提高内联的机会。此外,通过使用紧致的数据结构(可能生成;§27.4.2,§28.5),我们可以更好地利用内存,这对我们可以处理的数据量和执行速度都有积极的影响。
模板被设计为非常通用,能够生成最佳代码 [Stroustrup,1994]。它们提供算术、选择和递归。事实上,它们构成了一个完整的编译时函数式编程语言 [Veldhuizen,2003]。也就是说,模板及其模板实例化机制是图灵完备的(Turning complete)(注:图灵完备是指在可计算性理论中,一系列操作数据的规则(如指令集、编程语言、细胞自动机)按照一定的顺序可以计算出结果)。一个例证是 Eisenecker 和 Czarnecki 使用模板仅用几页就编写了一个 Lisp 解释器 [Czarnecki,2000]。C++ 编译时机制提供了一种纯函数式编程语言:您可以创建各种类型的值,但没有变量、赋值、增量运算符等。图灵完备意味着无限编译的可能性,但这很容易通过翻译限制(§iso.B)来解决。例如,如果耗尽某些编译时资源(如递归 constexpr 调用的次数、嵌套类的次数或递归嵌套模板实例的次数),就会捕获无限递归。
我们应该如何划分泛型编程和模板逾编程之间的界限?极端的立场是:
• 这都是模板逾编程:毕竟,任何编译时参数化的使用都意味着生成“普通代码”的实例化。
• 这都是泛型编程:毕竟,我们只是定义和使用泛型类型和算法。
这两种立场都是无用的,因为它们基本上将泛型编程和模板元编程定义为同义词。我认为有必要进行区分。区分有助于我们决定解决问题的替代方法,并专注于对给定问题而言重要的内容。当我编写泛型类型或算法时,我并不觉得我在编写编译时程序。我没有将我的编程技能用于程序的编译时部分。相反,我专注于定义对参数的要求(§24.3)。泛型编程主要是一种设计理念——一种编程范式(paradigm),如果你愿意这么称呼的话(§1.2.1)。
相比之下,逾编程就是编程。重点是计算上的区别,通常涉及选择和某种形式的迭代。逾编程主要是一组实现技术。我可以想到四个级别的实现复杂性:
[1] 无计算(仅传递类型和值参数)
[2] 不使用编译时测试或迭代的简单计算(针对类型或值),例如bool值的 &&(§24.4)或单位的加法(§28.7.1)
[3] 使用显式编译时测试的计算,例如编译时 if(§28.3)。
[4] 使用编译时迭代的计算(以递归形式;§28.3.2)。
顺序表明了复杂性的级别,任务难度的影响、调试难度的影响以及出现错误的可能性的影响。
因此,逾编程是“逾(meta)”和编程(programming)的结合:逾程序(metaprogram)是一种编译时计算,可产生运行时使用的类型或函数。请注意,我没有说“模板逾编程(template metaprogramming)”,因为计算可以使用 constexpr 函数完成。还请注意,您可以依赖其他人的逾编程,而无需自己实际进行逾编程:调用隐藏逾程序的 constexpr 函数(§28.2.2)或从模板类型函数中提取类型(§28.2.4)本身并不是逾编程;它只是使用逾程序。
泛型编程通常属于第一类“无计算”类别,但使用逾编程技术完全可以支持泛型编程。在这样做时,我们必须小心,确保我们的接口规范得到精确定义和正确实施。一旦我们将(逾)编程用作接口的一部分,编程错误的可能性就会悄然出现。如果没有编程,含义将直接由语言规则定义。
泛型编程注重接口规范,而逾编程通常以类型作为值的编程。
过度使用逾编程会导致调试问题和过多的编译时间,从而使某些用途不切实际。一如既往,我们必须运用常识。逾编程有许多简单的用途,可以产生更好的代码(更好的类型安全性、更低的内存占用和更低的运行时间),而不会产生异常的编译时开销。许多标准库组件,如function (§33.5.3)、thread(§5.3.1,§42.2.2)和tuple(§34.2.4.2),都是相对简单应用逾编程技术的示例。
本章探讨了基本的逾编程技术,并介绍了逾程序的基本构建块。第 29 章提供了更广泛的示例。
28.2 类型函数(Type Functions)
类型函数是接受至少一个类型参数或产生至少一个类型结果的函数。例如,sizeof(T) 是一个内置类型函数,给定一个类型参数 T,它会返回对象的大小(以字符为单位;§6.2.8)。
类型函数不必看起来像传统函数。事实上,大多数都不是函数。例如,标准库的 is_polymorphic<T> 将其参数作为模板参数并将其结果作为名为 value 的成员返回:
if (is_polymorphic<int>::value) cout << "Big surprise!";
is_polymorphic 的值成员要么是 true,要么是 false。同样,标准库的约定是一种类型函数,其通过一个称为type的成员返回一个类型。例如:
enum class Axis : char { x, y, z };
enum flags { off, x=1, y=x<<1, z=x<<2, t=x<<3 };
typename std::underlying_type<Axis>::type x; // x 是一个 char
typename std::underlying_type<Axis>::type y; // y 可能是一个 int (§8.4.2)
类型函数可以接受多个参数并返回多个结果值。例如:
template<typename T, int N>
struct Array_type {
using type = T;
static const int dim = N;
// ...
};
这个 Array_type 不是标准库函数,甚至不是一个特别有用的函数。我只是用它作为借口来展示如何编写一个简单的多参数、多返回值类型函数。它可以像这样使用:
using Array = Array_type<int,3>;
Array::type x; // x 是一个 int
constexpr int s = Array::dim; // s is 3
类型函数是编译时函数。也就是说,它们只能接受编译时已知的参数(类型和值)并产生可在编译时使用的结果(类型和值)。
大多数类型函数至少接受一个类型参数,但有些有用的函数不接受。例如,以下是一个返回适当字节数的整数类型的类型函数:
template<int N>
struct Integer {
using Error = void;
using type = Select<N,Error,signed char,shor t,Error,int,Error,Error,Error,long>;
};
typename Integer<4>::type i4 = 8; // 4-byte integer
typename Integer<1>::type i1 = 9; // 1-byte integer
Select 在 §28.3.1.3 中定义和解释。当然可以编写仅接受值并仅生成值的模板。我不考虑那些类型函数。此外,constexpr 函数(§12.1.6)通常是表达编译时值计算的更好方法。我可以使用模板在编译时计算平方根,但是当我可以使用 constexpr 函数(§2.2.3,§10.4,§28.3.2)更清晰地表达算法时,我为什么要这样做呢?
因此,C++ 类型函数大多是模板。它们可以使用类型和值执行非常通用的计算。它们是逾编程的支柱。例如,我们可能希望在栈上分配一个对象(前提是它很小),否则在自由存储中分配:
constexpr int on_stack_max = sizeof(std::string);//我们想在栈上分配的最大对象大小
template<typename T>
struct Obj_holder {
using type = typename std::conditional<(sizeof(T)<=on_stack_max),
Scoped<T>, // 第一选择
On_heap<T> // 第二选择
>::type;
};
标准库模板 conditional 是两个备选方案之间的编译时选择器。如果其第一个参数求值为真,则结果(以成员type表示)为第二个参数;否则,结果为第三个参数。§28.3.1.1 显示了conditional的实现方式。在这种情况下,如果 X 的对象较小,则 Obj_holder<X> 的类型定义为 Scoped<X>,如果较大,则定义为 On_heap<X>。Obj_holder 可以这样使用:
void f()
{
typename Obj_holder<double>::type v1; // the double goes on the stack
typename Obj_holder<array<double ,200>>::type v2; // the array goes on the free store
// ...
∗v1 = 7.7; // Scoped provides pointer-like access (* and [])
v2[77] = 9.9; // On_heap provides pointer-like access (* and [])
// ...
}
Obj_holder 示例并非假设。例如,C++ 标准在其 function 类型定义(§33.5.3)中包含以下注释,用于保存类似函数这样的实体:“鼓励实现避免将动态分配的内存用于存储小型可调用对象,例如,f 的目标是仅保存指向对象的指针或引用和成员函数指针的对象”(§iso.20.8.11.2.1)。如果没有像 Obj_holder 这样的东西,很难遵循这一建议。
Scoped 和 On_heap 是如何实现的?它们的实现很简单,不涉及任何逾编程,但它们如下:
template<typename T>
struct On_heap {
On_heap() :p(new T) { } // allocate
˜On_heap() { delete p; } // deallocate
T& operator∗() { return ∗p; }
T∗ operator−>() { return p; }
On_heap(const On_heap&) = delete; // 阻止复制
On_heap operator=(const On_heap&) = delete;
private:
T∗ p; //指向自由存储区对象的指针
};
template<typename T>
struct Scoped {
T& operator∗() { return x; }
T∗ operator−>() { return &x; }
Scoped(const Scoped&) = delete; // 阻止复制
Scoped operator=(const Scoped&) = delete;
private:
T x; // 对象
};
On_heap 和 Scoped 提供了很好的例子,说明泛型编程和模板逾编程如何要求我们为一般思想(这里指对象分配的思想)的不同实现设计统一的接口。
On_heap 和 Scoped 都可以用作成员和局部变量。On_heap 总是将其对象放在自由存储中,而 Scoped 包含其对象。
§28.6 展示了如何为采用构造函数参数的类型实现 On_heap 和 Scoped 的版本。
28.2.1 类型别名(Type Aliases)
请注意,当我们使用 typename 和 ::type 提取成员类型时,Obj_holder(对于 int)的实现细节是如何显现出来的。这是语言指定和使用方式的结果,这是过去 15 年模板逾编程代码的编写方式,也是它在 C++11 标准中的出现方式。我认为这是无法忍受的。它让我想起了 C 语言中的糟糕旧时代,当时每个用户定义类型的出现都必须以 struct 关键字为前缀。通过引入模板别名(§23.6),我们可以隐藏 ::type 实现细节,并使类型函数看起来更像返回类型的函数(或像类型)。例如:
template<typename T>
using Holder = typename Obj_holder<T>::type;
void f2()
{
Holder<double> v1;
// double储于栈上
Holder<array<double ,200>> v2; // array储于自由存储区
// ...
∗v1 = 7.7; // Scoped 提供了类似指针的访问 (* 和 [])
v2[77] = 9.9; // On_heap 提供了类似指针的访问 (* 和 [])
// ...
}
除了解释实现或标准具体提供的内容时,我会系统地使用此类类型别名。当标准提供类型函数(称为“类型属性谓词”或“复合类型类别谓词”)时,例如条件函数,我会定义相应的类型别名(§35.4.1):
template<typename C, typename T, typename F>
using Conditional = typename std::conditional<C,T,F>::type;
请注意,这些别名很遗憾不是标准的一部分。
28.2.1.1 类型别名(When Not to Use an Alias)
有一种情况,直接使用::type 而不是别名很重要。如果只有一个替代方案被认为是有效类型,则我们不应该使用别名。首先考虑一个简单的类比:
if (p) {
p−>f(7);
// ...
}
重要的是,如果 p 是 nullptr,我们不要进入该块。我们使用测试来查看 p 是否有效。同样,我们可能想要测试某个类型是否有效。例如:
conditional<
is_integral<T>::value ,
make_unsigned<T>,
Error<T>
>::type
这里,我们测试 T 是否为整数类型(使用 std::is_integral 类型谓词),如果是,则生成该类型的无符号变体(使用 std::make_unsigned 类型函数)。如果成功,则我们得到一个无符号类型;否则,我们将不得不处理错误指示符。
如果我们写了 Make_unsigned<T> 含义
typename make_unsigned<T>::type
并尝试将其用于非整数类型,例如 std::string,我们将尝试创建一个不存在的类型 (make_unsigned<std::string>::type)。结果将是一个编译时错误。
在极少数情况下,我们无法一致地使用别名来隐藏 ::type,因此我们可以采用更明确、面向实现的 ::type 样式。或者,我们可以引入 Delay 类型函数来延迟对类型函数的求值,直到使用它为止:
Conditional<
is_integral<T>::value ,
Delay<Make_unsigned,T>,
Error<T>
>
完美延迟函数的实现并不简单,但对于许多用途来说,这已经足够了:
template<template<typename...> class F, typename ... Args>
using Delay = F<Args...>;
这使用了模板的模板参数(§25.2.4)和可变参数模板(§28.6)。
无论我们选择哪种解决方案来避免不良实例,这都是我带着一些恐惧进入的专家领域。
28.2.2 类型谓词(Type Predicates)
谓词是返回bool值的函数(译注:即下判断,得出真假值,predicate的本意就是“判断”)。如果你想编写接受类型参数的函数,那么显然你会想问一些有关参数类型的问题。例如:这是一个有符号类型吗?这个类型是多态的吗(即它至少有一个虚函数吗)?这个类型是从那个类型派生出来的吗?
编译器知道许多此类问题的答案,并通过一组标准库类型谓词 (§35.4.1) 向程序员公开。例如:
template<typename T>
void copy(T∗ p, const T∗ q, int n)
{
if (std::is_pod<T>::value)
memcpy(p,q,n); // 使用优化内存复制
else
for (int i=0; i!=n; ++i)
p[i] = q[i]; // 复制单个值
}
在这里,当我们可以将对象视为“普通旧数据”(POD;§8.2.6)时,我们尝试使用(据称最佳的)标准库函数 memcpy() 来优化复制。如果不能,我们将使用它们的复制构造函数逐个复制对象(可能)。我们通过标准库类型谓词 is_pod 确定模板参数类型是否为 POD。结果由成员 value 表示。此标准库约定类似于类型函数将其结果表示为成员type的方式。
std::is_pod 谓词是标准库 (§35.4.1) 提供的众多谓词之一。由于 POD 的规则很棘手,因此 is_pod 很可能是编译器固有函数,而不是在库中作为 C++ 代码实现的。
与 ::type 约定一样,值 ::value 会导致冗长,并且背离了传统的表示法,使实现细节得以体现:返回 bool 的函数应使用 () 进行调用:
template<typename T>
void copy(T∗ p, const T∗ q, int n)
{
if (is_pod<T>())
// ...
}
幸运的是,标准支持所有标准库类型谓词。遗憾的是,由于语言技术原因,此解析在模板参数上下文中不可用。例如:
template<typename T>
void do_something()
{
Conditional<is_pod<T>(),On_heap<T>,Scoped<Y>) x; // 错 : is_pod<T>() 是一个type
// ..
}
具体来说,is_pod<T> 被解释为不接受任何参数并返回 is_pod<T> 的函数类型 (§iso.14.3[2])。
我的解决方案是添加函数以在所有上下文中提供常规符号:
template<typename T>
constexpr bool Is_pod()
{
return std::is_pod<T>::value;
}
我将这些类型函数的名称大写,以避免与标准库版本混淆。此外,我将它们保存在单独的命名空间 (Estd) 中。
我们可以定义自己的类型谓词。例如:
template<typename T>
constexpr bool Is_big()
{
return 100<sizeof(T);
}
我们可以像这样使用这个(相当粗糙的)“大”的概念:
template<typename T>
using Obj_holder = Conditional<(Is_big<T>()), Scoped<T>, On_heap<T>>;
很少需要定义直接反映类型基本属性的谓词,因为标准库提供了很多这样的谓词。例如 is_integral,is_pointer,is_empty,is_polymorphic 和 is_move_assignable(§35.4.1)。当我们必须定义这样的谓词时,我们有相当强大的技术可用。例如,我们可以定义一个类型函数来确定一个类是否具有给定名称和适当类型的成员(§28.4.4)。
当然,具有多个参数的类型谓词也很有用。具体来说,这就是我们表示两种类型之间关系的方式,例如 is_same, is_base_of 和 is_convertible。这些也来自标准库。
我使用 Is_∗ constexpr 函数来支持所有这些 is_∗ 函数的通常 () 调用语法。
28.2.3 选择函数(Selecting a Function)
函数对象是某种类型的对象,因此选择类型和值的技术可以用于选择函数。例如:
struct X { // write X
void operator()(int x) { cout <<"X" << x << "!"; }
// ...
};
struct Y { // write Y
void operator()(int y) { cout <<"Y" << y << "!"; }
// ...
};
void f()
{
Conditional<(sizeof(int)>4),X,Y>{}(7); // 创建一个 X 或一个Y 并调用它
using Z = Conditional<(Is_polymorphic<X>()),X,Y>;
Z zz; //make an X or a Y
zz(7); // call an X or a Y
}
如图所示,选定的函数对象类型可以立即使用或“记住”以供以后使用。具有计算某些值的成员函数的类是模板逾编程中最通用和最灵活的计算机制。
条件是一种编译时编程机制。具体来说,这意味着条件必须是常量表达式。请注意 sizeof(int) > 4 周围的括号;如果没有这些括号,我们会得到一个语法错误,因为编译器会将 > 解释为模板参数列表的结尾。出于这个原因(以及其他原因),我更喜欢使用 <(小于)而不是 >(大于)。此外,我有时会在条件周围使用括号以提高可读性。
28.2.4 特征类型函数(Traits)
标准库严重依赖traits。一个trait用于将属性与类型关联起来。例如,迭代器的属性由其 iterator_traits (§33.1.3) 定义:
template<typename Iterator>
struct iterator_traits {
using difference_type = typename Iterator::difference_type;
using value_type = typename Iterator::value_type;
using pointer = typename Iterator::pointer;
using reference = typename Iterator::reference;
using iterator_category = typename Iterator::iterator_category;
};
您可以将trait 视为具有多种结果的一个类型函数或一组类型函数。
标准库提供了allocator_traits (§34.4.2) ,char_traits (§36.2.2) ,iterator_traits (§33.1.3) ,regex_traits (§37.5) ,pointer_traits (§34.4.3)。此外,它还提供了 time_traits (§35.2.4)和 type_traits (§35.4.1),令人困惑的是,它们是简单类型函数。
已知指针的 iterator_traits,我们可以讨论指针的 value_type 和 difference_type,即使指针没有成员:
template<typename Iter>
Iter search(Iter p, Iter q, typename iterator_traits<Iter>::value_type val)
{
typename iterator_traits<Iter>::difference_type m = q−p;
// ...
}
这是一种非常实用和强大的技术,但是:
• 它很冗长。
• 它通常捆绑其他弱相关的类型函数。
• 它向用户公开实现细节。
此外,人们有时会为了“以防万一”而添加类型别名,这会导致不必要的复杂性。因此,我更喜欢使用简单的类型函数:
template<typename T>
using Value_type = typename std::iterator_trait<T>::value_type;
template<typename T>
using Difference_type = typename std::iterator_trait<T>::difference_type;
template<typename T>
using Iterator_category= typename std::iterator_trait<T>::iterator_category;
该示例非常清晰:
template<typename Iter>
Iter search(Iter p, iter q, Value_type<Iter> val)
{
Difference_type<Iter> m = q−p;
// ...
}
我怀疑trait目前被过度使用了。考虑一下如何在不提及trait或其他类型函数的情况下编写前面的示例:
template<typename Iter, typename Val>
Iter search(Iter p, iter q, Val val)
{
auto x = ∗p; //若我们不必命名 *p 的类型
auto m = q−p; // 若我们不必命名 q-p的类型
using value_type = decltype(∗p); //若我们想命令 *p的类型
using difference_type = decltype(q−p); // 若我们想命令 q-p的类型
// ...
}
当然,decltype() 是一个类型函数,所以我所做的就是消除用户定义和标准库类型函数。此外,auto 和 decltype 是 C++11 中的新增功能,因此旧代码不能以这种方式编写。
我们需要一个特殊类型函数(或等价特殊类型函数,例如 decltype())来将一个类型与另一个类型关联起来,例如将 value_type 与 T∗ 关联起来。为此,特殊类型函数(或等价特殊类型函数)对于非侵入式地添加通用编程或逾编程所需的类型名称是必不可少的。当 特殊类型函数仅用于为已经具有完美名称的事物提供名称时,例如将指针用于 value_type∗ 和将引用用于 value_type&,其实用性会变得不那么明确,并且混淆的可能性会更大。不要盲目地为一切事物定义特殊类型函数,以防万一。
28.3 控制结构(Control Structures)
为了在编译时进行一般计算,我们需要选择和递归。
28.3.1 选择(Selection)
除了使用普通常量表达式(§10.4)简单完成的操作,我还使用:
• Conditional:在两种类型之间进行选择的方式( std::conditional 的别名)
• Select::在几种类型之间进行选择的方式(定义见 §28.3.1.3)
这些类型函数返回类型。如果您想在值之间进行选择,?: 就足够了;Conditional 和 Select 用于选择类型。它们并不是简单地等同于 if 和 switch 的编译时函数,尽管当它们用于在函数对象之间进行选择时看起来是这样的(§3.4.3,§19.2.2)。
28.2.1.1 两种类型之间的选择(Selecting between Two Types)
实现Conditional模板非常简单,如 §28.2 中所使用的。conditional模板是标准库的一部分(在 <type_traits> 中),因此我们不必实现它,但它说明了一种重要的技术:
template<bool C, typename T, typename F> // 一般模板
struct conditional {
using type = T;
};
template<typename T, typename F> // false 特化
struct conditional<false,T,F> {
using type = F;
};
主模板 (§25.3.1.1) 仅将其type定义为 T(条件后的第一个模板参数)。如果条件不为true,则选择 false 的特化并将type定义为 F。例如:
typename conditional<(std::is_polymorphic<T>::value),X,Y>::type z;
显然,语法还有点不足(§28.2.2),但底层逻辑很漂亮。
特化用于将一般情况与一个或多个特化情况区分开来(§25.3)。在此示例中,主模板只负责一半的功能,但这一部分可能不尽相同,从零(每个非错误情况都由特化处理;§25.3.1.1)到除单个终止情况之外的所有情况(§28.5)。这种形式的选择完全是编译时进行的,运行时不会花费一个字节(的处理时间)或一个(时钟)周期。
为了改进语法,我引入了类型别名:
template<bool B, typename T, typename F>
using Conditional = typename std::conditional<B,T,F>::type;
鉴于此,我们可以写出:
Conditional<(Is_polymorphic<T>()),X,Y> z;
我认为这是一个显著的进步。
28.2.1.2 编译时对比运行时(Compile Time vs. Run Time)
看着类似的东西:
Conditional<(std::is_polymorphic<T>::value),X,Y> z;
第一次遇到这种情况时,人们通常会想,“我们为什么不写一个普通的 if 呢?”考虑在 Square 和 Cube 这两个替代方案之间进行选择:
struct Square {
constexpr int operator()(int i) { return i∗i; }
};
struct Cube {
constexpr int operator()(int i) { return i∗i∗i; }
};
我们好可以尝试熟悉的 if 语句:
if (My_cond<T>())
using Type = Square; // 错误:作为 if 语句分支而申明
else
using Type = Cube; // 错误:作为 if 语句分支而申明
Type x; // 错 : Type 不在作用域内
声明不能是 if 语句分支的唯一语句(§6.3.4,§9.4.1),因此即使 My_cond<T>() 在编译时计算,这也不起作用。因此,普通的 if 语句对于普通表达式有用,但对于类型选择则无用。
让我们尝试一个不涉及定义变量的例子:
Conditional<My_cond<T>(),Square,Cube>{}(99); // 调用 Square{}(99)或Cube{}(99)
也就是说,选择一个类型,构造该类型的默认对象,然后调用它。这样就行了。使用“传统控制结构”,这将变成:
((My_cond<T>())?Square:Cube){}(99);
此示例不起作用,因为 Square{}(99) 和 Cube{}(99) 不会产生类型,而是产生条件表达式中兼容类型的值(§11.1.3)。我们可以尝试
(My_cond<T>()?Square{}:Cube{})(99); // 错 : 对 ?: 的不兼容参数
遗憾的是,这个版本仍然存在 Square{} 和 Cube{} 不是兼容类型,不能作为 ?: 表达式中的替代类型。在逾编程中,兼容类型的限制通常是不可接受的,因为我们需要在不明确相关的类型之间进行选择。
最后,下列语句会有效:
My_cond<T>()?Square{}(99):Cube{}(99);
此外,它的可读性并不比
Conditional<My_cond<T>(),Square,Cube>{}(99);
28.2.1.3 在几种类型之间选择(Selecting among Several Types)
在 N 个选项中进行选择与在两个选项中进行选择非常相似。下面是一个返回其第 N 个参数类型的类型函数:
class Nil {};
template<int I, typename T1 =Nil, typename T2 =Nil, typename T3 =Nil, typename T4 =Nil>
struct select;
template<int I, typename T1 =Nil, typename T2 =Nil, typename T3 =Nil, typename T4 =Nil>
using Select = typename select<I,T1,T2,T3,T4>::type;
// 对 0-3 的特化:
template<typename T1, typename T2, typename T3, typename T4>
struct select<0,T1,T2,T3,T4> { using type = T1; }; // 特化为 N==0
template<typename T1, typename T2, typename T3, typename T4>
struct select<1,T1,T2,T3,T4> { using type = T2; }; // 特化为 N==1
template<typename T1, typename T2, typename T3, typename T4>
struct select<2,T1,T2,T3,T4> { using type = T3; }; // 特化为 N==2
template<typename T1, typename T2, typename T3, typename T4>
struct select<3,T1,T2,T3,T4> { using type = T4; }; // 特化为 N==3
永远不要使用 select 的通用版本,所以我没有定义它。我选择了从零开始的编号来匹配 C++ 的其余部分。这种技术非常通用:这样的特化可以呈现模板参数的任何方面。我们实际上并不想选择最大数量的替代方案(这里是四个),但可以使用可变参数模板(§28.6)来解决该问题。选择不存在的替代方案的结果是使用主(通用)模板。例如:
Select<5,int,double ,char> x;
在这种情况下,由于未定义通用 Select,因此会导致立即出现编译时错误。
实际的用途是选择返回元组第 N 个元素的函数的类型:
template<int N, typename T1, typename T2, typename T3, typename T4>
Select<N,T1,T2,T3,T4> get(Tuple<T1,T2,T3,T4>& t); // see §28.5.2
auto x = get<2>(t); // 假设 t 是一个Tuple
此处,x 的类型将是名为 t 的元组的 T3。元组的索引从零开始。
使用可变参数模板(§28.6),我们可以提供一个更简单、更通用的选择:
template<unsigned N, typename... Cases> // 一般情况; 从不实例化
struct select;
template<unsigned N, typename T, typename ... Cases>
struct select<N,T,Cases...> :select<N−1,Cases...> {
};
template<typename T, typename ... Cases> // final case: N==0
struct select<0,T,Cases...> {
using type = T;
};
template<unsigned N, typename... Cases>
using Select = typename select<N,Cases...>::type;
28.3.2 迭代和递归(Iteration and Recursion)
编译时计算值的基本技术可以通过阶乘函数模板来说明:
template<int N>
constexpr int fac()
{
return N∗fac<N−1>();
}}
template<>
constexpr int fac<1>()
{
return 1;
}
constexpr int x5 = fac<5>();
阶乘是使用递归而不是循环来实现的。由于我们在编译时没有变量(§10.4),所以这样做是有道理的。一般来说,如果我们想在编译时迭代一组值,我们会使用递归。
请注意,这里没有条件:没有 N==1 或 N<2 测试。相反,当 fac() 调用选择 N==1 的特化时,递归终止。在模板逾编程(如函数式编程)中,处理一系列值的惯用方法是递归,直到达到终止特化。
在这种情况下,我们也可以采用更常规的方式进行计算:
constexpr int fac(int i)
{
return (i<2)?1:fac(i−1);
}
constexpr int x6 = fac(6);
我发现这比函数模板表达的思想更清晰,但口味各不相同,有些算法最好通过将终止情况与一般情况分开来表达。非模板版本对于编译器来说稍微容易处理。运行时性能当然是相同的。
constexpr 版本可用于编译时和运行时求值。模板(逾编程)版本仅供编译时使用。
28.3.2.1 两种类型之间的选择(Recursion Using Classes)
涉及更复杂状态或更复杂参数化的迭代可以使用类来处理。例如,阶乘程序变为:
template<int N>
struct Fac {
static const int value = N∗Fac<N−1>::value;
};
template<>
struct Fac<1> {
static const int value = 1;
};
constexpr int x7 = Fac<7>::value;
要查看更现实的示例,请参见§28.5.2。
28.3.3 何时使用逾编程(When to Use Metaprogramming)
使用此处描述的控制结构,你可以在编译时计算所有内容(翻译限制允许)。问题仍然存在:你为什么要这样做?如果这些技术比其他技术产生更干净、性能更好、更易于维护的代码,我们就应该使用这些技术。逾编程最明显的限制是,依赖于模板的复杂用法的代码可能难以阅读且很难调试。模板的非平凡用法也会影响编译时间。如果您很难理解需要复杂实例化模式的代码中发生了什么,那么编译器也可能如此。更糟糕的是,维护你的代码的程序员也可能如此。
模板逾编程吸引了聪明人:
• 部分原因是,逾编程允许我们表达无法以相同类型安全性和运行时性能完成的事情。当改进显著且代码可维护时,这些都是很好的理由,有时甚至是令人信服的理由。
• 部分原因是,逾编程允许我们炫耀自己的聪明才智。显然,这是应该避免的。
你如何知道逾编程已经走得太远?我使用的一个警告信号是使用宏(§12.6)来隐藏那些太难看而无法直接处理的“细节”。考虑一下:
#define IF(c,x,y) typename std::conditional<(c),x,y>::type
这是否太过分了?它允许我们写出
IF(cond,Cube,Square) z;
而不是
typename std::conditional<(cond),Cube,Square>::type z;
我使用非常短的名称 IF 和长形式 std::conditional 来偏向这个问题。
类似地,更复杂的条件几乎会平衡所使用的字符数。根本的区别在于,我必须编写 typename 和 ::type 才能使用标准的术语。这暴露了模板实现技术。我想隐藏这一点,宏也可以。但是,如果许多人需要协作并且程序变得庞大,那么冗长一点总比分歧的符号要好。
另一个反对 IF 宏的严重论点是,它的名称具有误导性:conditional 不是传统 if 的“直接替代品”。::type 代表了一个显著的区别:conditional 在类型之间进行选择;它不会直接改变控制流。有时它用于选择一个函数,从而表示计算中的分支;有时则不是。IF 宏隐藏了其功能的一个基本方面。许多其他“合理”的宏也存在类似的反对意见:它们以某些程序员对其用途的特定想法命名,而不是反映基本功能。
在这种情况下,冗长、实现细节泄露和命名不当的问题可以通过类型别名轻松解决(条件;§28.2.1)。一般来说,要努力寻找方法来清理呈现给用户的语法,而无需发明一种私有语言。优先使用系统技术,例如特化和使用别名,而不是宏黑客。对于编译时计算,优先使用 constexpr 函数而不是模板,并尽可能在 constexpr 函数中隐藏模板逾编程实现细节(§28.2.2)。
或者,我们可以看看我们正在尝试做的事情的根本复杂性:
[1] 它需要显式测试吗?
[2] 它需要递归吗?
[3] 我们可以为模板参数编写概念(§24.3)吗?
如果问题 [1] 或 [2] 的答案是“是”,或者问题 [3] 的答案是“否”,那么我们应该考虑是否存在维护问题。也许某种形式的封装是可能的?请记住,只要实例化失败,模板实现的复杂性就会对用户可见(“泄露”)。此外,许多程序员确实会查看头文件,其中会立即暴露逾程序的每个细节。
28.4 条件定义(Conditional Definition): Enable_if
当我们编写模板时,有时我们想为某些模板参数提供操作,但不为其他模板参数提供操作。例如:
template<typename T>
class Smart_pointer {
// ...
T& operator∗(); // return reference to whole object
T∗ operator−>(); // select a member (for classes only)
// ...
}
如果 T 是一个类,我们应该提供 operator−>(),但如果 T 是一个内置类型,我们就不能这样做(使用通常的语义)。因此,我们需要一种语言机制来表示“如果此类型具有此属性,则定义以下内容。”我们可以尝试显而易见的方法:
template<typename T>
class Smart_pointer {
// ...
T& operator∗(); //返回指向整个对象的引用
if (Is_class<T>()) T∗ operator−>(); // 语法错误
// ...
}
但是,这行不通。C++ 没有提供可以根据一般条件在定义中进行选择的 if 。但是,与 Conditional 和 Select(§28.3.1)一样,有一种方法。我们可以编写一个有点奇怪的类型函数来使 operator−>() 的定义具有条件性。标准库(在 <type_traits> 中)为此提供了 enable_if。Smart_pointer 示例变为:
template<typename T>
class Smart_pointer {
// ...
T& operator∗(); //返回指向整个对象的引用
Enable_if<Is_class<T>(),T>∗ operator−>(); // 选择一个成员 (仅为类)
// ...
}
与往常一样,我使用类型别名和 constexpr 函数来简化符号:
template<bool B, typename T>
using Enable_if = typename std::enable_if<B,T>::type;
template<typename T> bool Is_class()
{
return std::is_class<T>::value;
}
如果 Enable_if 的条件计算结果为真,则其结果为第二个参数(此处为 T )。如果 Enable_if 的条件计算结果为假,则其所属的整个函数声明将被完全忽略。在这种情况下,如果 T 是一个类,我们会得到一个返回 T∗ 的 operator−>() 的定义,如果不是,则我们不声明任何内容。
已知使用Enable_if的Smart_pointer的定义,我们得到:
void f(Smart_pointer<double> p, Smart_pointer<complex<double>> q)
{
auto d0 = ∗p; //OK
auto c0 = ∗q; //OK
auto d1 = q−>real(); // OK
auto d2 = p−>real(); // 错: p 并不指向类对象
// ...
}
您可能认为 Smart_pointer 和 operator−>() 很奇特,但有条件地提供(定义)操作却很常见。标准库提供了许多条件定义的示例,例如 Alloc::size_type (§34.4.2) 和如果两个元素都是可移动的 pair (§34.2.4.1)。语言本身仅为指向类对象的指针定义 −> (§8.2)。
在这种情况下,使用 Enable_if 对 operator−>() 声明的详细说明只是改变了我们从示例中得到的错误类型,例如 p−>real():
•如果我们无条件地声明operator−>(),则在实例化 Smart_pointer<double>::operator−>() 的定义时,我们会得到一个“−> used on a non-class pointer”错误。
- 如果我们使用 Enable_if 有条件地声明 operator−>(),如果我们在 smart_ptr<double> 上使用 −>,则在使用 Smart_ptr<double>::operator−>() 时,我们会得到一个“Smart_ptr<double>::operator−>() not defined”错误。
在任何一种情况下,除非我们在 smart_ptr<T> 上使用 −>(其中 T 不是类),否则我们都不会收到错误。
我们已经将错误检测和报告从 smart_pointer<T>::operator−>() 的实现移到了其声明中。根据编译器,尤其是错误发生在模板实例嵌套的深度,这可能会产生很大的不同。一般来说,最好精确指定模板以便尽早检测错误,而不是依赖于捕获错误的实例。从这个意义上讲,我们可以将 Enable_if 视为概念(§24.3)的一种变体:它允许更精确地指定模板的要求。
28.4.1 使用Enable_if (Use of Enable_if)
对于许多用途来说,enable_if 的功能非常理想。但是,我们必须使用的符号通常很尴尬。考虑一下:
Enable_if<Is_class<T>(),T>∗ operator−>();
实现效果相当引人注目。然而,实际表达的内容非常接近最小理想:
declare_if (Is_class<T>()) T∗ operator−>(); // 非C++
然而,C++ 没有用于选择声明的 declared_if 结构。
使用 Enable_if 修饰返回类型会将其放在前面,你可以看到它,并且它在逻辑上属于它,因为它会影响整个声明(而不仅仅是返回类型)。但是,有些声明没有返回类型。考虑两个 vector 的构造函数:
template<typename T>
class vector<T> {
public:
vector(size_t n, const T& val); // 具有值 val的类型 T 的 n 个元素
template<typename Iter>
vector(Iter b, Iter e); // 从 [b:e) 初始化
// ...
};
这看上去没什么问题,但是构造函数接受多个元素会破坏其通常的破坏。考虑一下:
vector<int> v(10,20);
这是 10 个元素,值为 20,还是尝试从 [10:20] 初始化?标准要求前者,但上面的代码会天真地选择后者,因为第一个构造函数需要 int 到 size_t 的转换,而 int 对与模板构造函数完美匹配。问题是我“忘记”告诉编译器 Iter 类型应该是迭代器。但是,可以这样做:
template<typename T>
class vector<T> {
public:
vector(size_t n, const T& val); // 具有值 val的类型 T 的 n 个元素
template<typename Iter, typename =Enable_if<Input_iterator<Iter>(),Iter>>
vector(Iter b, Iter e); // 从[b:e) 初始化
// ...
};
该(未使用的)默认模板参数将被实例化,因为我们当然无法推断出该未使用的模板参数。这意味着,除非 Iter 是 Input_iterator(§24.4.4),否则 vector(Iter,Iter) 的声明将失败。
我引入了 Enable_if 作为默认模板参数,因为这是最通用的解决方案。它可以用于没有参数和/或没有返回类型的模板。但是,在这种情况下,我们可以将其应用于构造函数参数类型:
template<typename T>
class vector<T> {
public:
vector(size_t n, const T& val); // 具有值 val的类型 T 的 n 个元素
template<typename Iter>
vector(Enable_if<Input_iterator<Iter>(),Iter>> b, Iter e); // initialize from [b:e)
// ...
};
Enable_if 技术仅适用于模板函数(包括类模板和特化的成员函数)。Enable_if 的实现和使用依赖于函数模板重载规则(§23.5.3.2)中的详细信息。因此,它不能用于控制类、变量或非模板函数的声明。例如:
Enable_if<(version2_2_3<config),M_struct>∗ make_default() // 错:非模板
{
return new Mystruct{};
}
template<typename T>
void f(const T& x)
{
Enable_if<(20<siz eof<T>),T> tmp = x; // 错: tmp 非函数
Enable_if<!(20<siz eof<T>),T&> tmp = ∗new T{x}; // 错: tmp 非函数
// ...
}
对于 tmp,使用 Holder(§28.2)几乎肯定会更干净:如果你设法构造了那个自由存储对象,你将如何delete它?
28.4.2 实现Enable_if (Implementing Enable_if)
Enable_if 的实现几乎很简单:
template<bool B, typename T = void>
struct std::enable_if {
typedef T type;
};
template<typename T>
struct std::enable_if<false , T> {}; // no ::type if B==false
template<bool B, typename T = void>
using Enable_if = typename std::enable_if<B,T>::type;
请注意,我们可以省略类型参数并默认获取 void 。
有关这些简单声明如何成为基本构造的有用的语言技术解释,请参见§23.5.3.2。
28.4.3 Enable_if和概念 (Enable_if and Concepts)
我们可以将 Enable_if 用于各种谓词,包括许多类型属性测试(§28.3.1.1)。概念是我们拥有的最通用和最有用的谓词之一。理想情况下,我们希望基于概念进行重载,但由于缺乏对概念的语言支持,我们能做的最好的事情就是使用 Enable_if 根据约束进行选择。例如:
template<typename T>
Enable_if<Ordered<T>()> fct(T∗,T∗); // 优化的实现
template<typename T>
Enable_if<!Ordered<T>()> fct(T∗,T∗); // 非优化的实现
请注意,Enable_if 默认为 void,因此 fct() 是一个 void 函数。我不确定使用该默认值是否会提高可读性,但我们可以像这样使用 fct():
void f(vector<int>& vi, vector<complex<int>>& vc)
{
if (vi.size()==0 || vc.size()==0) 抛出runtime_error("bad fct arg");
fct(&vi.front(),&vi.back()); // 调用优化实现
fct(&vc.front(),&vc.back()); // 调用非优化实现
}
这些调用按所述方式解析,因为我们可以将 < 用于 int,但不能用于 complex<int>。如果我们不提供类型参数,Enable_if 将解析为 void 。
28.4.4 更多关于Enable_if的例子 (More Enable_if Examples)
使用 Enable_if 时,我们迟早会想问一个类是否有一个具有特定名称和适当类型的成员。对于许多标准操作(例如构造函数和赋值),标准库提供了类型属性谓词,例如 is_copy_assignable 和 is_default_constructible(§35.4.1)。但是,我们可以构建自己的谓词。考虑这个问题“如果 x 属于 X 类型,我们可以调用 f(x) 吗?”定义 has_f 来回答这个问题,提供了一个机会来展示许多模板逾编程库(包括标准库的部分内容)内部使用的一些技术和一些鹰架码(scaffolding/boilerplate code)。首先,定义通常的类加上特化来表示替代方案:
struct substitution_failure { }; // 表示声明失败
template<typename T>
struct substitution_succeeded : std::true_type
{ };
template<>
struct substitution_succeeded<substitution_failure> : std::false_type
{ };
这里,substitution_failure 用于表示替换失败(§23.5.3.2)。除非参数类型是 replacement_failure,否则我们从 std::true_type 派生。显然,std::true_type 和 std::false_type 分别表示 true 和 false 值的类型:
std::true_type::value == true
std::false_type::value == false
我们使用 replacement_succeeded 来定义我们真正想要的类型函数。例如,我们可能正在寻找一个可以调用为 f(x) 的函数 f。为此,我们可以定义 has_f:
template<typename T>
struct has_f
: substitution_succeeded<typename get_f_result<T>::type>
{ };
因此,如果 get_f_result<T> 产生正确的类型(可能是 f 调用的返回类型),则 has_f::value 为 true_type::value,即为真。如果 get_f_result<T> 未通过编译,则返回 replacement_failure,并且 has_f::value 为假。
到目前为止,一切都很好,但如果 f(x) 无法编译为类型 X 的值 x,我们如何让 get_f_result<T> 成为 replacement_failure?实现这一点的定义看起来很无害:
template<typename T>
struct get_f_result {
private:
template<typename X>
static auto check(X const& x) −> decltype(f(x)); // 可以调用 f(x)
static substitution_failure check(...); // 不能调用 f(x)
public:
using type = decltype(check(std::declval<T>()));
};
我们只需声明一个函数 check,以便 check(x) 具有与 f(x) 相同的返回类型。显然,除非我们可以调用 f(x),否则这将无法编译。因此,如果我们不能调用 f(x),则 check 的声明将失败。在这种情况下,由于替换失败不是错误(SFINAE;§23.5.3.2),我们得到了 check() 的第二个定义,其返回类型为 replacement_failure。是的,如果我们的函数 f 被声明为返回 replacement_failure,那么这个精心设计的诡计就会失败。
请注意,decltype() 不会评估其操作数。
我们设法将看似类型错误的内容转换为值 false。如果语言提供了进行这种转换的原始(内置)操作,事情会更简单;例如:
is_valid()); // f(x)会被编译吗?
然而,一种语言不可能提供所有的东西作为语言原语。给定鹰架码,我们只需提供常规语法:
template<typename T>
constexpr bool Has_f()
{
return has_f<T>::value;
}
现在,我们可以写出
template<typename T>
class X {
// ...
Enable_if<Has_f<T>()> use_f(const T&)
{
// ...
f(t);
// ...
}
// ...
};
当且仅当可以为 T 值 t 调用 f(t) 时,X<T> 才具有成员 use_f()。
请注意,我们不能简单地写成:
if (Has_f<decltype(t)>()) f(t);
即使 Has_f<decltype(t)>() 返回 false,调用 f(t) 也会进行类型检查(并失败类型检查)。
鉴于定义 Has_f 所用的技术,我们可以为我们能想到的任何操作或成员 foo 定义 Has_foo。每个 foo 的鹰架码有 14 行代码。这可能会重复,但并不困难。
这意味着 Enable_if<> 允许我们根据参数类型的任何逻辑标准在重载模板中进行选择。例如,我们可以定义 Has_not_equals() 类型函数来检查 != 是否可用,并像这样使用它:
template<typename Iter, typename Val>
Enable_if<Has_not_equals<Iter>(),Iter> find(Iter first, Iter last, Val v)
{
while (first!=last && !(∗first==v))
++first;
return first;
}
template<typename Iter, typename Val>
Enable_if<!Has_not_equals<Iter>(),Iter> find(Iter first, Iter last, Val v)
{
while (!(first==last) && !(∗first==v))
++first;
return first;
}
这种临时重载很容易变得混乱和难以管理。例如,尽可能尝试添加使用 != 进行值比较的版本(即 ∗first!=v,而不是 !(∗first==v))。因此,我建议在有选择的情况下依赖更结构化的标准重载规则(§12.3.1)和 特化规则(§25.3)。例如:
template<typename T>
auto operator!=(const T& a, const T& b) −> decltype(!(a==b))
{
return !(a==b);
}
这些规则确保如果已经为类型 T 定义了特定的 != (作为模板或非模板函数),则不会实例化此定义。我使用 decltype() 部分是为了展示如何从先前定义的运算符派生返回类型,部分是为了处理 != 返回不同于 bool 的罕见情况。
类似地,给定 < ,我们可以有条件地定义 >、<=、>= 等。
28.5 一个编译时列表:Tuple (A Compile-Time List: Tuple)
在这里,我将通过一个简单但实际的示例演示基本的模板逾编程技术。我将定义一个具有相关访问操作和输出操作的 Tuple。像这样定义的 Tuple 已在工业界使用了十多年。更优雅、更通用的 std::tuple 在第 28.6.4 节和第 34.2.4.2 节中介绍。
这个思想是允许这样的代码:
Tuple<double , int, char> x {1.1, 42, 'a'};
cout << x << "\n";
cout << get<1>(x) << "\n";
最终输出结果为:
{ 1.1, 42, 'a'};
42
Tuple 的定义从根本上来说很简单:
template<typename T1=Nil, typename T2=Nil, typename T3=Nil, typename T4=Nil>
struct Tuple : Tuple<T2, T3, T4> { // layout: {T2,T3,T4} before T1
T1 x;
using Base = Tuple<T2, T3, T4>;
Base∗ base() { return static_cast<Base∗>(this); }
const Base∗ base() const { return static_cast<const Base∗>(this); }
Tuple(const T1& t1, const T2& t2, const T3& t3, const T4& t4) :Base{t2,t3,t4}, x{t1} { }
};
因此,由四个元素组成的元组(通常称为 4 元组)是由三个元素组成的元组(3 元组),后面跟着第四个元素。
我们用一个接受四个值(可能为四种不同类型)的构造函数构造一个包含四个元素的 Tuple。它使用最后三个元素(其尾部)初始化其基本 3 元组,使用第一个元素(其头部)初始化其成员 x。
对 Tuple 尾部(即 Tuple 的基类)的操作在 Tuple 的实现中非常重要且很常见。因此,我提供了一个别名 Base 和一对成员函数 base() 来简化对基类/尾部的操作。
显然,此定义仅处理真正具有四个元素的元组。此外,它将大部分工作留给了 3 元组。少于四个元素的元组被定义为特化:
template<>
struct Tuple<> { Tuple() {} }; // 0-tuple
template<typename T1>
struct Tuple<T1> : Tuple<> { // 1-tuple
T1 x;
using Base = Tuple<>;
Base∗ base() { return static_cast<Base∗>(this); }
const Base∗ base() const { return static_cast<const Base∗>(this); }
Tuple(const T1& t1) :Base{}, x{t1} { }
};
template<typename T1, typename T2>
struct Tuple<T1, T2> : Tuple<T2> { // 2-tuple, lay out: T2 before T1
T1 x;
using Base = Tuple<T2>;
Base∗ base() { return static_cast<Base∗>(this); }
const Base∗ base() const { return static_cast<const Base∗>(this); }
Tuple(const T1& t1, const T2& t2) :Base{t2}, x{t1} { }
};
template<typename T1, typename T2, typename T3>
struct Tuple<T1, T2, T3> : Tuple<T2, T3> { // 3-tuple, lay out: {T2,T3} before T1
T1 x;
using Base = Tuple<T2, T3>;
Base∗ base() { return static_cast<Base∗>(this); }
const Base∗ base() const { return static_cast<const Base∗>(this); }
Tuple(const T1& t1, const T2& t2, const T3& t3) :Base{t2, t3}, x{t1} { }
};
这些声明相当重复,并遵循第一个 Tuple( 4 元组) 的简单模式。4 元组 Tuple 的定义是主要模板,并为所有大小(0、1、2、3 和 4)的 Tuple 提供接口。这就是为什么我必须提供那些 Nil 默认模板参数。事实上,它们永远不会被使用。特化将选择更简单的 Tuple 之一,而不是使用 Nil。
我将 Tuple 定义为派生类的“栈”的方式相当传统(例如,std::tuple 按类似方式定义;§28.5)。它具有奇怪的效果,即 Tuple 的第一个元素(给定通常的实现技术)将获得最高地址,而最后一个元素将具有与整个 Tuple 相同的地址。例如:
tuple<double ,string,int,char>{3.14,string{"Bob"},127,'c'}
可以用图形方式表示如下:
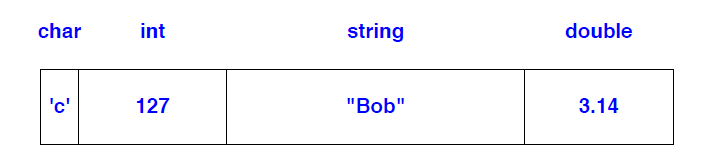
这带来了一些有趣的优化可能性。考虑一下:
class FO { /* 没有数据成员的函数对象 */ };
typedef Tuple<int∗, int∗> T0;
typedef Tuple<int∗,FO> T1;
typedef Tuple<int∗, FO, FO> T2;
在我的实现中,我得到了 sizeof(T0)==8 ,sizeof(T1)==4 和 sizeof(T2)==4,因为编译器优化了空基类。这称为空基优化,由语言保证(§27.4.1)。
28.5.1 一个简单的输出函数 (A Simple Output Function)
Tuple 的定义具有良好的规则递归结构,我们可以使用它来定义显示元素列表的函数。例如:
template<typename T1, typename T2, typename T3, typename T4>
void print_elements(ostream& os, const Tuple<T1,T2,T3,T4>& t)
{
os << t.x << ", "; // t’s x
print_elements(os,∗t.base());
}
template<typename T1, typename T2, typename T3>
void print_elements(ostream& os, const Tuple<T1,T2,T3>& t)
{
os << t.x << ", ";
print_elements(os,∗t.base());
}
template<typename T1, typename T2>
void print_elements(ostream& os, const Tuple<T1,T2>& t)
{
os << t.x << ", ";
print_elements(os,∗t.base());
}
template<typename T1>
void print_elements(ostream& os, const Tuple<T1>& t)
{
os << t.x;
}
template<>
void print_elements(ostream& os, const Tuple<>& t)
{
os << " ";
}
4 元组,3 元组和 2 元组的 print_elements() 的相似性暗示了更好的解决方案(§28.6.4),但现在我仅使用这些 print_elements() 为元组定义一个 << :
template<typename T1, typename T2, typename T3, typename T4>
ostream& operator<<(ostream& os, const Tuple<T1,T2,T3,T4>& t)
{
os << "{ ";
print_elements(os,t);
os << " }";
return os;
}
现在我们可以写成这样:
Tuple<double , int, char> x {1.1, 42, 'a'};
cout << x << "\n";
cout << Tuple<double ,int,int,int>{1.2,3,5,7} << "\n";
cout << Tuple<double ,int,int>{1.2,3,5} << "\n";
cout << Tuple<double ,int>{1.2,3} << "\n";
cout << Tuple<double>{1.2} << "\n";
cout << Tuple<>{} << "\n";
不出所料,输出是:
{ 1.1 42, a }
{ 1.2,3,5,7 }
{ 1.2,3,5 }
{ 1.2,3 }
{ 1.2 }
{ }
28.5.2 元素的访问 (Element Access)
按照定义,元组具有可变数量的元素,这些元素可能类型不同。我们希望高效地访问这些元素,并且避免类型系统冲突(即不使用强制类型转换)。我们可以设想各种方案,例如命名元素、对元素进行编号以及通过递归访问元素直到到达所需元素。最后一种方案是我们将用于实现最常见访问策略的方法:索引元素。特别是,我想实现一种对元组进行下标的方法。遗憾的是,我无法实现适当的运算符[],因此我使用函数模板 get():
Tuple<double , int, char> x {1.1, 42, 'a'};
cout << "{ "
<< get<0>(x) << ", "
<< get<1>(x) << ", "
<< get<2>(x) << " }\n"; // write { 1.1, 42, a }
auto xx = get<0>(x); // xx is a double
这个思想是从 0 开始对元素进行索引,这样元素选择就在编译时完成,并且我们保留所有类型信息。
get() 函数构造一个 getNth<T,int> 类型的对象。getNth<X,N> 的作用是返回对第 N 个元素的引用,该元素的类型假定为 X。有了这样的辅助函数,我们可以定义 get():
template<int N, typename T1, typename T2, typename T3, typename T4>
Select<N, T1, T2, T3, T4>& get(Tuple<T1, T2, T3, T4>& t)
{
return getNth<Select<N, T1, T2, T3, T4>,N>::get(t);
}
getNth 的定义是从 N 到 0 的特化的通常递归的变体:
template<typename Ret, int N>
struct getNth { // getNth() 记住第N个元素的类型(Ret)
template<typename T>
static Ret& get(T& t) // 从t 的基类获得第N个元素
{
return getNth<Ret,N−1>::g et(∗t.base());
}
};
template<typename Ret>
struct getNth<Ret,0> {
template<typename T>
static Ret& get(T& t)
{
return t.x;
}
};
基本上,getNth 是一个特殊用途的 for 循环,通过递归 N-1 次实现。成员函数是静态的,因为我们实际上不需要 getNth 类的任何对象。该类仅用作保存 Ret 和 N 的地方,以便编译器可以使用它们。
这需要相当多的鹰架码来索引 Tuple,但至少生成的代码是类型安全的并且高效。所谓“高效”,是指只要有一个相当好的编译器(这很常见),访问 Tuple 成员就不会产生运行时开销。
为什么我们必须写成 get<2>(x) 而不是 x[2]?我们可以试试:
template<typename T>
constexpr auto operator[](T t,int N)
{
return get<N>(t);
}
遗憾的是,这不起作用:
• operator[]() 必须是成员,但我们可以通过在 Tuple 中定义它来处理这个问题。
• 在 operator[]() 中,参数 N 不是常量表达式。
• 我“忘记”了只有 lambda 可以从其返回语句中推断出其结果类型(§11.4.4),但这可以通过添加 −>decltype(get<N>(t)) 来处理。
为了实现这一点,我们需要一些语言方面的帮助,现在,我们必须使用 get<2>(x)。
28.5.2.1 const Tuples
根据定义,get() 适用于非常量 Tuple 元素,并且可以在赋值语句的左侧使用。例如:
Tuple<double , int, char> x {1.1, 42, 'a'};
get<2>(x) = 'b'; // OK
但是,它不能用于 const:
const Tuple<double , int, char> xx {1.1, 42, 'a'};
get<2>(xx) = 'b'; // error : xx is const
char cc = get<2>(xx); // error : xx is const (surprise?)
问题在于 get() 通过非常量引用获取其参数。但 xx 是 const,因此它不是可接受的参数。
自然地,我们也希望能够拥有 const Tuple。例如:
const Tuple<double , int, char> xx {1.1, 422, 'a'};
char cc = get<2>(xx); // OK: reading from const
cout << "xx: " << xx << "\n";
get<2>(xx) = 'x'; // error : xx is const
为了处理 const Tuple,我们必须添加 get() 和 getNth 的 get() 的 const 版本。例如:
template<typename Ret, int N>
struct getNth { // getNth() remembers the type (Ret) of the Nth element
template<typename T>
static Ret& get(T& t) // get the value element N from t’s Base
{
return getNth<Ret,N−1>::g et(∗t.base());
}
template<typename T>
static const Ret& get(const T& t) // get the value element N from t’s Base
{
return getNth<Ret,N−1>::g et(∗t.base());
}
};
template<typename Ret>
struct getNth<Ret,0> {
template<typename T> static Ret& get(T& t) { return t.x; }
template<typename T> static const Ret& get(const T& t) { return t.x; }
};
template<int N, typename T1, typename T2, typename T3, typename T4>
Select<N, T1, T2, T3, T4>& get(Tuple<T1, T2, T3, T4>& t)
{
return getNth<Select<N, T1, T2, T3, T4>,N>::get(t);
}
template<int N, typename T1, typename T2, typename T3>
const Select<N, T1, T2, T3>& get(const Tuple<T1, T2, T3>& t)
{
return getNth<Select<N, T1, T2, T3>,N>::get(t);
}
现在,我们可以处理 const 和非 const 参数。
28.5.3 make_tuple
类模板无法推导出其模板参数,但函数模板可以从其函数参数推导出这些参数。这意味着我们可以通过让函数为我们构造 Tuple 类型,在代码中隐式地创建 Tuple 类型:
template<typename T1, typename T2, typename T3, typename T4>
Tuple<T1, T2, T3, T4> make_tuple(const T1& t1, const T2& t2, const T3& t3, const T4& t4)
{
return Tuple<T1, T2, T3, T4>{t1, t2, t3,t4};
}
// ... and the other four make_Tuples ...
已知 make_tuple ,我们可以写出:
auto xxx = make_Tuple(1.2,3,'x',1223);
cout << "xxx: " << xxx << "\n";
其他有用的函数(如 head() 和 tail())很容易实现。标准库元组提供了一些这样的实用函数(§28.6.4)。
28.6 可变参数模板(Variadic Templates)
处理未知数量的元素是一个常见问题。例如,错误报告函数可能需要 0 到 10 个参数,矩阵可能有 1 到 10 个维度,元组可能有 0 到 10 个元素。请注意,在第一个和最后一个示例中,元素不一定是同一类型。在大多数情况下,我们不想分别处理每种情况。理想情况下,一段代码应该处理一个元素、两个元素、三个元素等情况。另外,若我从帽子里抽出数字10:理想情况下,元素数量不应该有固定的上限。
多年来,人们已经找到了很多解决方案。例如,可以使用默认参数(§12.2.5))允许单个函数接受可变数量的参数,而函数重载(§12.3)可用于为每个数量的参数提供一个函数。传递单个元素列表(§11.3)可以替代可变数量的参数,只要这些元素都是同一类型。但是,为了优雅地处理未知数量(可能不同)类型的参数的情况,需要一些额外的语言支持。该语言功能称为可变参数模板。
28.6.1 一种类型安全的printf() (A Type-Safe printf())
考虑一个需要未知数量各种类型的参数的函数的典型示例:printf()。正如 C 和 C++ 标准库所提供的那样,printf() 非常灵活,性能也很好(§43.3)。但是,它无法扩展到用户定义的类型,并且不是类型安全的,因此很容易成为黑客的目标。
printf() 的第一个参数是 C 样式字符串,被解释为“格式字符串”。格式字符串需要使用其他参数。格式说明符(例如 %g 表示浮点数)和 %s 表示以零结尾的字符数组)控制其他参数的解释。例如:
printf("The value of %s is %g\n","x",3.14);
string name = "target";
printf("The value of %s is %P\n",name,Point{34,200});
printf("The value of %s is %g\n",7);
printf() 的第一次调用按预期工作,但第二次调用有两个问题:格式规范 %s 指的是 C 样式字符串,并且 printf() 无法正确解释 std::string 参数。此外,没有 %P 格式,并且通常没有直接打印用户定义类型(例如 Point)值的方法。在 printf() 的第三次调用中,我提供了一个 int 作为 %s 的参数,并且“忘记”为 %g 提供了一个参数。通常,编译器无法将格式字符串所需的参数数量和类型与程序员提供的参数数量和类型进行比较。最后一次调用(如果有)的输出不会很漂亮。
使用可变参数模板,我们可以实现 printf() 的可扩展且类型安全的变体。与编译时编程一样,实现分为两部分:
[1] 处理只有一个参数(格式字符串)的情况。
[2] 处理至少有一个“额外”参数的情况,该参数经过适当格式化,需要在格式字符串指示的适当位置输出。
最简单的情况是只有一个参数,即格式字符串:
void printf(const char∗ s)
{
if (s==nullptr) return;
while (∗s) {
if (∗s=='%' && ∗++s!='%') // 确保没有更多的预期参数
// %% represents plain % in a for mat str ing
throw runtime_error("invalid format: missing arguments");
std::cout << ∗s++;
}
}
这将打印出格式字符串。如果找到格式说明符,则此 printf() 将抛出异常,因为没有要格式化的参数。格式说明符定义为 % 后面没有另一个 %(%% 是 printf() 对不以类型说明符开头的 % 的表示法)。请注意,即使 % 是字符串中的最后一个字符,∗++s 也不会溢出。在这种情况下,∗++s 指的是终止零。
完成后,我们必须使用更多参数来处理 printf()。这时模板(特别是可变参数模板)就会发挥作用:
template<typename T, typename ... Args> // 可变模板参数列表: 一个或多个参数
void printf(const char∗ s, T value , Args... args) // 函数参数列表: 两个或多个参数
{
while (s && ∗s) {
if (∗s=='%' && ∗++s!='%') { // 格式指定符 (忽略它是哪一个)
std::cout << value; // 使用第一个非格式化参数
return printf(++s, args...); // 用参数列表尾进行递归调用
}
std::cout << ∗s++;
}
throw std::runtime_error("extra arguments provided to printf");
}
此 printf() 查找并打印第一个非格式参数,“剥离”该参数,然后递归调用自身。当没有其他非格式参数时,它会调用第一个(更简单的)printf()。普通字符(即非 % 形式说明符)仅被打印。
<< 的重载取代了格式说明符中(可能错误的)“提示”的使用。如果参数具有 << 定义的类型,则打印该参数;否则,该调用不会进行类型检查,程序将永远不会运行。% 后的格式化字符未使用。我可以想象这些字符的类型安全用途,但本例的目的不是设计完美的 printf(),而是解释可变参数模板。
Args... 定义了所谓的参数包。参数包是一系列(类型/值)对,你可以从中“剥离”参数,从第一个开始。当使用两个或更多参数调用 printf() 时,选择
void printf(const char∗ s, T value , Args... args);
第一个参数为 s,第二个参数为值,其余参数(如果有)捆绑到参数包 args 中以供以后使用。在调用 printf(++s,args...) 时,参数包 args 被扩展,因此 args 的第一个元素被选为值,并且 args 比上一个调用中短一个元素。此过程一直持续到 args 为空,因此我们调用:
void printf(const char∗);
如果我们确实想这样做,我们可以检查 printf() 格式指令,例如 %s。例如:
template<typename T, typename ... Args> // 可变模板参数列表: 一个或多个参数
void printf(const char∗ s, T value , Args... args) // 函数参数列表:两个或多个参数
{
while (s && ∗s) {
if (∗s=='%') { // 一个格式指定符或 %%
switch (∗++s) {
case '%': // 无格式指定符
break;
case 's':
if (!Is_C_style_string<T>() && !Is_string<T>())
throw runtime_error("Bad printf() format");
break;
case 'd':
if (!Is_integral<T>()) throw runtime_error("Bad printf() format");
break;
case 'g':
if (!Is_floating_point<T>()) throw runtime_error("Bad printf() format");
break;
}
std::cout << value; // 使用第一个非格式指定参数
return printf(++s, args...); // 用参数列表尾进行递归调用
}
std::cout << ∗s++;
}
throw std::runtime_error("extra arguments provided to printf");
}
标准库提供了 std::is_integral 和 std::is_floating_point,但您必须自己制作 Is_C_style_string。
28.6.2 技术细节(Technical Details)
如果你熟悉函数式编程,您应该会发现 printf() 示例(§28.6)是一种非常标准技术的不寻常符号。如果不熟悉,以下是一些可能有帮助的最小技术示例。首先,我们可以声明并使用一个简单的可变参数模板函数:
template<typename... Types>
void f(Types... args); // 可变参数模板函数
也就是说,f() 是一个可以使用任意数量和任意类型的参数来调用的函数:
f(); //OK: args 不含参数
f(1); //OK: args 含一参数: int
f(2, 1.0); // OK: args 含两参数: int 和double
f(2, 1.0, "Hello"); // OK: args 含三参数: int, double, 和 const char*
可变参数模板用 ... 符号定义:
template<typename... Types>
void f(Types... args); // 可变参数的模板函数
Types 声明中的 typename... 指定 Types 是一个模板参数包。args 类型中的 ... 指定 args 是一个函数参数包。每个 args 函数参数的类型都是相应的 Types 模板参数。我们可以使用与 typename.... 含义相同的 class...。省略号 (...) 是一个单独的词汇标记,因此您可以在其前面或后面放置空格。省略号可以出现在语法中的许多不同位置,但它始终表示“零次或多次出现某事物”)。将参数包视为编译器记住了其类型的值序列。例如,我们可以以图形方式表示 {'c',127,string{"Bob"},3.14} 的参数包:

这通常称为一个元组(tuple)。C++ 标准未指定内存布局。例如,它可能与此处显示的相反(最后一个元素位于最低内存地址;§28.5)。但是,它是一种密集的表示,而不是链接的表示。要获得一个值,我们需要从头开始,然后逐步找到我们想要的值。元组的实现演示了该技术(§28.5)。我们可以找到第一个元素的类型并使用该类型访问它,然后我们可以(递归地)继续下一个参数。如果我们愿意,我们可以使用类似 get<N> 的方法来为元组(以及 std::tuple;§28.6.4)提供索引访问的外观,但遗憾的是,没有直接的语言支持。
如果你有一个参数包,您可以通过在其后放置 ... 将其扩展为其元素序列。例如:
template<typename T, typename ... Args>
void printf(const char∗ s, T value , Args... args)
{
// ...
return printf(++s, args...); // 以 args 的元素作为参数进行递归调用
// ...
}
将参数包扩展为其元素并不局限于函数调用。例如:
template<typename... Bases>
class X : public Bases... {
public:
X(const Bases&... b) : Bases(b)... { }
};
X<> x0;
X<Bx> x1(1);
X<Bx,By> x2(2,3);
X<Bx,By,Bz> x3(2,3,4);
这里,Bases... 表示 X 有零个或多个基类。在初始化 X 时,构造函数需要 Bases 可变模板参数中指定的零个或多个类型的值。这些值将一个接一个地传递给相应的基类初始化器。
在大多数需要元素列表的地方(§iso.14.5.3),我们可以使用省略号来表示“某事物的零个或多个元素”,例如:
• 模板参数列表
• 函数参数列表
• 初始化列表
• 基类说明符列表
• 基类或成员初始化列表
• 一个 sizeof... 表达式
sizeof... 表达式用于获取参数包中元素的数量。例如,我们可以为给定一个tuple元素数为 2 的pair定义一个tuple的构造函数:
template<typename... Types>
class tuple {
// ...
template<typename T, typename U, typename = Enable_if<sizeof...(Types)==2>
tuple(const pair<T,U>>&);
};
28.6.3 转发(Forwarding)
可变参数模板的主要用途之一是从一个函数转发到另一个函数。考虑如何编写一个函数,该函数以要调用的某个函数作为参数,并以可能为空的参数列表作为参数传递给“某个函数”:
template<typename F, typename ... T>
void call(F&& f, T&&... t)
{
f(forward<T>(t)...);
}
这很简单,并不是一个假设的例子。标准库线程有使用此技术的构造函数(§5.3.1,§42.2.2)。我使用推导模板参数类型的传递右值引用来正确区分右值和左值(§23.5.2.1),并使用 std::forward() 来利用这一点(§35.5.1)。T&&... 中的 ... 读作“接受零个或多个 && 参数,每个参数的类型与相应的 T 相同。”forward<T>(t)... 中的 ... 读作“转发来自 t 的零个或多个参数。”
我使用了一个模板参数来表示要调用的“某物”的类型,这样 call() 就可以接受函数、指向函数的指针、函数对象和 lambda 表达式。
我们可以测试call():
void g0()
{
cout << "g0()\n";
}
template<typename T>
void g1(const T& t)
{
cout << "g1(): " << t << '\n';
}
void g1d(double t)
{
cout << "g1d(): " << t << '\n';
}
template<typename T, typename T2>
void g2(const T& t, T2&& t2)
{
cout << "g2(): " << t << ' ' << t2 << '\n';
}
void test()
{
call(g0);
call(g1); //错: 参数太少
call(g1<int>,1);
call(g1<const char∗>,"hello");
call(g1<double>,1.2);
call(g1d,1.2);
call(g1d,"No way!"); // 错: 对 g1d() 错误参数
call(g1d,1.2,"I can't count"); // 错: 对 g1d() 的参数太多
call(g2<double ,string>,1,"world!");
int i = 99; //用左值测试
const char∗ p = "Tr ying";
call(g2<double ,string>,i,p);
call([](){ cout <<"l1()\n"; });
call([](int i){ cout <<"l0(): " << i << "\n";},17);
call([i](){ cout <<"l1(): " << i << "\n"; });
}
我必须具体说明要传递模板函数的哪个特化,因为 call() 无法根据其他参数的类型推断出要使用哪一个。
28.6.4 标准库的tuple
§28.5 中的简单 Tuple 有一个明显的弱点:它最多只能处理四个元素。本节介绍标准库 Tuple 的定义(来自 <tuple>;§34.2.4.2)并解释用于实现它的技术。std::tuple 和我们的简单 Tuple 之间的主要区别在于,前者使用可变参数模板来消除元素数量的限制。以下是关键定义:
template<typename Head, typename... Tail>
class tuple<Head, Tail...>
: private tuple<Tail...> { // here is the recursion
/*
Basically, a tuple stores its head (first (type,value) pairs)
and derives from the tuple of its tail (the rest of the (type/value) pairs).
Note that the type is encoded in the type, not stored as data
*/
typedef tuple<Tail...> inherited;
public:
constexpr tuple() { } // default: the empty tuple
// Construct tuple from separate arguments:
tuple(Add_const_reference<Head> v, Add_const_reference<Tail>... vtail)
: m_head(v), inherited(vtail...) { }
// Construct tuple from another tuple:
template<typename... VValues>
tuple(const tuple<VValues...>& other)
: m_head(other.head()), inherited(other.tail()) { }
template<typename... VValues>
tuple& operator=(const tuple<VValues...>& other) // assignment
{
m_head = other.head();
tail() = other.tail();
return ∗this;
}
// ...
protected:
Head m_head;
private:
Add_reference<Head> head() { return m_head; }
Add_const_reference<const Head> head() const { return m_head; }
inherited& tail() { return ∗this; }
const inherited& tail() const { return ∗this; }
};
无法保证 std::tuple 的实现与此处暗示的一致。事实上,一些流行的实现派生自辅助类(也是一个可变参数类模板),以便使内存中的元素布局与具有相同成员类型的struct相同。
如果某个类型尚未被引用,则“添加引用”类型函数会为其添加引用。它们用于避免复制(§35.4.1)。
奇怪的是,std::tuple 不提供 head() 和 tail() 函数,所以我将它们设为私有。事实上,tuple 不提供任何用于访问元素的成员函数。如果你想访问一个元组的元素,你必须(直接或间接地)调用一个函数,将其拆分为一个值并……如果我想要标准库元组的 head() 和 tail(),我可以这样写成:
template<typename Head, typename... Tail>
Head head(tuple<Head,Tail...>& t)
{
return std::get<0>(t); // get first element of t (§34.2.4.2)
}
template<typename Head, typename... Tail>
tuple<T&...> tail(tuple<Head, Tail...>& t)
{
return /* details */;
}
tail() 定义的“细节”很丑陋和复杂。如果 tuple 的设计者希望我们在 tuple 上使用 tail(),他们就会将其作为成员提供。
给定tuple,我们可以创建元组并复制和操作它们:
tuple<string,vector,double> tt("hello",{1,2,3,4},1.2);
string h = head(tt.head); // "hello"
tuple<vector<int>,double> t2 = tail(tt.tail); // {{1,2,3,4},1.2};
列出所有这些类型可能会很乏味。相反,我们可以从参数类型中推导出它们,例如,使用标准库 make_tuple():
template<typename... Types>
tuple<Types...> make_tuple(Types&&... t) // 简化(§iso.20.4.2.4)
{
return tuple<Types...>(t...);
}
string s = "Hello";
vector<int> v = {1,22,3,4,5};
auto x = make_tuple(s,v,1.2);
标准库元组的成员比上面实现中列出的成员多得多(因此有 // ...)。此外,标准还提供了几个辅助函数。例如,get() 用于元素访问(如 §28.5.2 中的 get()),因此我们可以这样写:
auto t = make_tuple("Hello tuple", 43, 3.15);
double d = get<2>(t); // d becomes 3.15
因此 std::get() 提供了 std::tuple 的编译时从零开始的下标。
std::tuple 的每个成员对某些人有用,而且大多数成员对许多人都有用,但没有一个能增加我们对可变参数模板的理解,所以我不详细介绍。有来自同一类型(复制和移动)、来自其他元组类型(复制和移动)和来自对(复制和移动)的构造函数和赋值。采用 std::pair 参数的操作使用 sizeof... (§28.6.2) 来确保其目标tuple恰好有两个元素。有(九)个采用分配器(§34.4)和 swap()(§35.5.2)的构造函数和赋值。
遗憾的是,标准库不提供tuple的 << 或 >>。更糟糕的是,为 std::tuple 编写 << 非常复杂,因为没有简单且通用的方法来遍历标准库tuple的元素。首先我们需要一个助手;它是一个具有两个 print() 函数的结构。一个 print() 递归遍历列表打印元素,另一个在不再有元素可打印时停止递归:
template<size_t N> // 打印元素 N 及其后续元素
struct print_tuple {
template<typename... T>
typename enable_if<(N<siz eof...(T))>::type
print(ostream& os, const tuple<T...>& t) const // 非空 tuple
{
os << ", " << get<N>(t); // 打印一个元素
print_tuple<N+1>()(os,t); // 打印剩下的元素
}
template<typename... T>
typename enable_if<!(N<siz eof...(T))>::type // 空 tuple
print(ostream&, const tuple<T...>&) const
{
}
};
该模式是具有终止重载的递归函数(如§28.6.1 中的 printf())。但是,请注意它是如何浪费地让 get<N>() 从 0 计数到 N 的。
我们现在可以为元组编写一个 << :
std::ostream& operator << (ostream& os, const tuple<>&) // 空tuple
{
return os << "{}";
}
template<typename T0, typename ...T>
ostream& operator<<(ostream& os, const tuple<T0, T...>& t) // 非空tuple
{
os << '{' << std::get<0>(t); // 打印第一个元素
print_tuple<1>::print(os,t); // 打印剩下的元素
return os << '}';
}
现在我们可以打印 tuple :
void user()
{
cout << make_tuple() << '\n';
cout << make_tuple("One meatball!") << '\n';
cout << make_tuple(1,1.2,"Tail!") << '\n';
}
28.7 国际标准(SI)单位示例(SI Units Example)
使用 constexpr 和模板,我们可以在编译时计算几乎任何东西。为此类计算提供输入可能很棘手,但我们始终可以将数据 #include 到程序文本中。但是,我更喜欢更简单的示例,在我看来,这些示例在维护方面更有优势。在这里,我将展示一个示例,该示例在实现复杂性和实用性之间提供了合理的权衡。编译开销很小,并且没有运行时开销。该示例旨在提供一个小型库,用于使用米、千克和秒等单位进行计算。这些 MKS 单位是科学界普遍使用的国际标准(International Standard) (SI) 单位的子集。选择该示例是为了展示如何将最简单的逾编程技术与其他语言功能和技术结合使用。
我们希望将单位附加到值上,以避免无意义的计算。例如:
auto distance = 10_m; // 10 meters
auto time = 20_s; // 20 seconds
auto speed = distance/time; // .5 m/s (米每秒)
if (speed == 20) // error : 20 是无量纲的
// ...
if (speed == distance) // 错: 无法比较 m 与 m/s
// ...
if (speed == 10_m/20_s) // OK: 单位匹配
// ...
Quantity<MpS2> acceleration = distance/square(time); // MpS2 指 m/(s*s)
cout << "speed==" << speed << " acceleration==" << acceleration << "\n";
单位为物理值提供了类型系统。如图所示,我们可以在需要时使用 auto 来隐藏类型(§2.2.2),使用用户定义的文字量来引入类型值(§19.2.6),在需要明确Unit时使用类型 Quantity。Quantity 是带有Unit的数值。
28.7.1 (单位)Unit
首先,我将定义Unit:
template<int M, int K, int S>
struct Unit {
enum { m=M, kg=K, s=S };
};
一个Unit 包含代表我们感兴趣的度量的三个单位:
• 米表示长度
• 千克表示质量(mass)
• 秒表示时间
请注意,单位值已编码在类型中。Unit供编译时使用。
我们可以为最常见的单位提供更通用的符号:
using M = Unit<1,0,0>; // meters(米)
using Kg = Unit<0,1,0>; // kilograms(千克)
using S = Unit<0,0,1>; // seconds(秒)
using MpS = Unit<1,0,−1>; // meters per second (m/s)(米/秒)
using MpS2 = Unit<1,0,−2>; // meters per square second (m/(s*s)) (米/秒的平方)
负单位值表示除以具有该单位的数量。这种单位的三值表示非常灵活。我们可以表示涉及距离、质量和时间的任何计算的适当单位。我怀疑 Quantity<123,−15,1024> 会有什么用处,即乘以 123 个距离,除以 15 个质量再相乘,然后再乘以 1024 个时间测量值再相乘(?)——但很高兴知道这个系统是通用的。Unit<0,0,0> 表示无量纲实体,即没有单位的值。
当我们将两个量相乘时,它们的单位会相加。因此,Unit相加很有用:
template<typename U1, typename U2>
struct Uplus {
using type = Unit<U1::m+U2::m, U1::kg+U2::kg, U1::s+U2::s>;
};
template<typename U1, U2>
using Unit_plus = typename Uplus<U1,U2>::type;
类似地,当我们除两个量时,它们的单位也会被减去:
template<typename U1, typename U2>
struct Uminus {
using type = Unit<U1::m−U2::m, U1::kg−U2::kg, U1::s−U2::s>;
};
template<typename U1, U2>
using Unit_minus = typename Uminus<U1,U2>::type;
Unit_plus 和 Unit_minus 是 Unit 上的简单类型函数(§28.2)。
28.7.2 (数量) Quantity
Quantity 是与 Unit 相关的值:
template<typename U>
struct Quantity {
double val;
explicit Quantity(double d) : val{d} {}
};
进一步的改进是将用于表示值的类型设为模板参数,可能默认为 double。我们可以使用多种单位来定义 Quantity :
Quantity<M> x {10.5}; // x 是 10.5 米
Quantity<S> y {2}; // y 是 2 秒
我使 Quantity 构造函数显式化,以使其不太可能从无量纲实体(例如普通的 C++ 浮点文字量)获取隐式转换:
Quantity<MpS> s = 7; // 错: 试图将一个整数转换为米/秒
Quantity<M> comp(Quantity<M>);
// ...
Quantity<M> n = comp(7); // 错: comp() 要求一个距离
现在我们可以开始思考计算了。我们对物理测量做了什么?我不会复习整本物理教科书,但我们肯定需要加法、减法、乘法和除法。你只能用相同的单位加减值:
template<typename U>
Quantity<U> operator+(Quantity<U> x, Quantity<U> y) // 相同维度
{
return Quantity<U>{x.val+y.val};
}
template<typename U>
Quantity<U> operator−(Quantity<U> x, Quantity<U> y) // 相同维度
{
return Quantity<U>{x.val−y.val};
}
Quantity 的构造函数是 explicit,所以我们必须将得到的 double 值转换回 Quantity。
乘法 Quantity 需要加上其 Unit。同样,除 Quantity 需要减去其 Unit。例如:
template<typename U1, typename U2>
Quantity<Unit_plus<U1,U2>> operator∗(Quantity<U1> x, Quantity<U2> y)
{
return Quantity<Unit_plus<U1,U2>>{x.val∗y.val};
}
template<typename U1, typename U2>
Quantity<Unit_minus<U1,U2>> operator/(Quantity<U1> x, Quantity<U2> y)
{
return Quantity<Unit_minus<U1,U2>>{x.val/y.val};
}
有了这些算术运算,我们就可以表达大多数计算。然而,我们发现现实世界的计算包含相当多的缩放运算,即无量纲值的乘法和除法。我们可以使用 Quantity<Unit<0,0,0>>,但这很繁琐:
Quantity<MpS> speed {10};
auto double_speed = Quantity<Unit<0,0,0>>{2}∗speed;
为了消除这种冗长,我们可以提供从 double 到 Quantity<Unit<0,0,0>> 的隐式转换,或者在算术运算中添加几个变体。我选择了后者:
template<typename U>
Quantity<U> operator∗(Quantity<U> x, double y)
{
return Quantity<U>{x.val∗y};
}
template<typename U>
Quantity<U> operator∗(double x, Quantity<U> y)
{
return Quantity<U>{x∗y.val};
}
我们可以写成:
Quantity<MpS> speed {10};
auto double_speed = 2∗speed;
我没有定义从 double 到 Quantity<Unit<0,0,0>> 的隐式转换的主要原因是,我们不希望进行加法或减法的转换:
Quantity<MpS> speed {10};
auto increased_speed = 2.3+speed; // 错: 不能加无量纲的标量到速度上
最好能有根据应用领域精确规定代码的详细要求。
28.7.3 Unit 文字量(Unit Literals)
由于大多数常用单位都有类型别名,我们现在可以这样写:
auto distance = Quantity<M>{10}; // 10 meters
auto time = Quantity<S>{20}; // 20 seconds
auto speed = distance/time; // .5 m/s (meters per second)
这还不错,但与传统上简单地将单位留在程序员头脑中的代码相比,它仍然很冗长:
auto distance = 10.0; // 10 meters
double time = 20; // 20 seconds
auto speed = distance/time; // .5 m/s (meters per second)
我们需要 .0 或显式双精度来确保类型是双精度(并获得除法的正确结果)。
为这两个示例生成的代码应该相同,而且我们可以在符号上做得更好。我们可以为 Quantity 类型引入用户定义文字量(UDL;§19.2.6):
constexpr Quantity<M> operator"" _m(double d) { return Quantity<M>{d}; }
constexpr Quantity<Kg> operator"" _kg(double d) { return Quantity<Kg>{d}; }
constexpr Quantity<S> operator"" _s(double d) { return Quantity<S>{d}; }
这给了我们原始例子中的文字量:
auto distance = 10_m; // 10 meters
auto time = 20_s; // 20 seconds
auto speed = distance/time; // .5 m/s (米每秒)
if (speed == 20) // error : 20 无量纲
// ...
if (speed == distance) // 错: 不能对比 m 与 m/s
// ...
if (speed == 10_m/20_s) // OK: 单位匹配
我为数量和无量纲值的组合定义了 ∗ 和 /,因此我们可以使用乘法或除法缩放单位。但是,我们也可以提供更多常规单位作为用户定义的文字量:
constexpr Quantity<M> operator"" _km(double d) { return 1000∗d; }
constexpr Quantity<Kg> operator"" _g(double d) { return d/1000; }
constexpr Quantity<Kg> operator"" _mg(double d) { return d/10000000; } // milligram
constexpr Quantity<S> operator"" _ms(double d) { return d/1000; } // milliseconds
constexpr Quantity<S> operator"" _us(double d) { return d/1000; } // microseconds
constexpr Quantity<S> operator"" _ns(double d) { return d/1000000000; } // nanoseconds
// ...
显然,过度使用非标准后缀可能会造成失控(例如,us 是可疑的,尽管它被广泛使用,因为 u 看起来有点像希腊字母 μ)。
我本可以将各种量纲(magnitudes)作为更多类型提供(如 std::ratio; §35.3 中所做的那样),但我认为保持 Unit 类型简单并专注于做好它们的主要任务更为简单。
我在我的单位 _s 和 _m 中使用下划线,以免妨碍标准库提供更短、更好的 s 和 m 后缀。
28.7.4 工具函数(Utility Functions)
为了完成这项工作(如初始示例所定义),我们需要工具函数 square()、相等运算符和输出运算符。定义 square() 很简单:
template<typename U>
Quantity<Unit_plus<U,U>> square(Quantity<U> x)
{
return Quantity<Unit_plus<U,U>>(x.val∗x.val);
}
这基本上展示了如何编写任意计算函数。我可以在返回值定义中直接构造 Unit,但使用现有的类型函数更简单。或者,我们可以轻松地定义一个类型函数 Unit_double。
== 看起来或多或少与所有 == 类似。它仅针对相同单位的值进行定义:
template<typename U>
bool operator==(Quantity<U> x, Quantity<U> y)
{
return x.val==y.val;
}
template<typename U>
bool operator!=(Quantity<U> x, Quantity<U> y)
{
return x.val!=y.val;
}
请注意,我通过值传递 Quantity。在运行时,它们表示为 double。
输出函数只进行常规的字符操作:
string suffix(int u, const char∗ x) // 辅助函数
{
string suf;
if (u) {
suf += x;
if (1<u) suf += '0'+u;
if (u<0) {
suf += '−';
suf += '0'−u;
}
}
return suf;
}
template<typename U>
ostream& operator<<(ostream& os, Quantity<U> v)
{
return os << v.val << suffix(U::m,"m") << suffix(U::kg,"kg") << suffix(U::s,"s");
}
最后,我们写出:
auto distance = 10_m; // 10 meters
auto time = 20_s; // 20 seconds
auto speed = distance/time; // .5 m/s (meters per second)
if (speed == 20) // error : 20 is dimensionless
// ...
if (speed == distance) // error : can’t compare m to m/s
// ...
if (speed == 10_m/20_s) // OK: the units match
// ...
Quantity<MpS2> acceleration = distance/square(time); // MpS2 means m/(s*s)
cout << "speed==" << speed << " acceleration==" << acceleration << "\n";
如果有合理的编译器,这样的代码将生成与直接使用 double 生成的代码完全相同的代码。但是,它会根据物理单位的规则进行“类型检查”(在编译时)。这是一个示例,说明我们如何向 C++ 程序添加一整套具有自己的检查规则的特定于应用程序的类型。
28.8 建议(Advice)
[1] 使用元编程提高类型安全性;§28.1。
[2] 使用元编程通过将计算移至编译时来提高性能;§28.1。
[3] 避免使用元编程,以免严重减慢编译速度;§28.1。
[4] 从编译时评估和类型函数的角度思考;§28.2。
[5] 使用模板别名作为返回类型的类型函数的接口;§28.2.1。
[6] 使用 constexpr 函数作为返回(非类型)值的类型函数的接口;§28.2.2。
[7] 使用特征以非侵入方式将属性与类型关联;§28.2.4。
[8] 使用 Conditional 在两种类型之间进行选择;§28.3.1.1。
[9] 使用 Select 在几种备选类型中进行选择;§28.3.1.3。
[10] 使用递归来表达编译时迭代;§28.3.2。
[11] 使用元编程来完成运行时无法很好地完成的任务;§28.3.3。
[12] 使用 Enable_if 有选择地声明函数模板;§28.4。
[13] 概念是与 Enable_if 一起使用的最有用的谓词之一;§28.4.3。
[14] 当您需要一个接受可变数量的各种类型的参数的函数时,请使用可变参数模板;§28.6。
[15] 不要将可变参数模板用于同类参数列表(最好使用初始化列表);§28.6。
[16] 在需要转发的地方使用可变参数模板和 std::move();§28.6.3。
[17] 使用简单的元编程实现高效、优雅的单位系统(用于细粒度类型检查;§28.7。
[18] 使用用户定义的文字量来简化单位的使用;§28.7。
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup

















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









