







| 记号对象 | 对应表达式 |
| TokenValue | 3 |
| TokenMultiply | * |
| TokenValue | 7 |
| TokenPlus | + |
| TokenValue | 56 |
| TokenDivide | / |
| TokenValue | 8 |
| TokenMinus | - |
| TokenValue | 2 |
| TokenMultiply | * |
| TokenValue | 5 |
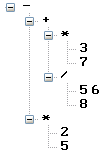
根据实际的算术规则,运算符优先级高的要先计算,然后由低优先级的运算符去调用它的运算结果。表现在树视图上就是高优先级的节点是低优先级节点的下级,即优先级越高,其位置越靠近树叶。因为这里采用统一的对象,把所有元素都用TokenRecord表示,所以TokenValue也是有优先级的。而通过对树视图的分析,所有的TokenValue都是处在叶子的位置,则TokenValue的优先级最高。
分析到这里就要用代码实现了。这里需要用到TokenRecord中的优先级Priority属性,还要用到堆栈。和词法分析一样,也是需要用循环依次分析各个TokenRecord。拿上面的TokenRecord列表进行分析,粗体字代表当前分析的TokenRecord。分析的过程中有一个原则叫“高出低入原则”,需要解释一下。
“高出低入原则”是指:
1.栈顶TokenRecord的优先级高于当前TokenRecord的优先级,则将栈顶TokenRecord弹栈(高出)到临时变量。
1.1如果堆栈为空,将临时变量中的TokenRecord加入当前TokenRecord的ChildList中,然后将当前TokenRecord压栈(低入)。
1.2如果堆栈不为空,找出栈顶TokenRecord和当前TokenRecord中优先级高的一个(相同则按栈顶高算),将临时变量中的TokenRecord加入高优先级TokenRecord的ChildList中。再用高出低入原则处理栈顶和当前TokenRecord。
2.栈顶TokenRecord的优先级低于当前TokenRecord的优先级,则将当前TokenRecord直接压栈。
可能文字表述的并不清晰,其中涉及到循环和递归的操作,具体的过程通过下面的例子来讲解。
1.列表分析状态:
| TokenValue(3) |
TokenMultiplay |
TokenValue(7) |
…... |
堆栈分析:当前堆栈为空,将当前分析的TokenRecord压栈。
| TokenValue(3) |
| 栈底 |
堆栈对应树视图:
2.列表分析状态:
| TokenValue(3) |
TokenMultiply |
TokenValue(7) |
…... |
堆栈分析:栈顶为TokenValue,当前TokenRecord为TokenMultiply,TokenValue优先级最高。遵循高出低入原则,将TokenValue弹栈并添加到TokenMultiply的ChildList中,然后将TokenMultiplay压栈。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1448
1448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









