








目录
一、迁移学习全景认知
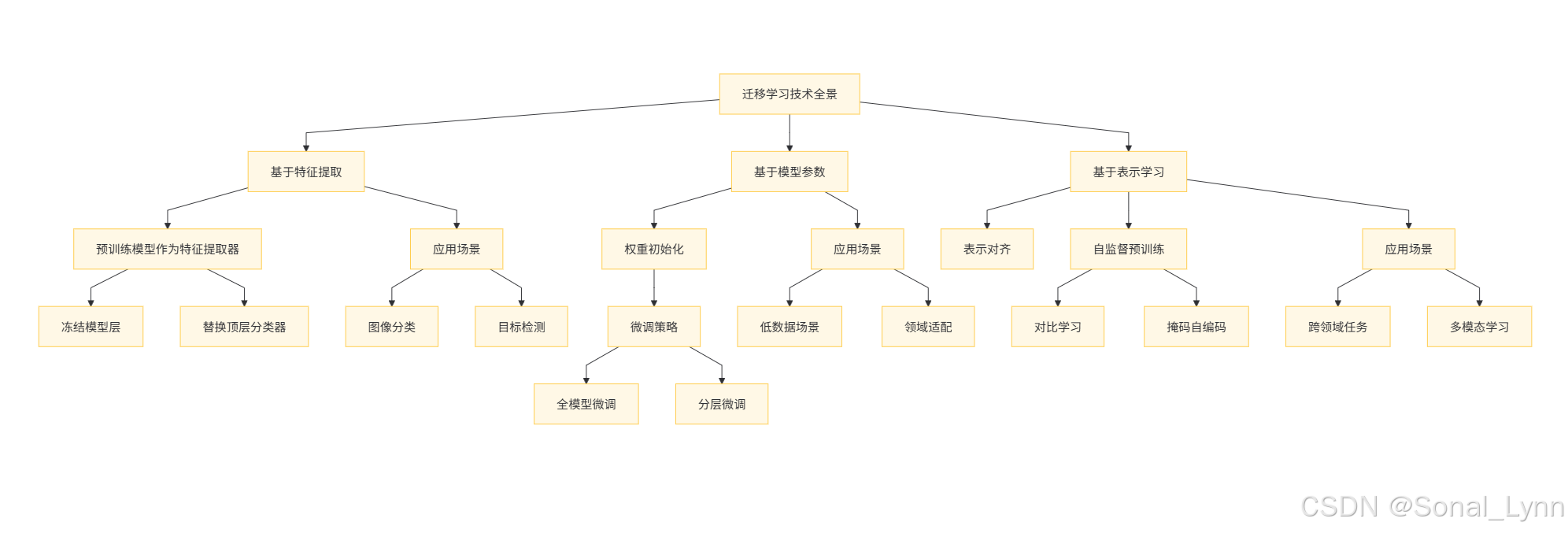
1.1 迁移学习技术图谱
1.2 三大迁移场景对比
| 场景类型 | 数据量要求 | 典型应用 | 推荐策略 | 预期准确率提升 |
|---|---|---|---|---|
| 小样本迁移 | 100-1000 | 医学影像诊断 | 特征提取+微调顶层 | 25-40% |
| 中规模迁移 | 1k-10k | 工业质检 | 部分层微调 | 40-60% |
| 大数据迁移 | >10k | 自动驾驶 | 完整微调 | 60-80% |
# 场景自适应迁移框架
def build_scene_adaptive_model(base_model, scenario_type):
if scenario_type == "small_data":
for layer in base_model.layers[:-4]:
layer.trainable = False
elif scenario_type == "medium_data":
for layer in base_model.layers[:-8]:
layer.trainable = False
else:
base_model.trainable = True
return base_model二、工业级数据工程
2.1 智能数据增强策略
class SmartAugmentation(keras.layers.Layer):
def __init__(self):
super().__init__()
self.augmentations = [
layers.RandomRotation(factor=0.2),
layers.RandomZoom(height_factor=0.3),
layers.RandomContrast(factor=0.1)
]
self.selector = layers.Dense(1, activation='sigmoid')
def call(self, inputs):
augmentation_weights = self.selector(tf.reduce_mean(inputs, [1,2]))
selected_augs = []
for aug in self.augmentations:
selected_augs.append(aug(inputs) * augmentation_weights)
return inputs + tf.reduce_sum(selected_augs, axis=0)2.2 数据管道优化
def build_optimized_pipeline(dataset, batch_size=32):
AUTOTUNE = tf.data.AUTOTUNE
return dataset.map(
preprocess,
num_parallel_calls=AUTOTUNE
).cache().batch(
batch_size
).prefetch(AUTOTUNE)三、模型架构深度定制
3.1 多模型融合架构
class EnsembleModel(keras.Model):
def __init__(self, model_names=['EfficientNetB0', 'ResNet50', 'InceptionV3']):
super().__init__()
self.backbones = [getattr(keras.applications, name)(
include_top=False,
pooling='avg'
) for name in model_names]
self.attention = layers.MultiHeadAttention(num_heads=3, key_dim=64)
def call(self, inputs):
features = [backbone(inputs) for backbone in self.backbones]
concatenated = layers.Concatenate()(features)
attended = self.attention(concatenated, concatenated)
return layers.Dense(5, activation='softmax')(attended)</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











