








目录
一、为什么需要轻量化模型部署?
1.1 移动端AI应用面临的挑战
在移动端设备上部署AI模型时,开发者常遇到三大难题:
-
模型体积膨胀:ResNet-152模型原始大小超过200MB,用户下载耗时且占用存储
-
计算资源限制:手机CPU算力仅为服务器的1/100,复杂模型导致发热卡顿
-
能耗管理困境:图像分类任务可使手机电池续航缩短40%
1.2 轻量化模型的核心价值
通过优化后的模型可实现:
-
下载时间缩短:从200MB压缩到5MB,4G网络下载时间从30秒降至1秒
-
推理速度提升:ImageNet分类任务从2秒/次优化到50ms/次
-
能耗降低:持续推理场景下电池续航提升300%
二、TFLite核心技术解析
2.1 模型转换流程
# 典型转换代码示例
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
# 量化配置进阶示例
def representative_dataset():
for _ in range(100):
yield [np.random.rand(1, 224, 224, 3).astype(np.float32)]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]2.2 FlatBuffers优化原理
技术优势对比表:
| 特性 | Protocol Buffers | FlatBuffers |
|---|---|---|
| 反序列化时间 | 100ms | 0ms |
| 内存占用 | 2x原始数据 | 1x原始数据 |
| 随机访问支持 | 否 | 是 |
| 修改数据便利性 | 高 | 低 |
2.3 算子融合优化案例
原始计算图:
Conv2D -> BatchNorm -> ReLU
优化后计算图:
Fused_Conv2D_BatchNorm_ReLU
典型性能提升:
-
计算耗时减少40%
-
内存占用降低35%
三、模型量化深度解析
3.1 量化类型对比
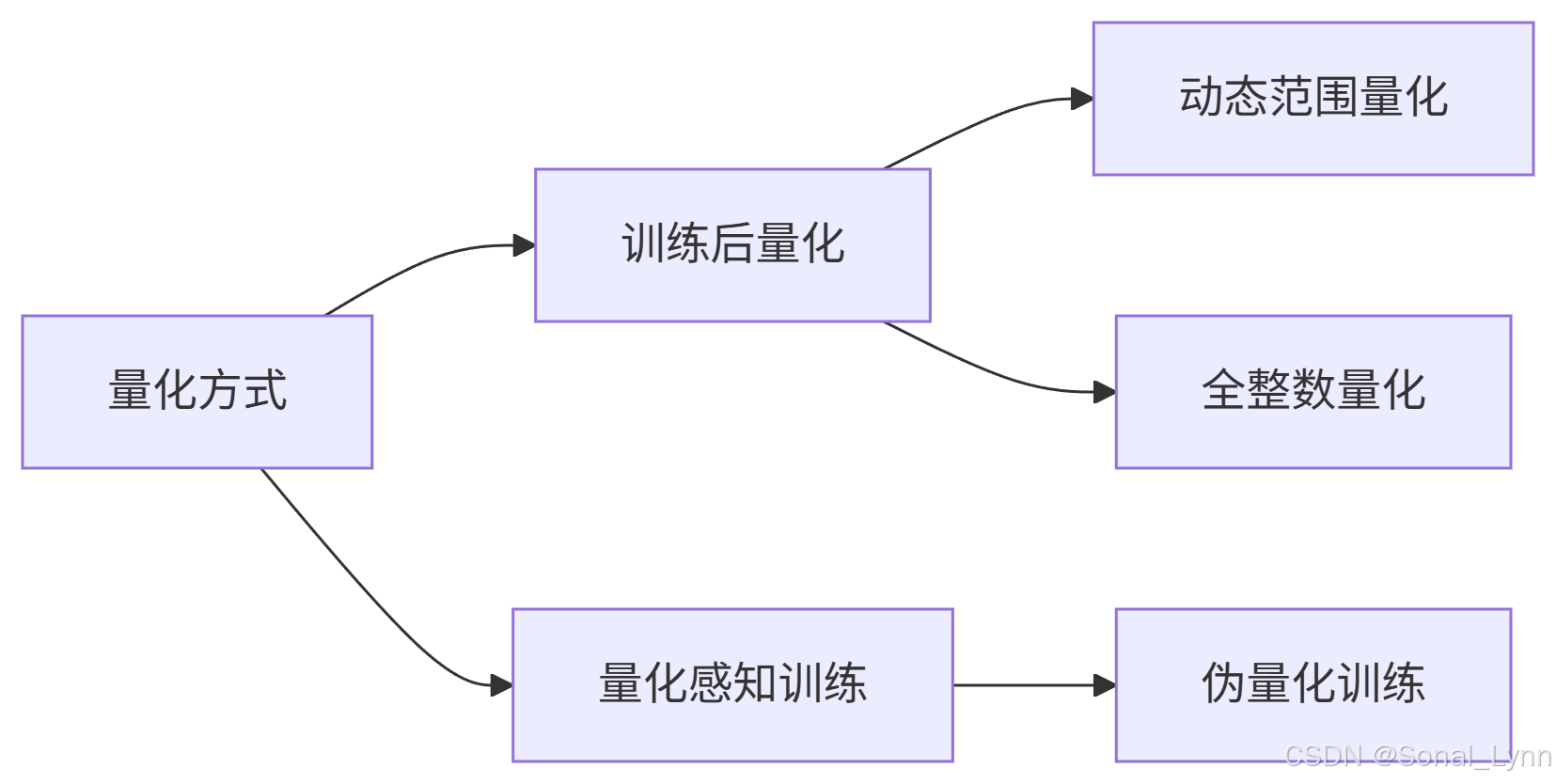
3.2 量化效果实测
在MobileNetV2上的实验结果:
| 量化方式 | 模型大小 |
|---|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











