








目录
一、稀疏自动编码器:从信息压缩到特征提取
1.1 稀疏性的本质意义
稀疏自动编码器(Sparse Autoencoder)的核心思想是通过神经元激活稀疏性约束,迫使模型学习数据的本质特征。就像一位语言学家在解读古代文字时,需要从有限的符号中提取关键信息,稀疏编码要求神经网络在编码层中仅有少量神经元被激活。
技术特点对比表
| 特性 | 普通自动编码器 | 稀疏自动编码器 |
|---|---|---|
| 编码层激活率 | 无限制 | 通常5%-10% |
| 正则化方式 | 无/L2正则 | KL散度约束 |
| 特征提取能力 | 一般 | 高度抽象 |
| 适用场景 | 数据压缩 | 特征工程 |
1.2 实现稀疏性的关键技术
from tensorflow.keras import layers, regularizers
# 构建稀疏自动编码器
encoder = keras.Sequential([
layers.InputLayer(input_shape=(784,)),
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='sigmoid',
activity_regularizer=regularizers.l1(1e-3)) # L1稀疏约束
])
decoder = keras.Sequential([
layers.Dense(256, activation='relu'),
layers.Dense(784, activation='sigmoid')
])
autoencoder = keras.Model(inputs=encoder.inputs,
outputs=decoder(encoder.outputs))稀疏性控制原理示意图
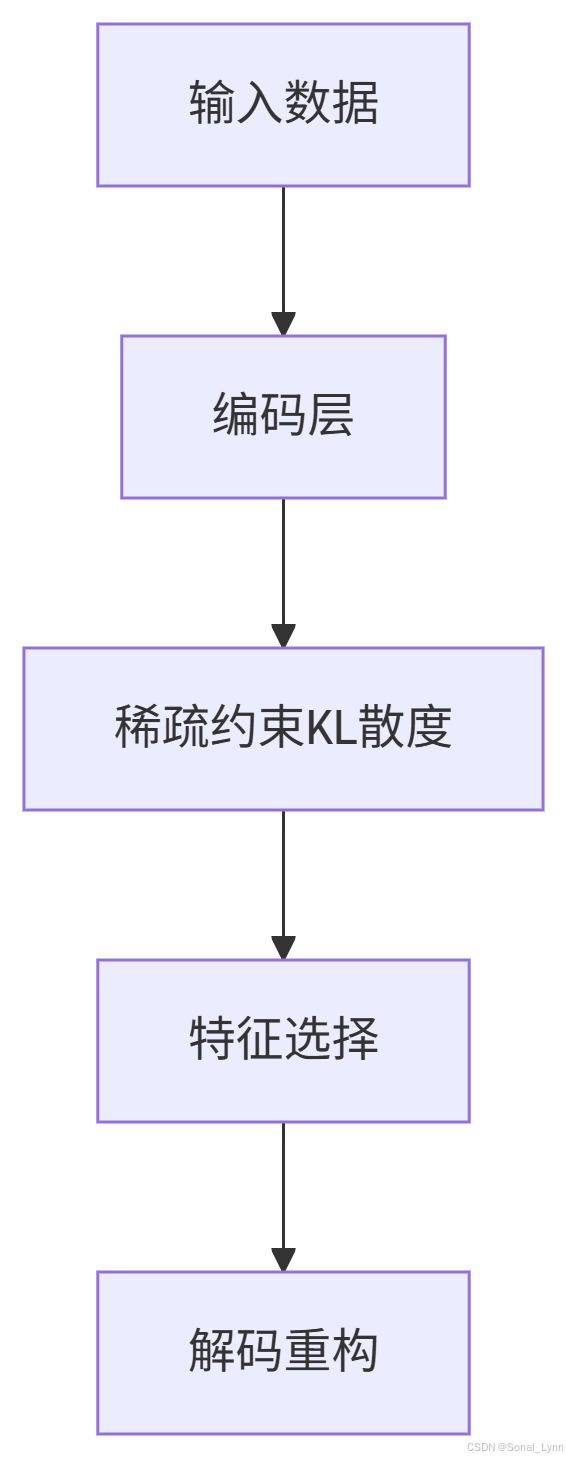
1.3 KL散度的数学本质
KL散度(Kullback-Leibler Divergence)度量两个概率分布的差异,在稀疏编码中:
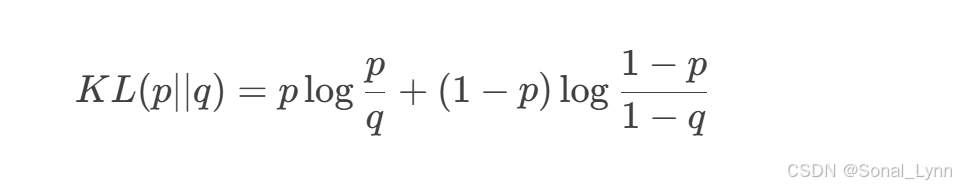
其中:
-
p:目标稀疏度(如0.1)
-
q:实际激活概率
当实际激活率q偏离目标p时,KL值增大,迫使模型调整参数降低损失。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











