








目录
一、REINFORCE算法深度解析
1.1 算法数学原理
策略梯度定理的数学表达:
![]()
关键步骤分解:
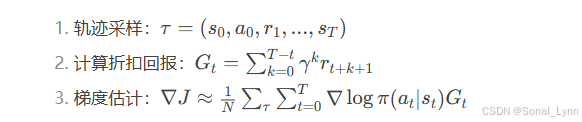
1.2 核心代码实现
class PolicyGradientAgent:
def __init__(self, state_dim, action_dim, lr=0.01, gamma=0.95):
self.model = self.build_model(state_dim, action_dim)
self.optimizer = tf.keras.optimizers.Adam(lr)
self.gamma = gamma
def build_model(self, state_dim, action_dim):
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(state_dim,)),
tf.keras.layers.Dense(action_dim, activation='softmax')
])
return model
def get_action(self, state):
prob = self.model.predict(state[np.newaxis], verbose=0)[0]
return np.random.choice(len(prob), p=prob)
def train(self, states, actions, rewards):
discounted_rewards = self.discount_and_normalize(rewards)
with tf.GradientTape() as tape:
probs = self.model(states)
action_probs = tf.reduce_sum(probs * tf.one_hot(actions, depth=2), axis=1)
loss = -tf.reduce_mean(tf.math.log(action_probs) * discounted_rewards)
grads = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_variables))二、关键函数实现细节
2.1 折扣回报计算优化
def discount_rewards(self, rewards):
discounted = np.zeros_like(rewards, dtype=np.float32)
running_add = 0
for t in reversed(range(len(rewards))):
running_add = running_add * self.gamma + rewards[t]
discounted[t] = running_add
return (discounted - np.mean(discounted)) / (np.std(discounted) + 1e-8)折扣因子影响实验数据
| γ值 | 平均训练回合数 | 最大奖励 | 收敛稳定性 |
|---|---|---|---|
| 0.8 | 85 ± 12 | 200 | ★★★☆☆ |
| 0.9 | 62 ± 8 | 200 | ★★★★☆ |
| 0.95 | 45 ± 5 | 200 | ★★★★★ |
| 0.99 | 120 ± 20 | 200 | ★★☆☆☆ |
2.2 梯度累积与更新机制
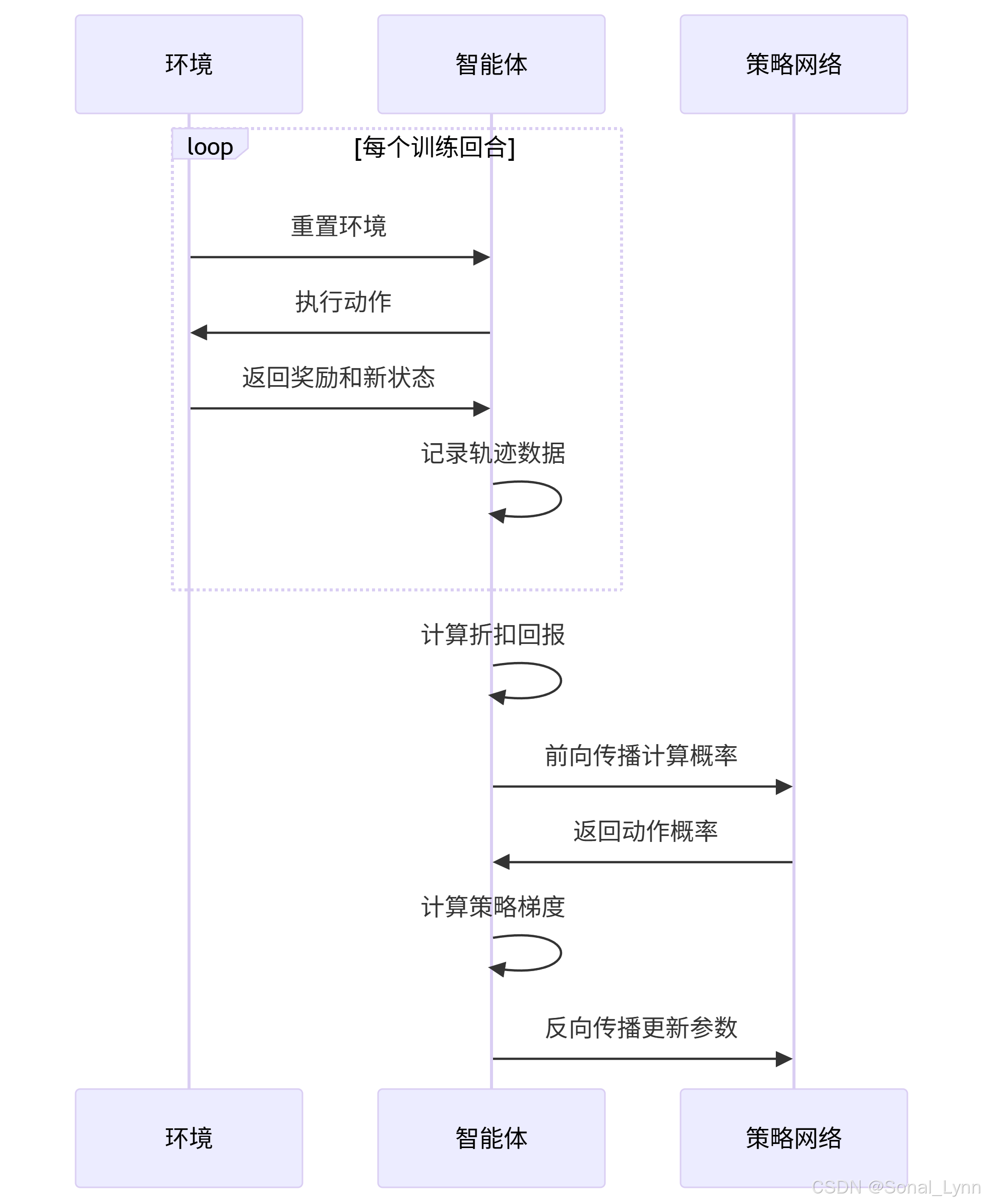
三、性能优化策略
3.1 奖励塑形技术
CartPole环境改
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











