






前言 为什么需要数据库设计?
设计数据表的时候,要考虑很多的问题:
- 用户需要哪些数据,我们在数据表中要保存哪一些数据
- 怎么保证数据表中的数据的正确性
- 如何降低数据表的冗余度
- 开发人员怎么才能更方便的使用数据库
如果数据库设计得不合理的话,可能导致下面的几种问题:
- 设计容易,信息重复,存储空间浪费
- 数据更新,插入,删除的异常
- 不能正确表示信息
- 丢失有效信息
- 程序性能差
我们可以看出设计良好的数据库是很重要的,它有下面的优点:
- 节省数据的存储空间
- 能够保证数据的完整性
- 方便进行数据库应用系统的开发
设计数据库,我们得重视数据表的设计,为了建立冗余度小,结构合理的数据库,设计数据库必须遵循一定的规则。
1 范式(Normal Formal)
1.1 范式概述
关系型数据库中,关于数据表设计的基本原则,规则就称为范式,范式是我们在设计数据库结构过程中需要遵循的规则和指导方法。

1.2 键和相关属性的概念
范式的定义会用到主键和候选键,我们先来看看相关的概念,数据库中的键是由一个或多个属性组成的,我们来看一下数据表中常用的几种键和属性的定义。
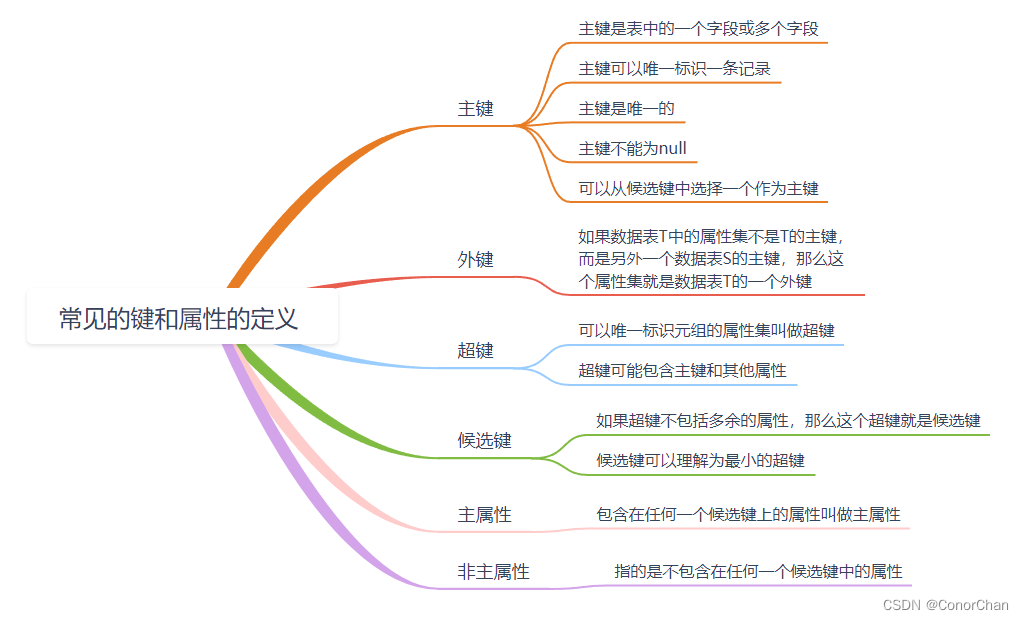
- 案例
司机(司机身份证号、姓名、性别、车牌号)
汽车(车牌号,车的颜色,司机身份证号)
1.超键:学生表中任意含有身份证号的组合——(身份证号)(身份证号、姓名)(身份证号、性别、姓名)等
2.候选键:属于超键,是最小的超键——(身份证号)
3.主键:是候选键中的一个——(身份证号)
4.外键:对于司机表,车牌号是外键;对于汽车表,司机身份证号是外键
5.主属性、非主属性:在司机表中,主属性是(司机身份证号)(车牌号),其他的属性 (姓名)(性别)都是非主属性
1.3 第一范式(1NF)
1NF 是对属性的原子性,要求属性具有原子性,不可再拆分为更小的数据项;
- 举例:
| 学号 | 姓名 | 系名 | 系主任 | 科名 | 分数 | 学籍信息 |
|---|---|---|---|---|---|---|
| 001 | 张三 | 计算机系 | 李雷 | 高等数学 | 87 | 本科,大二 |
| 002 | 李四 | 计算机系 | 李雷 | 大学英语 | 88 | 研究生,研三 |
很明显上面表格设计是不符合第一范式的,学籍信息列中的数据不是原子数据项,是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如下所示:
| 学号 | 姓名 | 系名 | 系主任 | 科名 | 分数 | 学历 | 所在年级 |
|---|---|---|---|---|---|---|---|
| 001 | 张三 | 计算机系 | 李雷 | 高等数学 | 87 | 本科 | 大二 |
| 002 | 李四 | 计算机系 | 李雷 | 大学英语 | 88 | 研究生 | 研三 |
实际上 ,1NF是所有关系型数据库的最基本要求 ,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。
- 属性的原子性是主观的,我们要根据实际项目的需求来设计,比如说地址,如果项目没有说要细分为省,市,县,镇这么具体的话,我们一般就可以不拆分。
1.4 第二范式(2NF)
2NF 在满足 1NF 的基础上,还要满足数据表里的每一条数据记录,都是可唯一标识的,而且所有的非主键字段,都必须完全依赖主键,不能存在“部分函数依赖”。
- 举例
| 学号 | 姓名 | 系名 | 系主任 | 科名 | 分数 |
|---|---|---|---|---|---|
| 001 | 张三 | 计算机系 | 李雷 | 高等数学 | 87 |
| 001 | 张三 | 计算机系 | 李雷 | 大学英语 | 88 |
| 001 | 张三 | 计算机系 | 李雷 | 数据库设计 | 89 |
| 002 | 李四 | 计算机系 | 李雷 | 高等数学 | 86 |
| 002 | 李四 | 计算机系 | 李雷 | java程序设计 | 90 |
| 002 | 李四 | 计算机系 | 李雷 | 大学英语 | 98 |
| 003 | 王五 | 财务系 | 韩梅梅 | 高等数学 | 96 |
| 003 | 王五 | 财务系 | 韩梅梅 | 财务基础 | 95 |
以上表格明显存在,部分依赖。比 如,这张表的主键是 (学号,课名),分数确实完全依赖于(学号,课名),但是姓名并不完全依赖于(学号,课名),让表格符合第二范式的要求,修改结果如下所示:
| 学号 | 科名 | 分数 |
|---|---|---|
| 001 | 高等数学 | 87 |
| 001 | 大学英语 | 88 |
| 001 | 数据库设计 | 89 |
| 002 | 高等数学 | 86 |
| 002 | java程序设计 | 90 |
| 002 | 大学英语 | 98 |
| 003 | 高等数学 | 96 |
| 003 | 财务基础 | 95 |
| 学号 | 姓名 | 系名 | 系主任 |
|---|---|---|---|
| 001 | 张三 | 计算机系 | 李雷 |
| 002 | 李四 | 计算机系 | 李雷 |
| 003 | 王五 | 财务系 | 韩梅梅 |
以上符合第二范式,去掉部分函数依赖依赖。
1.5 第三范式(3NF)
3NF 要先符合 2NF 的要求,并且除主键列的其它列之间,不能有传递依赖关系。
- 举例
| 学号 | 姓名 | 系名 | 系主任 |
|---|---|---|---|
| 001 | 张三 | 计算机系 | 李雷 |
| 002 | 李四 | 计算机系 | 李雷 |
| 003 | 王五 | 财务系 | 韩梅梅 |
在上面这张表中,存 在传递函数依赖:学号->系 名->系主任,但是系主任推不出学号。
上面表需要再次拆解:
| 学号 | 姓名 | 系名 |
|---|---|---|
| 001 | 张三 | 计算机系 |
| 002 | 李四 | 计算机系 |
| 003 | 王五 | 财务系 |
| 系名 | 系主任 |
|---|---|
| 计算机系 | 李雷 |
| 财务系 | 韩梅梅 |
1.6 范式的优缺点
- 优点
- 数据的标准化有助于消除数据库中的数据冗余
- 第三范式通常被认为在性能,扩展性和数据完整性方面达到了最好的平衡
- 缺点
- 降低了查询效率,因为范式等级越高,设计出来的表就越多,进行数据查询的时候就可能需要关联多张表,不仅代价昂贵,而且可能会使得一些索引失效
- 范式只是提出设计的标标准,实际设计的时候,我们可能为了性能和读取效率违反范式的原则,通过增加少量的冗余或重复的数据来提高数据库的读取性能,减少关联查询,实现空间换时间的目的
2 反范式化
范式只是提出的规范,但一些特殊情况下,我们要考虑的点比较多,例如
- 并发读。
- 减少表关联次数。
- 数据表的冗余设计。
- 热数据与冷数据。
- 数据的非实时性。
3.1 概述
- 遵循业务优先的原则
- 首先满足业务需求,再进来减少冗余
- 有时候我们想要对查询效率进行优化,反范式化也是一种优化思路,我们可以通过在数据表中增加冗余字段来提高数据库的读性能。
3.2 反范式的新问题
反范式虽然可以通过空间换实际,提升查询的效率,但是反范式也会带来一些新问题
- 存储空间变大了
- 一个表中字段做了修改,另外一个表中冗余字段也要同步进行修改,不然会导致数据不一致
- 如果用存储过程了支持数据的更新,删除等操作,如果操作频繁,就会消耗系统资源
在数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加复杂。
3.3 反范式的优点
注意:当冗余信息能大幅度提高查询效率的时候,我们才会采取反范式的优化。
- 提高查询速度。
- 避免多表查询。
- 降低数据库的压力。
总结
数据库设计应该也是分为三个境界的:
第一个境界,刚入门数据库设计,范式的重要性还未深刻理解。这时候出现的反范式设计,一般会出问题。
第二个境界,随着遇到问题解决问题,渐渐了解到范式的真正好处,从而能快速设计出低冗余、高效率的数据库。
第三个境界,再经过N年的锻炼,是一定会发觉范式的局限性的。此时再去打破范式,设计更合理的反范式部分。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









