







1. Activation FCN
1.1.常用于全链接层
1.1.1. Sigmoid FCN
梯度下降过程中, 容易出现过饱和和造成终止梯度传递现象, 且没有0中心化。
g
(
z
)
=
1
1
+
e
−
z
g(z) = \frac1{1 + e^{-z}}
g(z)=1+e−z1
- saturated nuerons can kill off the gradients
- sigmoid outputs are not zero-centered.
1.1.2. tanh FCN
f ( x ) = t a n h ( x ) f(x) = tanh(x) f(x)=tanh(x)
- Squash numbers to range[-1, 1]
- zero centered
- still kills gradientd when satuated

1.2. 常用于卷积层
- ReLU FCN (Rectified Linear Unit)
收敛快, gradient求解简单。 - but it still kill off haof of the gradients
f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x) - be carefule with your learning rate
1.3. Other actification fcn
1.3.1. dead ReLu and active ReLu
1.3.2. Leaky ReLU
f ( x ) = m a x ( 0.01 x , x ) f(x) = max(0.01x, x) f(x)=max(0.01x,x)
- does not satuate
- computationally efficient
- Converges much faster than
sigmoid/tanhin practice - will not kill off gradients
- sometimes it could also be following formula: f ( x ) = { 1 , x < 0 α x + 1 , x ≥ 0 f(x) = \begin{cases} 1, \quad x<0 \\\ \alpha x\, +\, 1, \quad x\geq 0 \end{cases} f(x)={1,x<0 αx+1,x≥0where α \alpha α is a small number.
1.3.3. Parametric Rectifier(PReLU)
f ( x ) = m a x ( α x , x ) f(x) = max(\alpha x, x) f(x)=max(αx,x)
1.3.4. Exponential Linear Units(ELU)
f ( x ) = { x , x > 0 α ( e x − 1 ) , x ≤ 0 f(x) = \begin{cases} x, \quad x>0 \\\ \alpha (e^{x} - 1), \quad x\leq 0 \end{cases} f(x)={x,x>0 α(ex−1),x≤0
- all benefits of ReLU
- closer to zero mean outputs
- negative saturation regime compared with leaky ReLU adds some robustness to noise
1.3.5. Maxout
max ( W 1 T x 1 + b 1 , W 2 T x 2 + b 2 ) \max(W_{1}^Tx_{1}\, +\, b_{1}, W_{2}^Tx_{2}\, +\, b_{2}) max(W1Tx1+b1,W2Tx2+b2)
- ReLU and leaky ReLu are particular examples of Maxout
2. CNN
2.1. Computer vision
对于CNN而言, 它是一块一块地对图像进行对比。 而这个小块, 我们称之为Features
2.2. 卷积
-
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定, 所以又可以看作一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是
卷积。下图中, 途中左边部分是原始输入数据, 途中中间部分是滤波器filter, 图中右边是输出的二维数据。

S ( i , j ) = ( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( m , n ) K ( i − m , j − n ) S(i, j)=(I*K)(i, j)=\sum_{m}\sum_{n}I(m, n)K(i-m, j-n) S(i,j)=(I∗K)(i,j)=m∑n∑I(m,n)K(i−m,j−n)
- 一次操作(一层)中使用多个卷积 kernel 得到该尺度下的多张feature map。
- 多层(次)提取不同尺度下的不同特征信息
-
由于上述第一点改进, 即使第一张图片输入通道只有一个通道, 后面其他层的输入都是多通道。所以对应我们的convolution kernel 也是多通道。 即输入图像和convolution都添加了channel 这个dimension, 那么convolution layer中的convolution operation变为如下formula:
S ( i , j , c ) = ( I ∗ K c ) ( i , j ) = ∑ c ∑ m ∑ n I ( m , n , c ) K c ( i − m , j − n , c ) S(i, j, c)=(I*K_{c})(i, j) = \sum_{c}\sum_{m}\sum_{n}I(m, n, c)K_{c}(i-m, j-n, c) S(i,j,c)=(I∗Kc)(i,j)=c∑m∑n∑I(m,n,c)Kc(i−m,j−n,c) -
Conclusion of feedforward calculation of convolution and corresponding function.
- convolution operation 最重要的是如何确定convolution kernel的核数
- BP 告诉我们如何通过监督学习方法来优化我们convolution kernel的数值, 是我们能够找到在对应任务下表现最好的convolution kernel(feature)。
- 在我们实现的convolution layer的class中, 还应该包含一个backward方法, 用于反向传播求导。
2.3. 图像上的卷积
输入是一定区域大小(width*height)的数据, 和filter做内积后得到新的二维数据。
Basically, 左边是图像输入, 中间部分是filter, 不同的filter会得到不同的输出数据, 比如颜色深浅、轮廓。相当于如果想要提取图像的不同特征, 则用不同的filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。

2.4. GIF 动态卷积
在CNN中, filter每次计算完成后, 数据窗口会不断移动, 直到计算完所有data。
- depth:神经元个数, 决定输出的depth厚度, 同时代表filter个数
- stride:决定滑动多少步可以到达边缘。
- zero-padding(填充值):在外围边缘补充若干圈0, 方便从初始位置以stride为单位可以刚好画到末尾位置,通俗来说就是为了中场能够被stride整除。
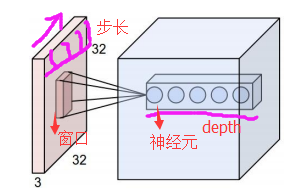
在下图中, 参数如下:
- depth = 2
- stride = 2
- zero-padding = 1
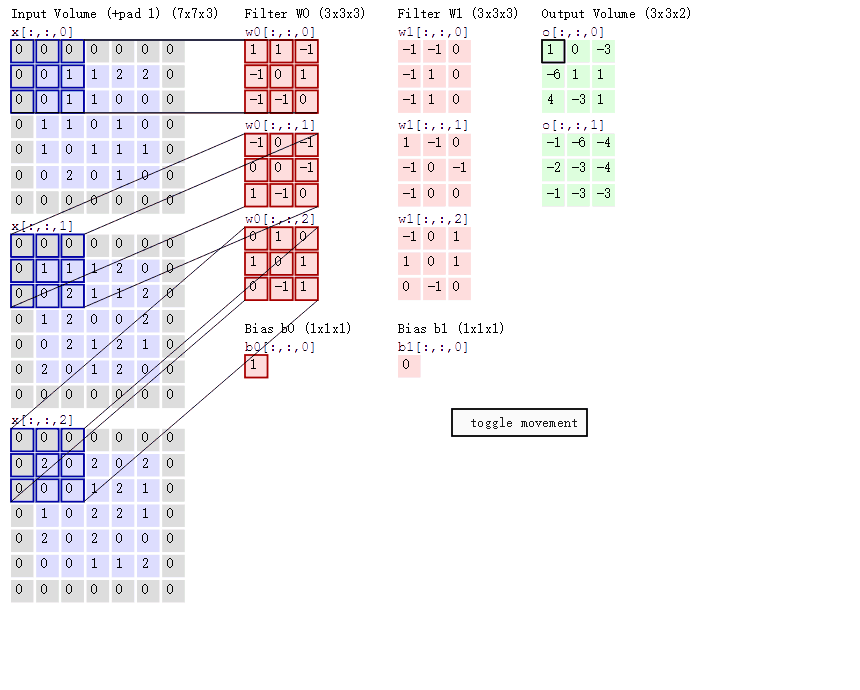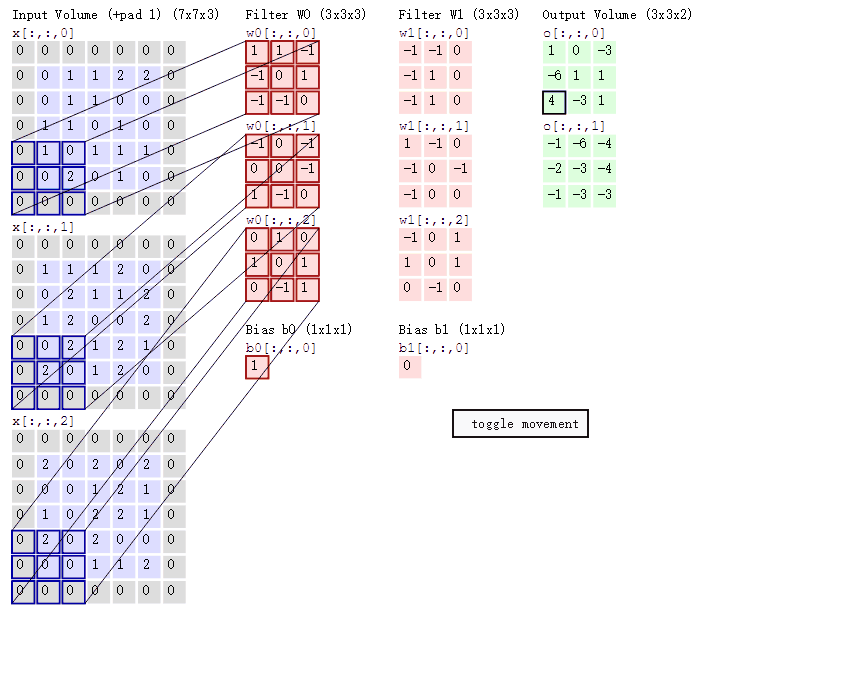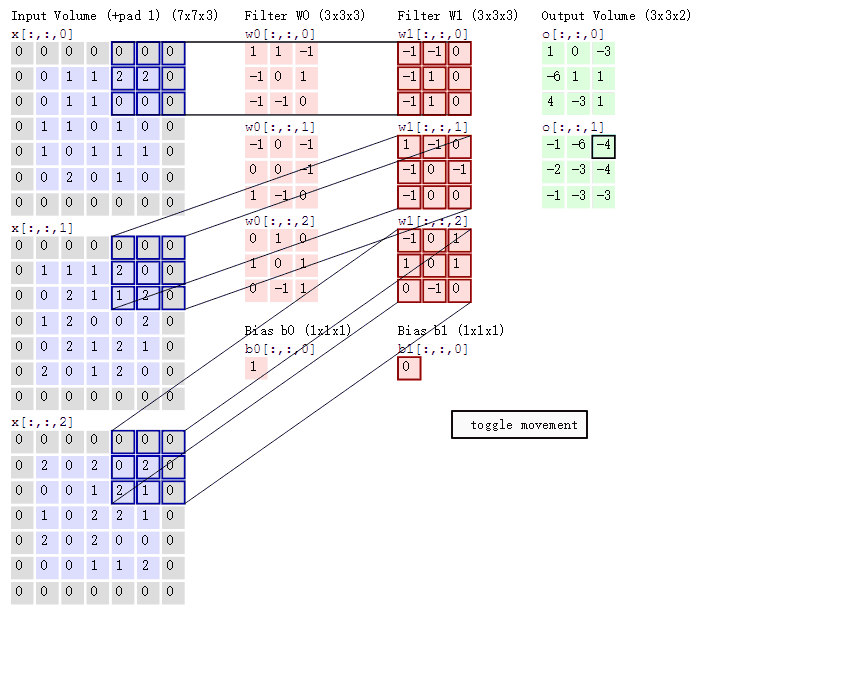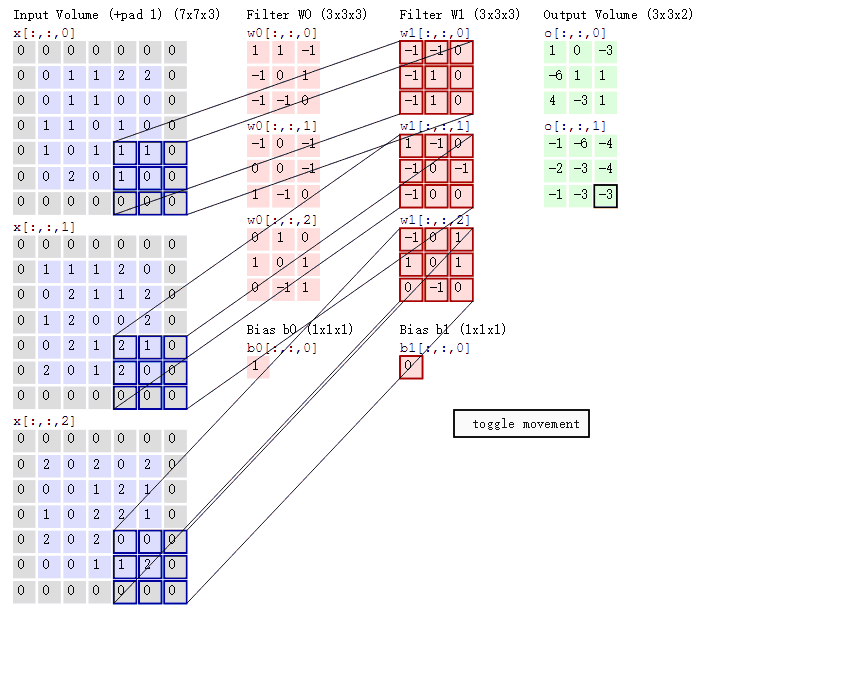
然后分别以两个filter为轴滑动数组进行convolution calculation。 - 左边为输入(7*7*3, 7*7 表示图像的pixel和width-height, 3表示R、G、B三个颜色channel)
- 中间为2 filters
- 右侧为result
随着左边窗口的滑动, filter对不同的局部数据进行convolution。 - data窗口在滑动, 导致input在发生改变, 但是filter始终未发生变化, 即采用了CNN中的参数(weights)共享机制
- if we have m*m matrix as input, and n*n as filter, the stride is k, we will get the output matrix shape, i.e.
(m-n)/k + 1, which shoule be integer or it won’t fit.

2.5. Pooling layer
- pooling, basically, 为区域平均或最大。
- 下图展示的是区域最大
max pooling, which is commonly use than aveage pooling.

- makes the representation smaller and more manageable
- operates over each activation map independaently

2.6. Padding in practice
- in pactice, we usually add padding border into our input matrix. And noramally, we use zero pad the border.
3. pre-work and corresponding process
3.1. weights initialisation
W = 0.01 * np.random.randn(D, H)
# it works for small networks, but it have problems in deeper neural networks
- we should not initialise all weights to be zero, cause we want our neurons to do different thing
- there is anoter mathod to initilise weights, which has been confirmed as practical, i.e. Calibrating the variances with 1 n \frac1{\sqrt n} n1
w = np.random.randn(n) / sqrt(n) # where n is the num of inputs
3.2. Batch normalization
- input:
x : N × D x: N \times D x:N×D - Learnabke params:
γ , β : D \gamma, \beta: D γ,β:D - Intermediates:
μ , σ : D \mu, \sigma: D μ,σ:D
x ^ : N × D \hat{x} : N \times D x^:N×D - Output:
y : N × D y : N \times D y:N×D - Update
μ j = 1 N ∑ i = 1 N x i , j \mu_{j} = \frac{1}{N}\sum_{i=1}^{N}x_{i, j} μj=N1i=1∑Nxi,j
σ j 2 = 1 N ∑ i = 1 N ( x i , j − μ j ) 2 \sigma_{j}^2 = \frac{1}{N}\sum_{i=1}^{N}(x_{i, j}\, -\, \mu_{j})^2 σj2=N1i=1∑N(xi,j−μj)2
x i , j ^ = x i , j − σ j σ j 2 + ε \hat{x_{i, j}} = \frac{x_{i, j}\, -\, \sigma_{j}}{\sqrt{\sigma_{j}^2\, +\, \varepsilon}} xi,j^=σj2+εxi,j−σj
y i , j = γ j x i , j ^ + β j y_{i, j} = \gamma_{j}\, \hat{x_{i, j}}\, +\, \beta_{j} yi,j=γjxi,j^+βj
3.3. learning rate
3.4. Hyperparameter search
- grid search
- random search
3.5. Optimization
3.5.1. SGD
x t + 1 = x t − α ∇ f ( x t ) x_{t+1}= x_{t}\, -\,\alpha\nabla f(x_{t}) xt+1=xt−α∇f(xt)
while True:
dx = compute_gradient(x)
x += learning_rate * dx
3.5.2. SGD + Momentum
v
t
+
1
=
ρ
v
t
+
∇
f
(
x
t
)
v_{t+1}=\rho v_{t} \, +\, \nabla f(x_{t})
vt+1=ρvt+∇f(xt)
x
t
+
1
=
x
t
−
α
v
t
+
1
x_{t+1} = x_{t}\, -\, \alpha v_{t+1}
xt+1=xt−αvt+1
- build up ‘velocity’ as a running mean of gradients
- Rho gives ‘friction’, typically rho = 0.0 or 0.99
vx = 0
while True:
dx = compute_gradient(x)
vx = rho * vx + dx
x += learning_rate * vx
3.5.3. Nesternov Momentum
v
t
+
1
=
ρ
v
t
−
α
∇
f
(
x
t
+
ρ
v
t
)
v_{t+1}= \rho v_{t} - \alpha \nabla f(x_{t} + \rho v_{t})
vt+1=ρvt−α∇f(xt+ρvt)
x
t
+
1
=
x
t
+
v
t
+
1
x_{t+1} = x_{t} \, +\, v_{t+1}
xt+1=xt+vt+1
3.5.4. AdaGrad
grad_squard = 0
while True:
dx = compute_gradient(X)
grad_squard += dx * dx
x -= learning_rate * dx / (np.sqrt(grad_squard) +1e-7)
- added element-wise scaling of the gradient based on the historical sum of squares in each dimension
- not so common in solving questions
3.5.5. RMSProp
grad_squard = 0
while True:
dx = compute_gradient(X)
grad_squard = decay_rate * grad_squared + (1 - decay_rate) * dx *dx
x -= learning_rate * dx / (np.sqrt(grad_squard) + 1e- 7)
- SGD + Momentum could do better than RMSProp, which could be a litte different and better than original SGD
3.5.6. Adam
first_moment = 0
second_moment = 0
for t in range(num_iterations):
dx = compute _gradient(x)
# Momentum
first_moment = beta1 * first_moment + (1 - beta1) * dx
second_moment = beta2 * second_moment + (1 - beta2) * dx * dx
# bias correstion
first_unbias = first_moment / (1 - beta1 ** t)
second_unbias = second_moment / (1 - beta2 ** t)
# AdaGrad/ RMSprop
x -= learning_rate * first_moment / ...(np.sqrt(second_moment) + 1e-7) # 1e-7 is to avoid we could divide by zero
- at first time, we initilise second_moment as zero, even though we run after one time, the second_moment could be very close to zero.
- bias correction for the fact that first and second moment estimates start at zero.
- Adam with
beta1 = 0.9, beta2 = 0.999, and learning_rate = 1e-3 or 5e-4is a good starting point for many models.
3.6. Sanity checks Tips
- this is the description of what kinds of tips we need to use during sanity check
- Look for correct loss at chance performance
- Overfit a tiny subset of data
4. 代码实现
- filter大小应该是个奇数, 并且是个方阵
- 该函数首先确保每个滤波器的深度等于图像通道的数目,代码如下。if语句首先检查图像与滤波器是否有一个深度通道,若存在,则检查其通道数是否相等,如果匹配不成功,则报错














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









