






关于三视图的制作,很早之前就有些小伙伴留言如何实现,当时只是给了大家制作的实现思路,最近又有些小伙伴提到了这个问题,今天我们就详细讨论一下这个问题,看一下最常见三视图的制作有哪些实现方式。话不多说,我们开整。
一. 实现方式一: 通过提示词实现
三视图提示词格式:
(three views of character:1.2),(three views of the same character in the
same outfit:1.2),full body,front,side,back,front view,side vide,back
view,front view of girl,side view of girl,back view of girl,【主体描述】 simple
background,white background,masterpiece,best quality
下面我们以具体示例看一下效果。
- 大模型:IP DESIGN | 3D可爱化模型 V4.0
模型下载请看文末扫描即可获取)
- 正向提示词(这里只补充主体描述的关键词)
Prompt :1girl,blonde hair,long hair,princess peach,blue
eyes,lips,eyelashes,earrings,crown,hood,casual提示词 :1个女孩,金发,长发,桃公主,蓝眼睛,嘴唇,睫毛,耳环,皇冠,兜帽,休闲
- 反向提示词
nsfw,lowres,bad anatomy,bad hands,text,error,missing fingers,extra
digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg
artifacts,signature,watermark,username,blurry,artist
name,
-
采样器:Euler a
-
采样迭代步数:25
-
图片宽高:768*512
-
CFG: 7
我们看一下生成的图片效果。


相关说明:
(1)这种实现方式可控性不太好,需要大量抽签才能抽到符合要求的图片。不管是基于SD1.5还是基于SDXL的大模型,很多大模型对于三视图的准确理解还是不到位的。当然如果有能很好理解三视图关键词的的大模型,那这种实现方式也是很好的哈。
(2)如果出现生成不了三视图中某个视图效果,可以适当提高一下该视图的提示词权重。
二. 实现方式二:借助三视图LORA实现
我们可以在liblibAI的官网,通过关键词"三视图"搜索到相关的LORA。这里有很多支持各种不同风格的三视图LORA模型。
这里我们以使用量最大的 mw_3d角色ip三视图q版
LORA为示例讲解。该lora模型有支持SDXL大模型的尝鲜版(V2.0.1)和支持SD1.5大模型的版本(最新版V1.1)。
该版本使用的是基于SDXL1.0基础版本的底膜。该版本对动物的支持貌似更好了一些。触发词:mw_sanshitu、three view、full body
下面我们以具体示例看一下效果。
-
大模型:SDXL_1.0
-
正向提示词
Prompt :mw_sanshitu,full body,mermaid,simple
background,standing,lora:mw\_3d角色ip三视图q版\_2.0.1:0.9\提示词 :Mw_sanshitu,全身,美人鱼,简单背景,站立
- 反向提示词
easynegative,dark,bad hands,bad feet,worst quality,low quality,normal
quality,bad artist,bad anatomy,blurry
-
loar: lora:mw\_3d角色ip三视图q版\_2.0.1:0.9
-
采样器:Euler a
-
采样迭代步数:25
-
图片宽高:1024*768
-
CFG: 7
我们看一下生成的图片效果。


上面我们没有加三视图的视角关键词,我们把视角关键词添加一下:
Prompt:mw_sanshitu,full body,front view,side view,back view,mermaid,simple
background,standing


当然也不能每次都能正确理解,但是抽签概率已经很大了。
相关说明
:这种方式对于创作三视图来说,是相当不错的实现方式,但是没有办法准确的控制主体的姿势。三视图的视角仍然是随机的,虽然可以通过提示词来控制,但是还是需要抽签概率。
三. 实现方式三:使用ControlNet的 openpose模型
这种实现方式主要是通过ControlNet的Openpose插件可以实现人物姿势自由控制,我们借助这个插件生成的3种不同视角的人体姿势,从而达到精准控制人物姿势的3视图效果。
关于Openpose灵活人物姿势的控制可以参照之前的文章了解。AI绘画Stable Diffusion 中 OpenPose骨骼编辑器 | 以后出图姿势自由了!
下面我们来看一下具体示例操作步骤。
【第一步 】:制作一张人物三视图的特征图片。
下面这张三视图的特征图片分别对应人物的:正面、侧面、背面。
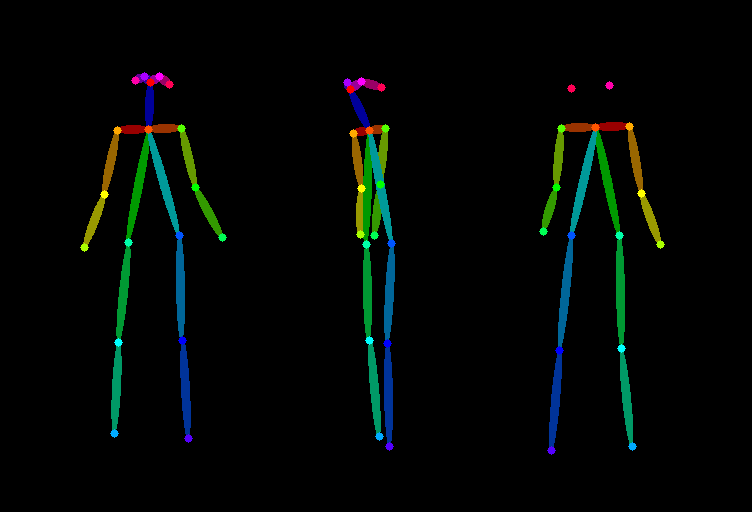
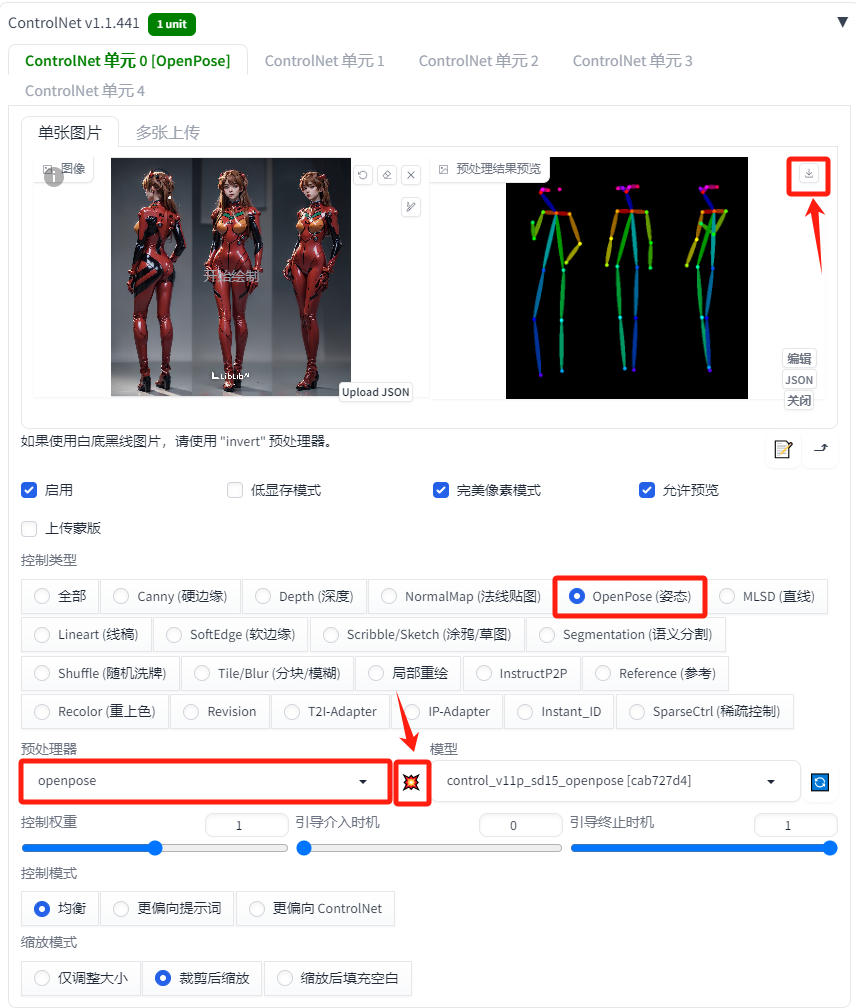
相关说明:对于我们来说制作三视图的特征图片并不容易,我们可以在LiblibAI网站或者C站上找一张三视图的真人图片,然后在ControlNet中使用Openpose模型的Openpose预处理器生成一张三视图的特征图片。具体操作如下。
【第二步 】:大模型选择、提示词编写、相关参数设置
-
大模型:AWPortaint V1.4
-
正向提示词
Prompt :(three views of character:1.2),(three views of the same
character in the same outfit:1.2),1girl,long hair,wear school uniform,a
proud and confident smile expression,studio fashion portrait,studio
light,pure white background,提示词 :1个女生,长发,穿着校服,带着骄傲自信的微笑表情,工作室时尚肖像,工作室灯光,纯白色背景
- 反向提示词
ng_deepnegative_v1_75t,(badhandv4:1.2),(worst quality:2),(low
quality:2),(normal quality:2),lowres,bad anatomy,bad
hands,((monochrome)),((grayscale)) watermark,moles,large breast,big breast,
-
采样器:DPM++ 2M Karras
-
采样迭代步数:30
-
图片宽高:768*512
-
CFG: 7
-
高分辨率修复:放大算法Lanczos,重绘幅度0.4 重绘采样步数30
-
Adetailer插件:脸部模型 face_yolov8n
【第三步 】:ControlNet Openpose模型设置

相关参数设置如下:
-
控制类型:选择"OpenPose(姿态)"
-
预处理器:none (由于上传的是三视图特征图,这里就不需要再设置预处理器了)
-
模型: control_v11p_sd15_openpose
【第四步 】:图片的生成


相关说明:
(1)使用ControlNet的openpose模型制作的三视图相对来说最稳定,每次都可以出三视图的效果。
(2)这种方式可以实现其他任意视图,不仅仅局限在三视图。
上面分享目前最常用的制作三视图的三种方法,在实际应用中,大家可以综合几种方法一起使用,比如结合实现方式二和三,在不同的场景可能会带来更好的效果。
最后
如果你是真正有耐心想花功夫学一门技术去改变现状,我可以把这套AI教程无偿分享给你,包含了AIGC资料包括AIGC入门学习思维导图、AIGC工具安装包、精品AIGC学习书籍手册、AI绘画视频教程、AIGC实战学习等。
这份完整版的AIGC资料我已经打包好,长按下方二维码,即可免费领取!

【AIGC所有方向的学习路线思维导图】
【AIGC工具库】

【精品AIGC学习书籍手册】
【AI绘画视频合集】
这份完整版的AIGC资料我已经打包好,长按下方二维码,即可免费领取!

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









