







参考博文:https://blog.csdn.net/qq_17677907/article/details/88685705
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
Spark相对于Hadoop的优势
Hadoop虽然已成为大数据技术的事实标准,但其本身还存在诸多缺陷,最主要的缺陷是其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。
回顾Hadoop的工作流程,可以发现Hadoop存在如下一些缺点:
- 磁盘IO开销大。每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘中,IO开销较大;
- 延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到IO开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
Spark主要具有如下优点:
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
- Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
- Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销
Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop少2-5倍。
但Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
Spark基本概念
Spark几个重要的概念:
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
- 应用:用户编写的Spark应用程序;
- Task:一个作业包含多个RDD及作用于相应RDD上的各种操作;
- Stage:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
DAG
-
DAG 有向无环图(数据执行过程,有方法,无闭环)
-
DAG描述多个RDD的转换过程,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)
-
DAG是有边界的:开始(通过SparkContext创建的RDD),结束(触发Action,调用run Job就是一个完整的DAG就形成了,一旦触发Action就形成了一个完整的DAG)
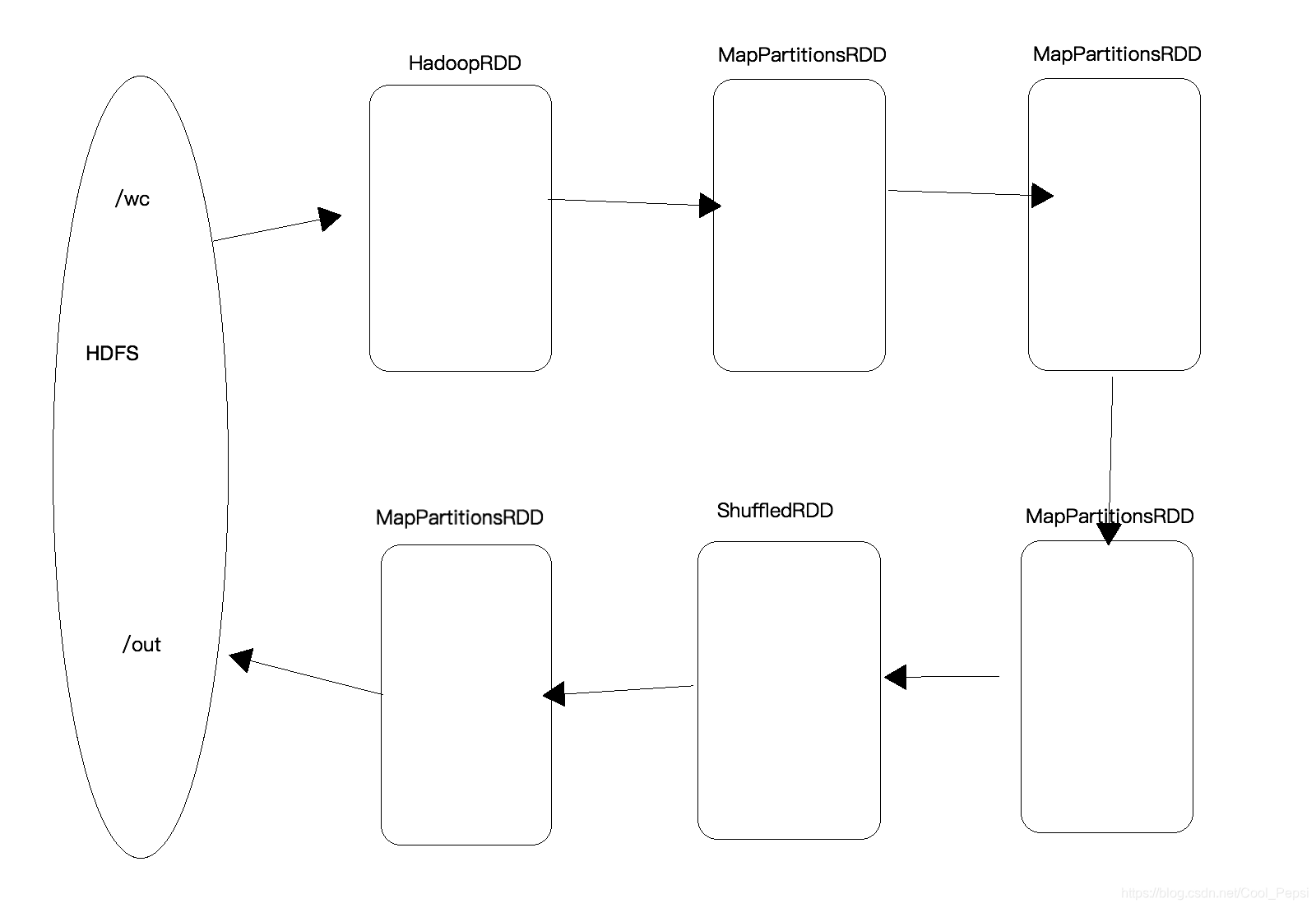
-
一个RDD只是描述了数据计算过程中的一个环节,而DGA由一到多个RDD组成,描述了数据计算过程中的所有环节(过程)
-
一个Spark Application中是有多少个DAG:一到多个(取决于触发了多少次Action)
Task 和 Stage 之间的关系
以WordCount为例(scala版本):
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(getClass.getSimpleName).setMaster("local[2]")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0))
val words = lines.flatMap(_.split(" "))
val wordAndOne = words.map(x => (x,1))
val reduced = wordAndOne.reduceByKey(_ + _)
reduced.saveAsTextFile(args(1))
sc.stop()
}
}
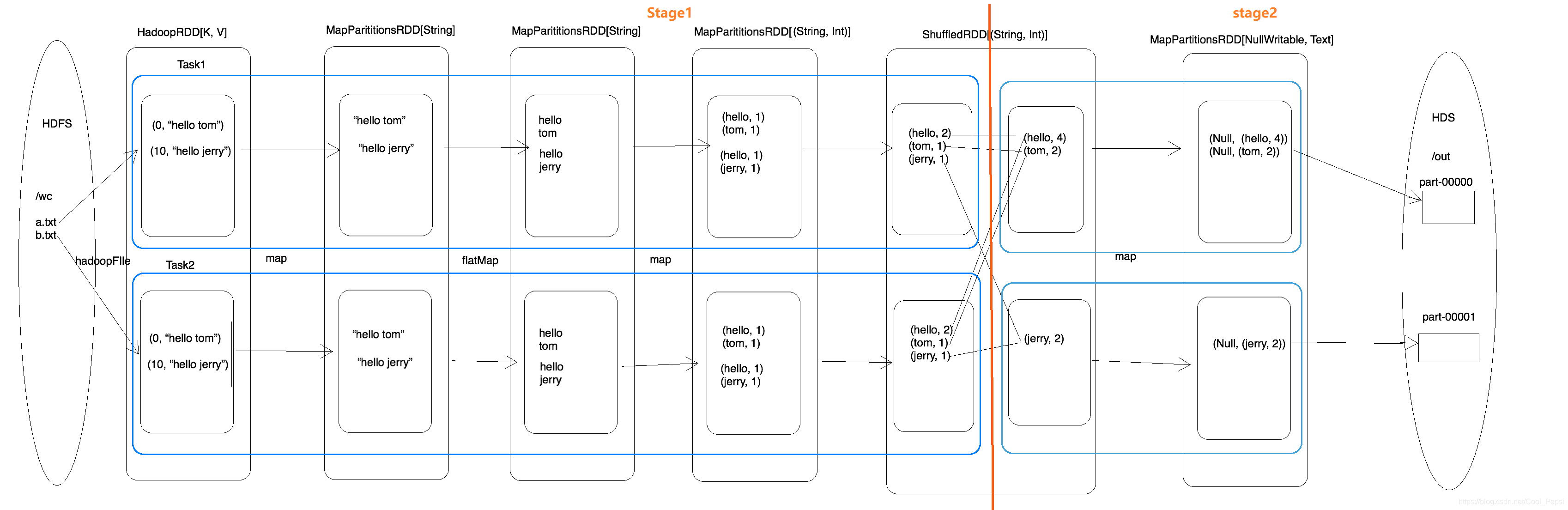
- sc.textFile(args(0))会从HDFS中读取文件数据,假设HDFS中有两个大小差不多的文件,而RDD有两个分区,那么就是一个分区读取一个文件;这句语句会创建出两个RDD:HadoopRDD和MapPartitionsRDD,HadoopRDD读取数据时会变成KV形式,而MapPartitionsRDD会将KV -> V
- flatMap() 和 Map() 都会创建出MapPartitionsRDD
- reduceByKey() 会创建ShuffledRDD,在shuffle阶段会有局部聚合和全局聚合两个步骤,局部聚合后会将中间结果存储在磁盘中,而全局聚合之前需要将中间结果读取出来再进行操作。
shuffle是切分Stage的依据,图中的橙色线切分两个Stage。因为有两个分区所以Stage1和Stage2会各生成两个Task(一个分区一个Task),一共4个Task,一个Task包含多个RDD及作用于相应RDD上的各种操作 - saveAsTextFile(args(1))会生成MapPartitionsRDD,写入HDFS时会将V -> KV
Spark运行基本流程
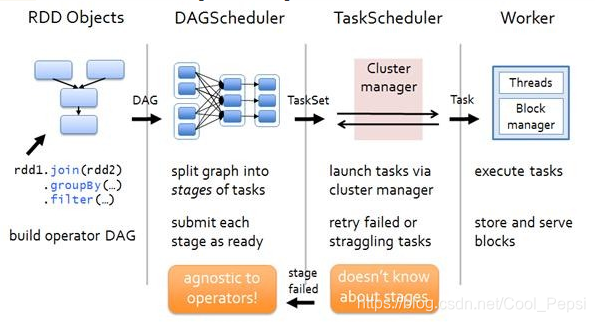
四个步骤
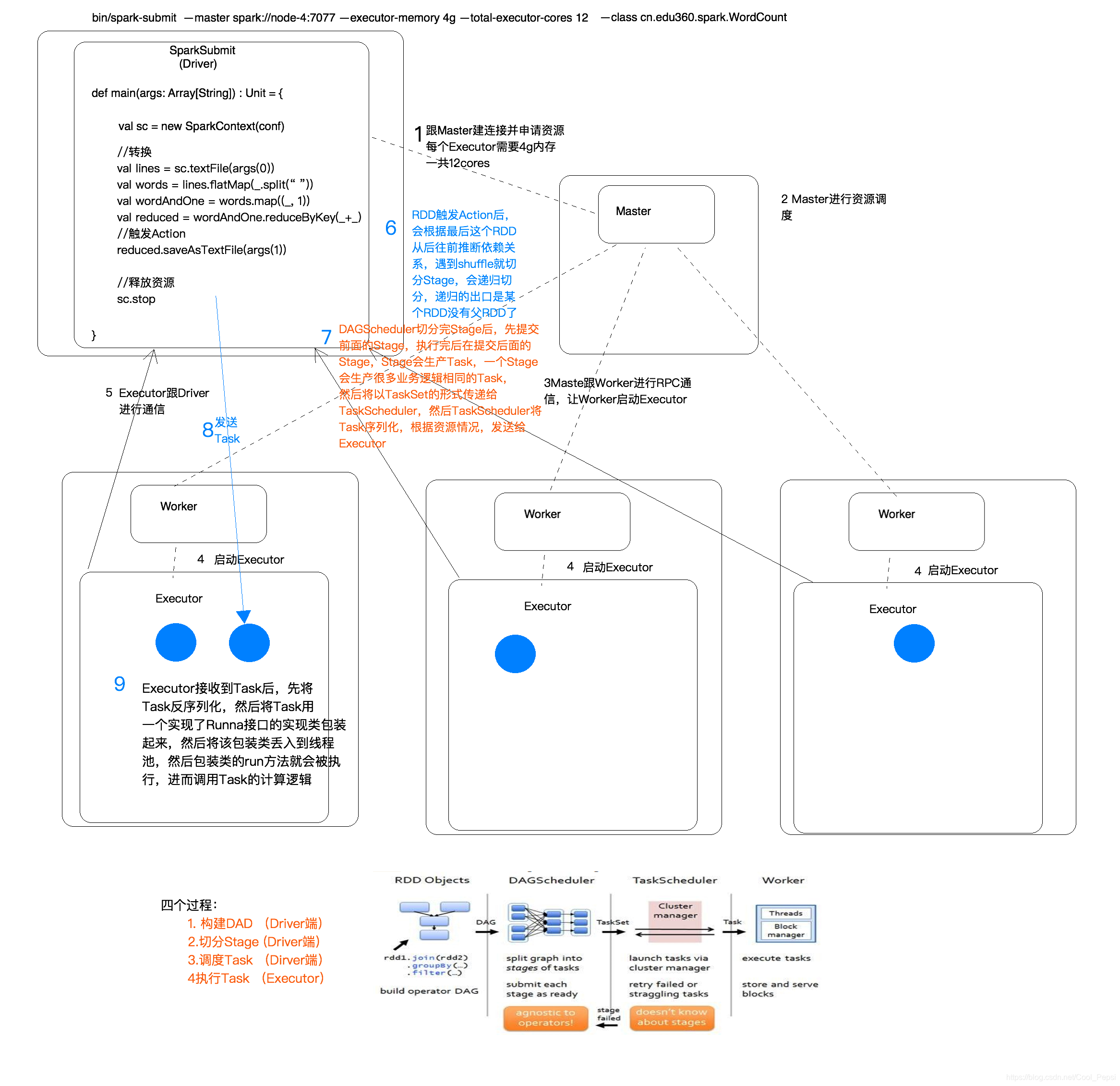
- 构建DAG:调用RDD上的方法
- 切分Stage:
DAGScheduler:将一个DAG切分成一到多个Stage,DAGScheduler切分的依据是Shuffle(宽依赖);
先提交前面的Stage,执行完后再提交后面的Stage;
Stage会生成Task,一个Stage会生成很多业务逻辑相同的Task,然后Stage中生成的Task以TaskSet的形式给TaskScheduler - 调度Task:TaskScheduler调度Task,将Task序列化,根据资源情况将Task调度到相应的Executor中
- 执行Task:Executor接收Task,先将Task反序列化,然后将Task用一个实现了Runnable接口的实现类包装起来,然后将该包装类丢入到线程池中,包装类的run方法就会被执行,进而调用Task的计算逻辑
为什么要切分Stage?
- 一个复杂的业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)
- 如果有shuffle,那么就意味着前面阶段产生的结果后,才能执行下一个阶段,下一个阶段的计算要依赖上一个阶段的数据。
- 在同一个Stage中,会有多个算子,可以合并在一起,我们称其为pipeline(流水线:严格按照流程、顺序执行)
宽依赖:父RDD的一个分区的数据给了子RDD的多个分区,即使存在这种可能,也是宽依赖(有shuffle阶段的,例如groupByKey)
执行过程全流程(以WordCount为例)














 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









