










An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition
文章目录
摘要
基于骨架的动作识别是一项重要任务,要求从给定的骨骼序列中充分了解人体动作的运动特征 。近期的研究表明在任务中扩展骨架序列的时空特征是至关重要的。然而,怎么有效的提取判别时空特征仍然是一项挑战。本文提出的注意力增强图卷积LSTM(AGC-LSTM)网络,用于骨架数据的动作识别。提出的AGC-LSTM网络不仅能捕获在空间配置和时间动态中的判别特征,还能扩展时空域之间的关联关系。同时,本文还提出一个时间分层体系结构来增强AGC-LSTM顶层的时间接收域,该方法提高了高级语义表示的学习能力,并显著降低了计算成本。另外,为了选择判别空间信息,注意力机制在每个AGC-LSTM层中增强关键关节的信息。然后在两个数据集NTU+RGB-D和Northwestern-UCAL中进行实验,实验结果跟一些其他方法进行比较。
一、引言
在计算机视觉领域,人类动作识别起着基础性和重要的作用,目的是预测视频中的动作类别。由于其广泛的潜在性应用已经研究数十年并且现在依然很流行,例如视频监控、人机交互、运动分析等等。
动作识别在计算机视觉领域是一个具有挑战性的任务。针对基于RGB视频和三维骨架数据的人体动作识别,有各种各样的研究方法。尽管基于RGB视频的方法取得了很好的成绩,但还存在一些局限,例如背景杂波、照明变化、外观变化等等。3D骨架数据是将人体结构表示为一系列关键关节的3D坐标。由于骨架序列不包含颜色信息,因此不受RGB视频的限制。这种立邦的表现方式允许对人类行为的更有区别的时间特征建模。
对于基于骨骼的动作识别,现有的方法探索了不同的模型来学习空间和时间特征。很多方法都在试图设计一个有效的模型来识别骨骼序列的时空特征。但是怎么有效的提取判别空间和时间特征仍然是一个巨大的挑战。
人类骨架序列的三个显著特征:
1)每个骨骼及其相邻关节之间的相关性较强,骨架序列包含了丰富的体系结构信息;
2)人体结构的同一关节的时间连续性;
3)时间和空间域之间的相关性;
本文提出了一种新的、通用的框架,主义增强图卷积LSTM网络(AGC-LSTM),用于基于骨骼的动作识别,该网络通过同步学习上述时空特征来改进骨骼表示。
提出的AGC-LSTM网络的总体架构如下图2所示。首先,每个关节的坐标被传送到具有线性层的空间特征。然后连接两个连续帧中的不同的空间特征来组成一个扩展特征。为了消除这两个特征之间的尺度差异,采用共享LSTM对每个联合序列进行处理。然后,申请三个AGC-LSTM层进行建模时间特征,如图1中。

由于AGC-LSTM中有图卷积操作,因此不仅可以有效的捕获空间配置和时间动态的判别特征,还可以扩展时空域之间的相关关系。注意力机制在每个时间步长增强关键关节的特征,可以促进AGC-LSTM学习更多的判别特征。例如,肘,手腕和收的特征对动作握手非常重要,在识别行为的过程中应当加强。受cnn中空间池化的启发,我们提出了一种时间层次结构,采用时间平均池化来增加AGC-LSTM顶层层的时间接受域,从而提高了高级时空语义特征的学习能力,并显著降低了计算成本。最后,利用所有关节的全局特征和最后一层AGC-LSTM中聚焦关节的局部特征来预测人类动作的类别。虽然基于关节的模型达到了最先进的结果,也探索了提出的模型在部件级的性能。在基于零件的模型中,每个零件的链接作为一个节点来构造图。此外,基于关节和领边的双流模型可以进一步提高性能。

本文的主要贡献可以总体概括为一下几点:
1、提出了AGC-LSTM网络,首次尝试使用图卷积LSTM;
2、有效铺货判别时空特征,注意力机制被用来增强关键关节的特征,有助于改善时空表达;
3、使用时间层次结构,提高高层次的时空语义特征的学籍能力,降低计算代价;
4、与其他方法比较。
二、相关工作
GNN:基于图的模型由于其对图结构数据的有效表示而引起了人们的广泛关注。主要包括GNN和GCN,GCN中有分为两种方法:空间透视,光谱透视。本文使用AGC-LSTM网络来学习骨架序列中的时空特征。
骨架动作识别:基于骨骼数据的人体动作识别由于其有效的运动动力学表征而收到关注。
三、模型架构
1.GCN
图卷积网络是一个学习图结构数据表示的通用的、有效框架。各种GCN辩题已经在许多任务上取得了最先进的结果。对于骨架动作识别,用
G
t
=
{
V
t
,
E
t
}
\ G _t ={\lbrace V _t,E _t \rbrace}
Gt={Vt,Et}表示在t的单个帧中的人体骨架图,其中
V
t
\ V _t
Vt表示N个关节节点,
E
t
\ E _t
Et表示骨架的边。节点
v
t
i
\ v _{ti}
vti的邻接集合表示为
N
(
v
t
i
)
=
{
v
t
j
∣
d
(
v
t
i
,
v
t
j
)
≤
D
}
\ N(v _{ti})={\lbrace v _{tj} | d(v _{ti},v _{tj}) \leq D\rbrace}
N(vti)={vtj∣d(vti,vtj)≤D},其中
d
(
v
t
i
,
v
t
j
)
\ d(v _{ti},v _{tj})
d(vti,vtj)表示从节点
v
t
j
\ v _{tj}
vtj到
v
t
i
\ v _{ti}
vti的最短距离。图标签函数
l
:
V
t
→
{
1
,
2
,
.
.
.
,
K
}
\ l:V _t \to {\lbrace 1,2,...,K \rbrace}
l:Vt→{1,2,...,K}表示为分配标签
{
1
,
2
,
.
.
.
,
K
}
\ {\lbrace 1,2,...,K \rbrace}
{1,2,...,K},对每个图节点
v
t
i
∈
V
t
\ v _{ti}\in V _t
vti∈Vt,可以将节点
v
t
i
\ v _{ti}
vti的邻居集
N
(
v
t
i
)
\ N(v _{ti})
N(vti)划分为固定数量的K个子集。图卷积的表达式如下:
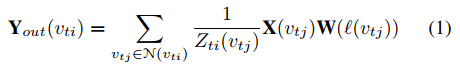
其中
X
(
v
t
j
)
\ X(v _{tj})
X(vtj)表示为
v
t
j
\ v _{tj}
vtj的特征。
W
(
⋅
)
\ W( \cdot )
W(⋅)是一个权值函数,从K个权重中分配一个以标签
l
(
v
t
i
)
\ l(v _{ti})
l(vti)为索引的权值。
Z
t
i
(
v
t
j
)
\ Z _{ti}(v _{tj})
Zti(vtj)是对应子集的个数,用于规范化特征表示。
Y
o
u
t
(
v
t
i
)
\ Y _{out}(v _{ti})
Yout(vti)表示节点
v
t
i
\ v _{ti}
vti的图卷积的输出数据。根据邻接矩阵,式1可以表示为:
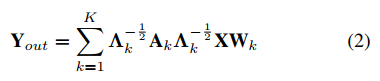
其中
A
k
\ A _k
Ak是标签
k
∈
{
1
,
2
,
.
.
.
,
K
}
\ k \in {\lbrace 1,2,...,K \rbrace}
k∈{1,2,...,K}在空间配置上的邻接矩阵。
Λ
k
i
i
=
∑
j
A
k
i
j
\ \Lambda {^{ii}_k}= \sum _j A {^{ij} _k}
Λkii=∑jAkij是一个对角矩阵。
2.注意增强图卷积LSTM
对于序列建模,大量研究表明,LSTM作为RNN的变体,在建模长时间依赖方面具有惊人的能力。采用各种基于LSTM的模型来学习骨架序列的时间动力学。但是,由于LSTM的全连接操作,在骨架动作识别中具有忽略空间相关性的局限性。相比于LSTM,AGC-LSTM不仅可以捕获在空间配置和时间动态中的判别特征,还可以扩展时空域的相关联关系。
类似LSTM,AGC-LSTM也包括三个们,一个输出门
i
t
\ i _t
it,一个记忆门
f
t
\ f _t
ft,还有一个输出门
o
t
\ o _t
ot。这些门都包含了图卷积操作。AGC-LSTM的输入
X
t
\ X _t
Xt,隐藏状态
H
t
\ H _t
Ht和细胞记忆
C
t
\ C _t
Ct是图结构数据,具体AGC-LSTM的架构图如下图3。由于AGC-LSTM图卷积操作,细胞记忆
C
t
\ C _t
Ct和隐藏状态
H
t
\ H _t
Ht可以表现出时间动态,并包含空间结构信息。AGC-LSTM单元可以表示为

其中
∗
g
\ \ast g
∗g表示为图卷积操作,
⨀
\ \bigodot
⨀为哈达玛积。
σ
(
⋅
)
\ \sigma(\cdot)
σ(⋅)表示sigmoid激活函数。
u
t
\ u _t
ut表示调制输入。
H
^
t
\ \hat H _t
H^t是一个中间隐藏状态。
W
x
i
∗
g
X
t
\ W _{xi}*g X _t
Wxi∗gXt表示
X
t
\ X _t
Xt和
W
t
i
\ W _{ti}
Wti的图卷积,可以写成式1。
f
a
t
t
(
⋅
)
\ f _{att}(\cdot)
fatt(⋅)表示可以选择关节节点的判别信息的注意力网络,而
f
a
t
t
(
H
^
t
)
\ f _{att}(\hat H _t)
fatt(H^t)和
H
^
t
\ \hat H _t
H^t的和作为输出目标,在保持空间信息的完整性的前提下,增强关键节点的信息,并且不削弱其他无关节点的信息。
该注意网络采用软注意机制对关键关节进行自适应关注,该机制能够自动度量关节的重要性。空间注意网络事宜图如图4所示。AGC-LSTM网络的中间隐藏状态
H
^
t
\ \hat H _t
H^t包括大量空间信息和时间动态信息,有助于指导关键节点的选择。这里将所有节点的信息聚合为查询特征:
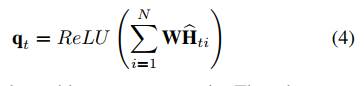
其中
W
\ W
W是学习参数矩阵,所有节点的注意分数表示为:
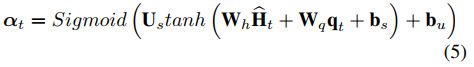
其中
α
t
=
(
α
t
1
,
α
t
2
,
.
.
.
,
α
t
N
)
\ α _t=(α _{t1},α _{t2},...,α _{tN})
αt=(αt1,αt2,...,αtN),
U
s
\ U _s
Us,
W
h
\ W _h
Wh,
W
q
\ W _q
Wq都是学习参数矩阵。
b
s
\ b _s
bs,
b
u
\ b _u
bu为偏量。由于存在多个关键节点的可能性,本文使用的是sigmoid激活函数。节点
v
t
i
\ v _{ti}
vti的隐藏状态
H
t
i
\ H _{ti}
Hti可以表示为
(
1
+
α
t
i
)
⋅
H
^
t
i
\ (1+α _{ti}) \cdot \hat H _{ti}
(1+αti)⋅H^ti。注意力增强隐藏状态
H
t
\ H _t
Ht将会输出到下一个AGC-LSTM层。注意,在最后一个AGC-LSTM层中,所有节点特征的聚合作为全局特征
F
t
g
\ F ^ g_t
Ftg,聚合节点的加权和作为局部特征
F
t
l
\ F ^ l_t
Ftl。
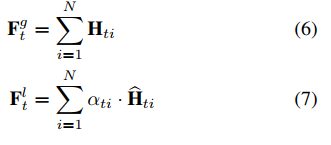
全局特征
F
t
g
\ F ^ g_t
Ftg和局部特征
F
t
l
\ F ^ l_t
Ftl用于预测动作类。


3.AGC-LSTM网络
本文提出一个端到端的注意力增强图卷积LSTM网络用于骨架动作识别。总体架构如图2所示。
节点特征表示:对于骨架序列,使用线性层和LSTM层将每个关节的三维坐标映射到高维特征空间。第一个线性层将关节坐标编码为256维的向量作为位置特征
P
t
∈
R
N
×
256
\ P _t \in R ^{N\times 256}
Pt∈RN×256,
P
t
i
∈
R
1
×
256
\ P _{ti} \in R ^{1\times 256}
Pti∈R1×256表示节点i的坐标。由于位置特征
P
t
i
\ P _{ti}
Pti只包含位置信息,因此有利于学习图模型中的空间结构特征。连续帧间帧差特征
V
t
i
\ V _{ti}
Vti可帮助获取AGC-LSTM的动态信息。为兼顾两者的嗯有点,将两种特征串联起来作为一种增强特征来丰富特征信息。然而,位置特征
P
t
i
\ P _{ti}
Pti和连续帧间帧差特征
V
t
i
\ V _{ti}
Vti的特征向量存在尺度方差,这里采用LSTM层来消除两个特征之间的尺度方差:
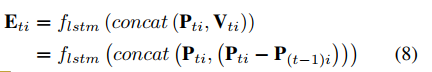
其中
E
t
i
\ E _{ti}
Eti是在t时间节点i的增广特征。非线性层和LSTM是在不同节点间共享的。
时间分层体系结构:在LSTM层之后,序列
{
E
1
,
E
2
,
.
.
.
,
E
T
}
\ {\lbrace E _1,E _2,...,E _T\rbrace}
{E1,E2,...,ET}作为节点特征注入以下GC-LSTM层,其中
E
t
∈
R
N
×
d
e
\ E _t \in R ^{N \times d _e}
Et∈RN×de。提出的三个AGC-LSTM层用来学习空间配置和时间动态。通过CNN中的空间池化,在AGC-LSTM提出了一个时间层次架构用于时间域平均池化,以增加顶部AGC-LSTM层的时间感受域。通过时间层析结构,在AGC-LSTM层的顶层,每次输入的时间接收域从一帧变成一个短时剪辑,对时间动态的感知更加敏感。另外,可以减少计算代价。
学习AGC-LSTM:每个步长的全局特征
F
t
g
\ F ^ g_t
Ftg和局部特征
F
t
l
\ F ^ l_t
Ftl转化为C类评分
o
t
g
\ o ^ g_t
otg和
o
t
l
\ o ^ l_t
otl,其中
o
t
=
(
o
t
1
,
o
t
2
,
.
.
.
,
o
t
C
)
\ o _t=(o _{t1},o _{t2},...,o _{tC})
ot=(ot1,ot2,...,otC)。第i类的预测概率如下:
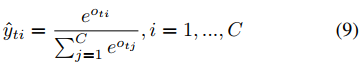
训练师,考虑到AGC-LSTM顶层每个步长的隐藏状态包含一个短期动态,用损失监督模型:
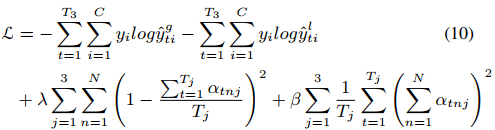
其中
y
\ y
y是真实状态标签,
T
j
\ T _j
Tj表示第j层AGC-LSTM的步长,第三个时间的目标是对不同的关节给予同等的关注,最后一个步长用来限制关键节点的数量。
λ
\ λ
λ和
β
\ β
β是权重衰减系数,需注意的是,只有在最后一个时间步长的
y
^
T
3
g
\ \hat y ^g _{T _3}
y^T3g和
y
^
T
3
l
\ \hat y ^l _{T _3}
y^T3l的概率之和用来预测动作识别的类别。
尽管基于关节的AGC-LSTM网络取得了较好的成果,本文还将在部件级上探讨所提议的模型性能。根据人体身体结构,身体可以被分为几个部分。与基于关节的AGC-LSTM网络相似,首先在线性层和共享LSTM层捕获部分特征。然后将零件特征作为节点表示,输入到三个AGC-LSTM层中,对零件的时空特征进行建模。结果表明,本文的模型在零件级上也能获得较好的性能。基于关节和零件的混合模型如下图所示,可以进一步提高性能。

4、实验
1 数据集
本文采用两个数据集分别是NTU RGB+D和Northwestern-UCLA数据集。
2 实施细节
本文的实验,从每个骨架序列中采样一个固定长度的T作为输入,分别在NTU和Northwestern-UCLA数据集中将T设为100和50。在提出的AGC-LSTM中,每个节点的邻接集合包括节点直接相连的结点,即D=1。与ST-GCN相比较,AGC-LSTM的图标签函数将邻居集划分为K=3个子集:节点本身,向心组和离心组。三个AGC-LSTM层的通道为512。训练时,使用Adam优化函数来优化网络。采用概率为0.5的Dropout避免两个数据集的或拟合,同时设置两个权重衰减系数为0.01和0.001.初始学习率设置为0.0005,并通过每20个迭代乘以0.1来降低,两个数据集的批量大小为别人64和30。
3 结果和比较
本节对提出的网络在两个数据集中进行分析,并与一些相关其他技术比较。
1、在NTU上的比较
2、Northwestern上的比较

3、本文使用的部件级结构在两个数据集上的分析


可视化三个AGC-LSTM层的注意力权值

用混淆矩阵分析的NTU和Northwestern数据集上的实验结果

用混淆矩阵分析的NTU数据集上的误分类结果

总结
本文提出了一个注意力蹭墙图卷积LSTM网络用于骨架动作识别,此网络是第一个尝试将图卷积LSTM用于动作识别的任务。提出的AGC-LSTM网络不仅可以捕获空间配置和时间动态上的判别特征,还能探索空间和时间域的相关关系。因此注意力网络用于增强AGC-LSTM各层关键关节的信息。另外,还提出了时间分层结构用来捕获高级时空语义特征,此方法取得了不错的结果。学习姿态对象关系有助于客服失败案例中提到的限制,未来将尝试将骨骼序列与物体外观相结合,以提高动作识别的性能。















 1008
1008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









