










SC4D: A Sparse 4D Convolutional Network for Skeleton-Based Action Recognition
Skeleton-Based Action Recognition
摘要
本文主要介绍一个新的骨架动作识别方法,将骨架序列视为一个时空点云,并将其化为一个4维网络。提出了一个新的稀疏4D卷积网络(SC4D),直接处理生成4D网络,获得高阶感知。不需要手工设计制作的转换规则,更好的利用了卷积网络的优势,形成了一个简介,通用,健壮的骨架数据框架。另外,通过对空间和时间的同时处理,很大程度上保持了骨架数据的时空一致性,因此具有更好的表达性。同事,在稀疏张量的帮助下,可以有效的执行较少的计算。为验证SC4D的有效性,在NTU-RGB+D和SHEREC数据集中进行验证,并与其他相关方法进行比较。
一、介绍
动作识别由于其在人机交互和视频监督等方面的应用,现在已经成为一个研究热点。近年来,骨架动作识别由于其数据量小、语义信息量大、对复杂环境具有较强的鲁棒性而受到广泛关注。其中,骨架数据一般是一组包含人体关节位置信息的帧序列,表示为摄像机坐标系2D\3D坐标。其完全去除了背景信息,因此更关注人体本身,最近,随着深度学习的成功,基于骨架动作识别的数据驱动的方法成为主流,主要有CNN、RNN和GCN。
总体而言,基于GCN的方法酱骨架数据构成一个时空图,并将其输入到图卷积网络中,具有较高的有效性和性能。但是最近的研究发现,参数化图形拓扑比使用固定的基于人体的图形性能好。这意味着基于先验的图结构并不是基于GCN的骨架数据方法成功的关键,他的成功很大程度上归功于卷积网络并具有良好的泛化性和鲁棒性。因此,基于GCN的方法与CNN方法本质相似,后者尝试设计规则来将骨架数据转换成适合的CNN形式。在这些方法中大致有三个限制:1)由于人为因素,手工设计的规则不能保证是最佳选择;2)骨架数据更固定;3)在以往的骨架数据研究中,位置信息被用作特征,手工特征的规则被用来组织卷积运算。
针对上述三个限制,本文提出了一个新的骨架动作识别方法,将骨架序列作为一个时空点云,并将其体素化为一个4D网格。与图像像素的RGB值类似,每个体素都附加一个特征向量,表示该位置是否有关节以及哪个关节。与以往的工作不同,其不需要人工转换规则,可以很好的利于数据驱动的作用。通过对4D网格进行卷积,权重分担机制不再适用于固定关节结构,避免了对不同样本的不同关节及其邻居的恒定贡献。另外位置信息不包括在特征向量中,对位置平移更有鲁棒性。
与现有的大多数逐帧处理骨架序列的方法不同,直接构造一个4D卷积网络来处理生成的4D网格。从底层到高层分层提取时空特征,在很大程度上保持了骨架数据的时空一致性。为构造4D卷积网络,一个新的方法可以直接将3D卷积核展开为4D。但是,由于在卷积核中添加时间维度需要大量的计算成本。骨架数据是非常稀疏的,本文提出利用稀疏张量和稀疏卷积来减少骨架数据的计算代价。其至跟踪4D网格的非空体素,以及位置信息和相关的特征向量,对稀疏体素进行层次化卷积运算,生成相应的稀疏输出,相比密集卷积,可以获得相同的结果,而且效率更高,计算量更少。
此外,为了进一步提高性能,本文提出了三种数据增强技术。第一,建议沿着骨骼插入点,可以利用人体的先验知识,使其更有特色。插入的数量是根据人体骨骼的平均长度来确定的。其次,骨架数据是稀疏的,使用扩张技术来增强空间模式,以减轻识别,新增加的点的值按比例减少,用于区别原来的关节。最后,相比于前两种方法,骨骼信息和运动信息是基于骨骼的动作识别的有效方法。为将以上方法应用于基于体素的方法中,提出将输入从坐标空间通过对三个空间的信息进行多流建模,融合结果,提高性能。
该方法即稀疏4D卷积网络,是骨骼数据的通用框架。为验证本文方法的有效性,在两个使用较为广泛的数据集中进行验证,分别是NTU-RGB+D和SHREC。
本文的主要创新点如下:
1)提出了一个新的骨架动作识别方法,即将骨架数据体素化为一个4D网格并直接传送到一个稀疏4D卷积网络中,提出的框架高效、简洁、鲁棒性强且性能较高;
2)两个数据增强策略,传输数据坐标到两个不同的空间,例如骨骼空间和运动空间,用于更好的识别;
3)与其他技术在两个数据集中进行比较。
二、相关工作
1.骨架动作识别
主要介绍一些骨架动作识别的方法,包括RNN、CNN、GCN等。
2.基于3D点云的感知任务
由于本文是将骨骼数据视为点云,这里介绍一些基于3D点云的感知任务的工作和研究。
三、方法
1、总体架构
图1展示了本文方法的总体架构,骨架数据可以通过动作捕捉设备或视频中的姿态估计算法获得。由图可以看出,首先归一化并体素化到一个4D网格中,然后利用稀疏4D卷积网络对生成的网络进行处理,从4D网络中分层提取语义信息,输出高级特征映射,最后这些特征映射进行全局平均池化并使用softmax分类器进行分类。

2、体素化
原始数据是一系列帧,每一个帧都记录了当前帧中人体关节的笛卡尔积。
{
R
t
,
m
,
n
r
a
w
∈
R
C
c
o
o
r
,
t
,
m
,
n
=
1
,
2
,
.
.
.
,
T
,
M
,
N
}
\ {\lbrace R {_{t,m,n} ^{raw}} \in R ^{C _{coor}},t,m,n=1,2,...,T,M,N\rbrace}
{Rt,m,nraw∈RCcoor,t,m,n=1,2,...,T,M,N}其中T,M,N分别表示在数据采集系统中的帧数,人数和关节数。
C
c
o
o
r
\ C _{coor}
Ccoor默认为3,因为关节展示在一个3D坐标内。
在一个4D网格中体素化这些关节坐标相当于基于4D网格坐标系中为这些关节计算新坐标。首先,本文在每个关节中添加时间坐标,例如
R
t
,
m
,
n
r
a
w
∈
R
3
→
R
t
,
m
,
n
4
d
\ R {_{t,m,n} ^{raw}} \in R ^3 \rightarrow R {_{t,m,n} ^{4d}}
Rt,m,nraw∈R3→Rt,m,n4d。4D坐标系的维数的默认顺序是时间-x-y-z。时间坐标设为帧的索引。
然后对归一化坐标从0到网格大小范围,本文使用
S
∈
R
4
\ S \in R^4
S∈R4表示网格形状,例如
S
=
[
32
,
32
,
32
,
32
]
\ S=[32,32,32,32]
S=[32,32,32,32]。
S
(
i
)
\ S(i)
S(i)表示网格坐标维数,最大为4。
R
t
,
m
,
n
4
d
\ R {_{t,m,n} ^{4d}}
Rt,m,n4d归一化到
R
t
,
m
,
n
n
o
r
\ R {_{t,m,n} ^{nor}}
Rt,m,nnor,表示为:
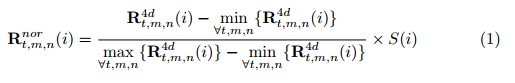
最后,由于坐标是整数,因此4D网格中关节的最终坐标
R
t
,
m
,
n
j
p
t
\ R {_{t,m,n} ^{jpt}}
Rt,m,njpt表示为
R
t
,
m
,
n
j
p
t
=
f
l
o
o
r
(
R
t
,
m
,
n
n
o
r
+
0.5
)
\ R {_{t,m,n} ^{jpt}}=floor(R {_{t,m,n} ^{nor}}+0.5)
Rt,m,njpt=floor(Rt,m,nnor+0.5),其中floor表示向下舍入。
3、特征表示
体素化后,不难得知所有关节的位置在4D网格中,现在给每个关节附加一个特征向量来识别它,在 R t , m , n j p t \ R {_{t,m,n} ^{jpt}} Rt,m,njpt中附加一个特征向量 F t , m , n j p t ∈ R C f e a \ F {_{t,m,n} ^{jpt}} \in R ^{C _{fea}} Ft,m,njpt∈RCfea。本文提出三种策略,第一个是将关节所占的体素特征设为1,其他设为0。但是这种策略无法判断哪个关节占用了当前体素,从而导致了关节语义信息的丢失。第二种策略是 C f e a = M + N \ C _{fea}=M+N Cfea=M+N,第一个M元素构造了one-hot向量,表示当前体素是否被第M个人的关节所占据。类似,最后一个N元素表示第n个关节,公式表示为 F t , m , n j p t ( i ) = I { i = = m ∣ ∣ i = = M = n } \ F {_{t,m,n} ^{jpt}} (i)=I{\lbrace i==m||i==M=n\rbrace} Ft,m,njpt(i)=I{i==m∣∣i==M=n},其中 i = 1 , 2 , . . . , C f e a \ i=1,2,...,C _{fea} i=1,2,...,Cfea, ∣ ∣ \ || ∣∣表示为或。若表达式为真,则 I { e x p r e s s i o n } = 1 \ I{\lbrace expression\rbrace}=1 I{expression}=1,否则为0。然后这种策略不能判断多人的关节落入同一体素的情况。第三种策略为 C f e a = M N \ C _{fea}=MN Cfea=MN,如果现有体素是第m个人的第n个关节,则 F t , m , n j p t ( i ) = 1 \ F {_{t,m,n} ^{jpt}} (i)=1 Ft,m,njpt(i)=1,否则为0, F t , m , n j p t ( i ) = I { i = = ( n + m × N ) \ F {_{t,m,n} ^{jpt}} (i)=I{\lbrace i==(n+m \times N)} Ft,m,njpt(i)=I{i==(n+m×N)。第三种策略可以适用于多种情况,但是需更大数据量,本文选择第三种策略。
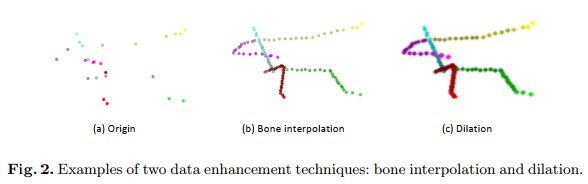
4、数据增强
人体关节的数量通常较少,本文提出两种空间特征增强技术来增强局部模式,如图2所示。第一个策略是沿着人体骨骼插入点,被定义为人体的自然连接,且人体骨骼笔关节要少一个。例如,图4展示了两个数据集的关节和骨骼,首先,本文计算数据集中每个骨头的平均长度,长度最短的骨骼被定义为基本骨骼,这意味着该骨骼的内插点的数量为1。然后其他骨骼的内插点的数量通过其长度和计本骨骼的长度的倍数决定的。这些点均匀的内插在骨骼的两端关节之间。至于新插补点的特征,有两个端关节特征的加权和计算,权重与起到相应端关节的距离成反比。骨骼的数量表示为
B
=
N
−
1
\ B=N-1
B=N−1。每个骨骼的内插关节的数量,即
J
∈
R
B
×
2
\ J \in R ^{B \times 2}
J∈RB×2,由上述策略进行计算。
J
(
b
)
\ J(b)
J(b)表示第b个骨骼的内插点的数量,其中
b
=
1
,
2
,
.
.
.
,
B
\ b=1,2,...,B
b=1,2,...,B,
B
\ B
B表示骨骼的索引。一个映射
I
∈
R
B
×
2
\ I \in R ^{B \times 2}
I∈RB×2,表示为每个骨骼的两个关节的指数。
I
(
b
,
1
)
\ I(b,1)
I(b,1)和
I
(
b
,
2
)
\ I(b,2)
I(b,2)表示第b个骨骼的两个端关节。内插点的坐标和特征表示为
R
t
,
m
,
b
,
j
i
n
t
e
r
∈
R
4
\ R {_{t,m,b,j} ^{inter}} \in R ^4
Rt,m,b,jinter∈R4和
F
t
,
m
,
b
,
j
i
n
t
e
r
∈
R
C
f
e
a
\ F {_{t,m,b,j} ^{inter}}\in R ^{C _{fea}}
Ft,m,b,jinter∈RCfea。
给定
R
t
,
m
,
n
j
p
t
\ R {_{t,m,n} ^{jpt}}
Rt,m,njpt和
F
t
,
m
,
n
j
p
t
\ F {_{t,m,n} ^{jpt}}
Ft,m,njpt,内插点的坐标和特征可表示为:
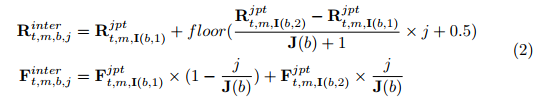
第二个策略是空间扩张,本文根据扩张数,将一个点的坐标沿其所有空间维度展开。使用1D数据作为例子,假设位置2有一个点,用扩张数1将其扩张后,位置1,2,3有三个点。当在一维上进行扩张时,其他维度的坐标保持不变。新扩张点的特征和原始点一样,但被比例尺所分割,比例尺和新扩张的点到原点的距离成反比。给定一个扩张值
∑
\ \sum
∑,一个人在一个坐标系中沿着坐标尺寸c所增加的点数目
D
c
=
2
∑
N
′
\ D _c=2\sum N'
Dc=2∑N′。
c
∈
{
2
,
3
,
4
}
\ c \in {\lbrace 2,3,4\rbrace}
c∈{2,3,4},由于扩张只沿着空间维度进行。
N
′
\ N'
N′表示原始点的数量。扩张点的坐标和特征表示为
R
t
,
m
,
c
,
d
d
i
l
∈
R
4
\ R {_{t,m,c,d} ^{dil}} \in R ^4
Rt,m,c,ddil∈R4和
F
t
,
m
,
c
,
d
d
i
l
∈
R
C
f
e
a
\ F {_{t,m,c,d} ^{dil}}\in R ^{C _{fea}}
Ft,m,c,ddil∈RCfea,其中
d
=
1
,
2
,
.
.
.
\ d=1,2,...
d=1,2,...,
D
c
\ D _c
Dc表示新扩张点沿坐标维数c的索引。给定
R
t
,
m
,
n
j
p
t
\ R {_{t,m,n} ^{jpt}}
Rt,m,njpt和
F
t
,
m
,
n
j
p
t
\ F {_{t,m,n} ^{jpt}}
Ft,m,njpt,然后进行计算:
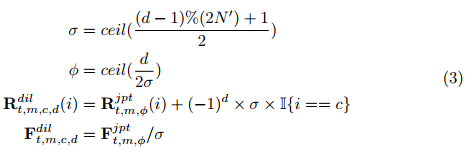
其中
i
=
1
,
2
,
3
,
4
\ i=1,2,3,4
i=1,2,3,4表示扩张点的坐标维度的索引。
σ
∈
{
1
,
2
,
.
.
.
,
∑
}
\ \sigma \in {\lbrace 1,2,...,\sum \rbrace}
σ∈{1,2,...,∑}表示从新扩张点到原始点的距离。
ϕ
∈
{
1
,
2
,
.
.
.
,
N
}
\ \phi \in {\lbrace1,2,...,N\rbrace}
ϕ∈{1,2,...,N}表示当前扩张步骤中对应原始点的指数。

5、密集卷积vs稀疏卷积
体素化和数据增强后,移出相同体素的重复点。本文只需在遍历点时保留第一个点,现在原始骨架关节的原始坐标转换为4d网格
R
n
i
n
∈
R
4
\ R {_n ^{in}} \in R ^4
Rnin∈R4的坐标向量和相应特征向量
F
n
i
n
∈
R
C
f
e
a
\ F {_n ^{in}} \in R ^{C _{fea}}
Fnin∈RCfea,其中
n
=
1
,
2
,
.
.
.
,
N
i
n
\ n=1,2,...,N _{in}
n=1,2,...,Nin,
N
i
n
\ N _{in}
Nin表示执行数据增强技术和去除重复后的总点数。最重要的是问题是,怎么进行神经网络处理。这个卷积方法是通过扩展卷积核维度到4来更新传统的3D CNN到4D CNN,这被称为密集卷积。具体的就是,创建一个5D张量
F
d
e
n
∈
R
S
(
1
)
×
S
(
2
)
×
S
(
3
)
×
S
(
4
)
×
C
f
e
a
\ F ^{den} \in R^{S_{(1)}\times S _{(2)}\times S _{(3)}\times S _{(4)}\times C ^{fea}}
Fden∈RS(1)×S(2)×S(3)×S(4)×Cfea用于表示一个4D网格,并基于
R
n
i
n
\ R {_n ^{in}}
Rnin和
F
n
i
n
\ F {_n ^{in}}
Fnin。
S
∈
R
4
\ S \in R ^4
S∈R4表示网格形状。
F
d
e
n
\ F ^{den}
Fden可以直接输入到4D CNN。
然而,由于在传统4D网格中大部分元素都为0,所以没有必要对每个元素进行卷积,但是这种方法使计算机和GPU内存浪费严重。因此,本文考虑使用稀疏张量来减少计算,为了稀疏的进行卷积或其他运算,关键是根据输入坐标
R
n
i
n
\ R {_n ^{in}}
Rnin和运算定义,得到一个映射M,来识别哪个输入影响哪个输出。同时,定义输入指标
I
i
n
∈
R
N
i
n
\ I ^{in} \in R ^{N _{in}}
Iin∈RNin,输出指标
I
o
u
t
∈
R
N
o
u
t
\ I ^{out} \in R ^{N _{out}}
Iout∈RNout和权重指标
I
w
e
i
∈
R
N
w
e
i
\ I ^{wei} \in R ^{N _{wei}}
Iwei∈RNwei。然后根据输入
(
R
n
i
n
和
F
n
i
n
)
\ (R {_n ^{in}}和F {_n ^{in}})
(Rnin和Fnin),权值
(
W
(
o
p
t
.
)
)
\ (W _{(opt.)})
(W(opt.)),映射
(
M
)
\ (M)
(M)和运算的定义
(
f
)
\ (f)
(f)。卷积运算,是将输入特征和相应的权值相乘,然后基于M添加到相应的输出特征上。然后基于池化操作,类似最大池化或是全局平均池化,不需要用到权重,将输入特征聚合到一起再基于输出特征之间进行简化。对于批处理归一化和Relu等非空间函数,可以直接对输入特征进行一维密集运算。
6、SC4D
在进行完以上操作之后,现在可以建立一个网络仅仅用于稀疏操作。经过大量实验,构建了基于骨骼的动作识别的稀疏四维卷积网络(SC4D)结构,如图3。所有层都是用稀疏操作构建的,一共有9个稀疏卷积层。每个稀疏卷积附加一个稀疏批处理归一化层和一个稀疏ReLu层。第一层的卷积核为1,其他为K。滤波器的数量分别为
C
、
C
、
2
C
、
4
C
、
4
C
、
8
C
、
8
C
、
8
C
、
8
C
\ C、C、2C、4C、4C、8C、8C、8C、8C
C、C、2C、4C、4C、8C、8C、8C、8C。这两个K和C可以调整,来调节模型大小和性能。第一个稀疏卷积层作为嵌入层,将one-hot特征嵌入到特征空间中。除第一个卷积外,残差连接为每个卷积添加。在第2、3、5、7个卷积层之后添加稀疏最大池化层,在所有维度上,最大池化的步幅为2。如果输入网格的尺寸太小,前几个池化层将被删除来保存分辨率。最后加入一个稀疏全局平均池化层和一个稀疏全连接层进行预测。Dropout在全连接层之前使用,以避免过拟合。

7、多流框架
先前的方法,除了位置信息外,骨骼数据中的骨骼信息和运动信息也有助于动作识别。这里,本文将骨骼数据从坐标空间转换为骨骼空间和运动空间,并利用这两个信息。对于骨骼信息,给定原始空间的关节坐标
R
t
,
m
,
n
r
a
w
∈
R
3
\ R {_{t,m,n} ^{raw}} \in R ^3
Rt,m,nraw∈R3,本文首先计算骨骼空间对应的原始坐标
R
t
,
m
,
b
b
r
a
w
∈
R
3
\ R {_{t,m,b} ^{braw}} \in R ^3
Rt,m,bbraw∈R3:
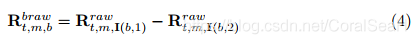
其中
b
=
1
,
2
,
.
.
.
,
B
\ b=1,2,...,B
b=1,2,...,B,映射
I
∈
R
B
×
2
\ I \in R ^{B\times 2}
I∈RB×2记录每个骨骼的两个端关节的指数。然后与本章第二部分介绍的
R
t
,
m
,
n
r
a
w
\ R {_{t,m,n} ^{raw}}
Rt,m,nraw进行体素化的过程相似,将
R
t
,
m
,
b
b
r
a
w
\ R {_{t,m,b} ^{braw}}
Rt,m,bbraw体素化为基于骨骼空间的4D网格,得到稀疏的骨骼空间坐标向量
R
t
,
m
,
b
b
o
n
e
\ R {_{t,m,b} ^{bone}}
Rt,m,bbone和相应的特征向量
F
t
,
m
,
b
b
o
n
e
\ F {_{t,m,b} ^{bone}}
Ft,m,bbone。
F
t
,
m
,
b
b
o
n
e
\ F {_{t,m,b} ^{bone}}
Ft,m,bbone与
R
t
,
m
,
n
j
p
t
\ R {_{t,m,n} ^{jpt}}
Rt,m,njpt一样。
原始坐标的运动空间
R
r
,
m
,
n
m
r
a
w
∈
R
3
\ R {_{r,m,n} ^{mraw}} \in R ^3
Rr,m,nmraw∈R3表示为:
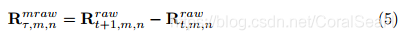
其中
τ
=
1
,
2
,
.
.
.
,
T
−
1
\ \tau =1,2,...,T-1
τ=1,2,...,T−1。这也是体素化到一个基于运动空间的4D网格,并得出
R
τ
,
m
,
n
m
o
t
i
o
n
\ R {_{\tau,m,n} ^{motion}}
Rτ,m,nmotion和
F
τ
,
m
,
n
m
o
t
i
o
n
\ F {_{\tau,m,n} ^{motion}}
Fτ,m,nmotion。骨骼信息和运动信息都是用两个与SC4D结构相同的附加网络建模的。将三个流的softmax评分取平均值,得到最终预测结果。
4、实验
1、数据集
本文使用NTU-RGB+D和SHREC两个数据集,并进行不同实验,验证本文方法的可行性。
2、消融实验
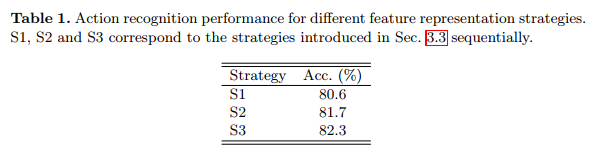
本文首先在NTU-RGB+D数据集对引入的特征表示策略进行验证。首先更新C3D网络到C4D网络,只需要简单的扩展内核的维数。由于GPU内存有限,本文这是网格尺寸为16,基本通道的数量设置为16,C4D中8个卷积层的输出通道为16、32、64、64、128、128、128,如表1显示了三种策略的结果,其中S3的性能比预期的好。
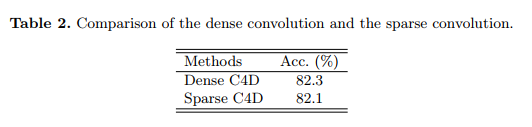
然后,本文使用密集卷积代替稀疏卷积,为保持公平,而不是使用最后的SC4D。本文使用同样的没有稀疏操作的C4D。如图2,使用的密集C4D只比稀疏C4D好一点。但是稀疏C4D在很大程度上减少计算代价。对于密集C4D,需要4个TITANXP GPU进行训练,但对于稀疏C4D,仅只需GPU的十分之一的计算。
由于使用稀疏卷积可以节省大量的GPU内存,本文使用如图3的网络架构,即SC4D进行实验。与稀疏C4D,残差连接可连接到每一层,并在开头添加特征嵌入层,过滤器的基本数量设为32,即C=32。基本核的大小为3,即K=3。使用这些指数,SC4D比稀疏C4D性能更好。然后本文研究了网格大小的影响,结果如表3。

影响模型性能的两个最重要因素是核大小和滤波器的数量,结果如表4。

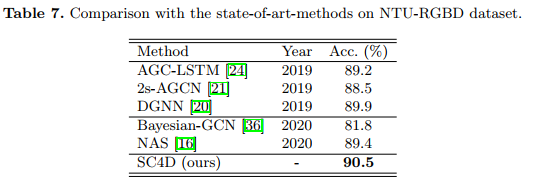
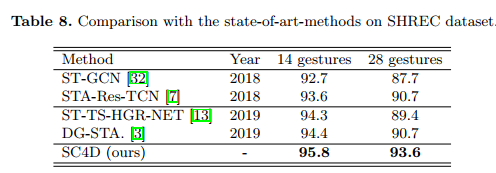
3、与SOTA比较
在两个数据集中进行比较。















 3263
3263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









