







Scan渐进式扫描原理
概述
由于Redis是单线程再处理用户的命令,而Keys命令会一次性遍历所有key,于是在命令执行过程中,无法执行其他命令。这就导致如果Redis中的key比较多,那么Keys命令执行时间就会比较长,从而阻塞Redis,所以推荐使用Scan命令来代替Keys,因为Scan可以限制每次遍历的key数量。
Keys的缺点:
- 1.没有limit,我们只能一次性获取所有符合条件的key,如果结果有上百万挑,那么等待的就是"无穷无尽"的字符串输出
- 2.keys命令是遍历算法,时间复杂度是O(N)。这个命令非常容易导致Redis服务卡顿,要尽量避免在生产环境使用该命令。
Scan命令有两个比较明显的优势:
- 1.Scan命令的时间复杂度虽然也是O(N),但它是分次进行的,不会阻塞线程
- 2.Scan命令提供了count参数,可以控制每次遍历的集合数
可以理解为Scan是渐进式的keys.
大致用法
SCAN命令是基于游标的,每次调用后,都会返回一个游标,用于下一次迭代。当游标返回0时,表示迭代结束。第一次Scan时指定游标为0,表示开启新的一轮迭代,然后Scan命令返回一个新的游标,作为第二次Scan时的游标值继续迭代,一直到Scan返回游标为0,表示本轮迭代结束
通过这个就可以看出,Scan完成一次迭代,需要和Redis进行多次交互。
注意事项
- 1.返回的结果可能会有重复,需要客户端去重复,这点非常重要
- 2.遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的
- 3.单词返回的结果是空的,并不意味着遍历结束,而要看返回的游标值是否为零
Scan使用案例
使用Scan命令,Count参数指定1000,Redis命中几百万Key.
这里会出现一个问题。Scan命令中的Count指定一次扫描多少key,这里指定为1000,
几百万key就需要几千次迭代,即和Redis交互几千次,再加上网络连接中的数据传输
开销和延迟,将会导致耗时比较长。这就需要将Count参数调大后,减少了交互次数。
Count参数越大,Redis阻塞时间也会越长,需要取舍。如果我们极端一点的话,
Count参数和总Key数一致时,Scan命令就和Keys效果一样了
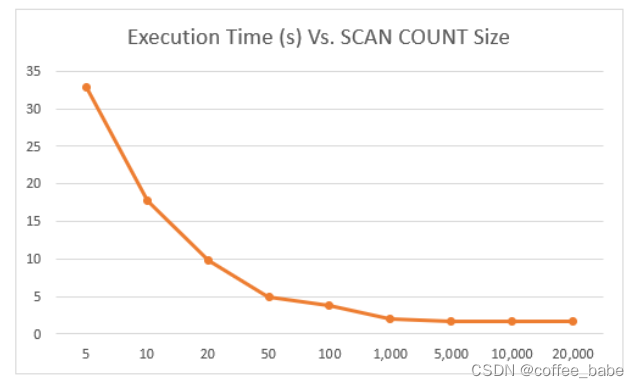
Count大小和Scan总耗时的关系如图所示,
可以发现Count越大,总耗时就越短,不过后面提升就越不明显了
所以推荐的Count大小为1W左右.如果不考虑Redis的阻塞,其实Keys比Scan会快很多,毕竟是一次性处理,省去了多余的交互
Scan原理
Redis使用了Hash表作为底层实现,原因不外乎高校且实现简单。类似于HashMap那样数组+链表的结构.其中第一维的数组大小为2n(n>=0),每次扩容数组长度扩大一倍。Scan命令就是对这个一维数组进行遍历。
每次返回的游标值也都是这个数组的索引,Count参数表示遍历多少个数组的元素,将这些元素下挂接的符合条件的结果都返回。因为每隔元素下挂接的链表大小不同,所以每次返回的结果数量也就不同。
127.0.0.1:6379> keys *
1) "db_number"
2) "key1"
3) "myKey"
127.0.0.1:6379> scan 0 MATCH * COUNT 1
1) "2"
2) 1) "db_number"
127.0.0.1:6379> scan 2 MATCH * COUNT 1
1) "1"
2) 1) "myKey"
127.0.0.1:6379> scan 1 MATCH * COUNT 1
1) "3"
2) 1) "key1"
127.0.0.1:6379> scan 3 MATCH * COUNT 1
1) "0"
2) (empty list or set)
如代码所示,SCAN的命令额度遍历顺序是0->2->1->3
这个顺序看起来有些奇怪,把它转换成二进制:00->10->01->11,可以看到这个序列是最高位加1,
普通二进制的加法,是从右往左3相加、进位。而这个序列是从左往右相加、进位的
相关源码:
v = rev(v);
v++;
v = rev(v);
reverse binary iteration算法
Redis Scan命令最终使用的是reverse binnary iteration算法,大概可以翻译为逆二进制迭代。这个算法简单来说就是:
依次从高位(有效位)开始,不断尝试将当前高位设置为1,然后变动更高位为不同组合,依次来扫描整个字典数组
其最大的优势在于,从高位扫描的时候,如果槽位是2^N个,扫描的临近的2个元素都是与2 ^ (N-1)相关的就是说同模的,比如槽位8时,0%4 == 4 % 4, 1 % 4 == 5%4。因此想到其实hash的时候,跟模是很相关的。
比如当整个字典大小只有4的时候,一个元素计算出的整数为5,那么计算它的hash值需要模4,也就是hash(n) == 5 % 4 == 1,元素放在第一个槽位中。当字典进行扩容的时候,字典大小变为8,此时计算hash的时候为 5 % 8 == 5,该元素从1号slot迁移到了5号,1和5是对应的,我们称之为同模或者对应。同模的槽位的元素最容易出现合并或者拆分了。因此在迭代的时候只要及时地扫描这些相关地槽位,这样就不会造成大面积的重复扫描。
迭代时的三种情况
迭代哈希表时,有以下三种情况:
- 1.从迭代开始到结束,哈希表不Rehash
- 2.从迭代开始到结束,哈希表Rehash,但每次迭代,哈希要么不开始Rehash,要么已经结束Rehash
- 3.从依次迭代开始到结束,哈希表在依次或多次迭代中Rehash,即再Rehash过程中,执行Scan命令,这时数据可能只迁移了一部分
第一种情况比较简单。
假设redis的hash表大小为4,第一个游标为0,读取第一个bucket
的数据,然后游标返回2,下次读取bucket 2,依次遍历
第二种情况更复杂。
假设redis的hash表为4,如果rehash后大小变成8.如果如上返回游标
(即返回2),则显示如图所示。
假设bucket 0读取后返回到cursor 2,当客户端再次Scan cursor 2时,hash表已经被rehash,大小翻倍到8,redis计算一个key bucket如下:
hash(key) & (size -1)
即如果大小为4,hash(key) & 11(3),如果大小为8,hash(key) & 111(7).所以当size从4扩大8时,2号bucket中的原始数据会被分散到2(010)和6(110)这两个bucket中。从二进制来看,size为4时,在hash(key)之后,取低两位,即hash(key) & 11,如果size为8,bucket位置为hash(key) & 111,即取低三位,所以不会出现漏掉数据的情况
第三种情况
如果返回游标2时正在进行rehash,则Hash表1的bucket2中的一些数据可能已经rehash到了Hash表2的bucket[2]或bucket[6],那么必须完全遍历哈希表2的bucket2和6,否则可能会丢失数据。Redis全局有两个Hash表,扩容时会渐进式地将表1地数据迁移到表2,查询时程序会先在ht[0]里面查找,如果没找到地话,就会继续到ht[1]里面进行查找
游标计算
Scan命中的游标,其实就是Redis内部地bucket
v |= ~m0 // 将游标v的unmarsked比特都置为1
v = rev(v); // 反转v
// 这个是关键,加1,对一个数加1,其实就是将这个数的低位的连续1变为0
// 然后将最低的一个0变为1,其实就是将最低的一个0变为1
v++;
v= rev(v); // 再次反转,即得到下一个游标值
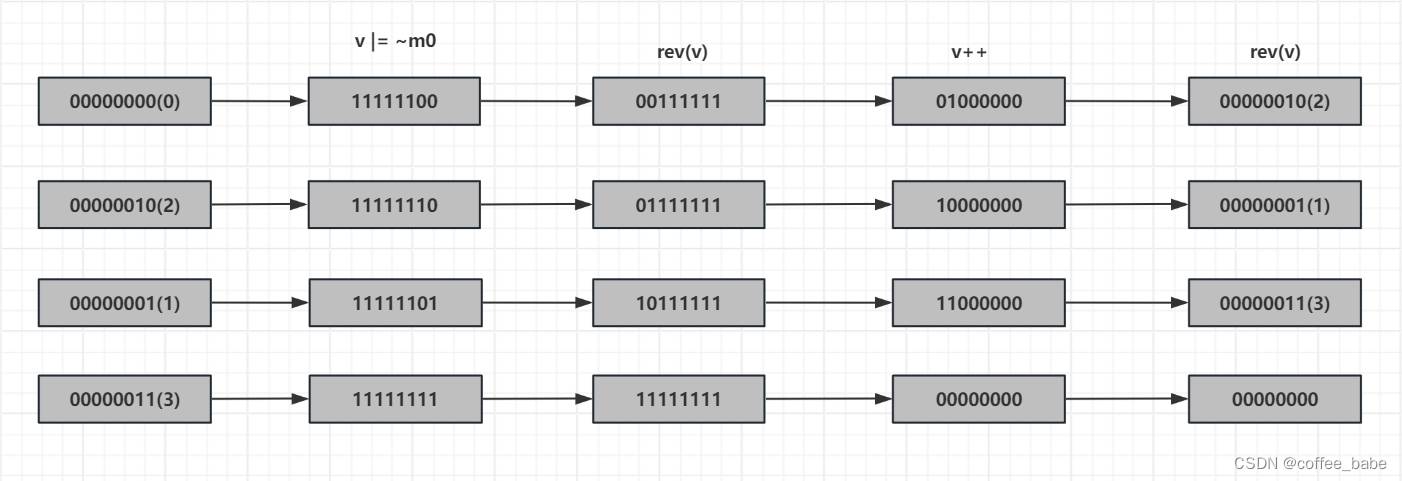
计算过程如图所示.
大小为4时,游标状态转换为0-2-13
当大小为8时,游标转台转换为0-4-2-6-1-5-3-7.
当size由小变大时,所有原来的游标都能在大HashTable中找到对应的位置,并且顺序一致,不会重复读取,也不会被遗漏。
总结:redis在rehash扩容的是时候,不会重复或者漏掉数据。但缩容,可能会造成重复,但不会漏掉数据
缩容处理
之所以会出现重复数据,其实就是为了保证缩容后数据不丢。
假设当前hash大小为8:
- 1.第一次先遍历了bucket[0],返回游标为4
- 2.准备遍历bucket[4],然后此时发生了缩容,bucket[4]的元素也进到了bucket[0]
- 3.但是bucket[0]之前已经被遍历过了,此时会丢失数据吗?
具体计算方法
v = (((v |m0) + 1) & (~m0) | (v & m0)
总结。
- 1.Scan Count参数限制的是遍历的bucket数,而不是限制的返回的元素个数由于不同bucket中的元素个数不同,其中满足条件的个数也不同,所以每次Scan返回元素也不一定相同
- 2.Count越大,Scan总耗时越短,但是单次耗时越大,即阻塞Redis时间变长
- 2.1 推荐Count大小为1W左右
- 2.2 当Count = Redis Key总数时,Scan和Keys效果一致
- 3.Scan采用逆二进制发来计算游标,主要为了兼容Rehash的情况
- 4.Scan为了兼容缩容后不漏掉数据,会出现重复遍历。需要客户端做去重处理
核心就是逆二进制迭代法,比较复杂,而且算法作者也没有具体证明,为什么这样就能实现,只是测试发现没有问题,各种情况都能兼容















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











