







复制
复制拓扑
拥有备库的主-主结构
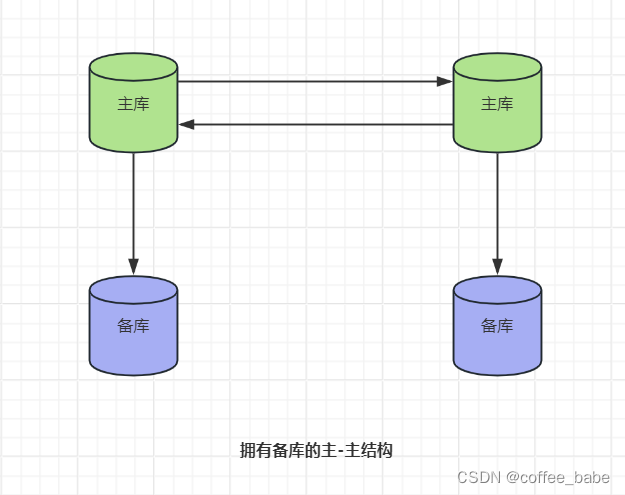
另外一种相关的配置是为每个主库增加一个备库,如图所示。这种配置的优点是增加了冗余,对于不同地理位置的复制拓扑,能够消除站点单点失效的问题。你也可以像平常一样,将读查询分配到备库上。如果在本地为了故障转移使用主-主结构,这种配置同样有用。当主库失效时,用备库来代替主库还是可行的,虽然这有点复杂。同样也可以把备库指向一个不同的主库,但需要考虑增加的复杂度
环形复制
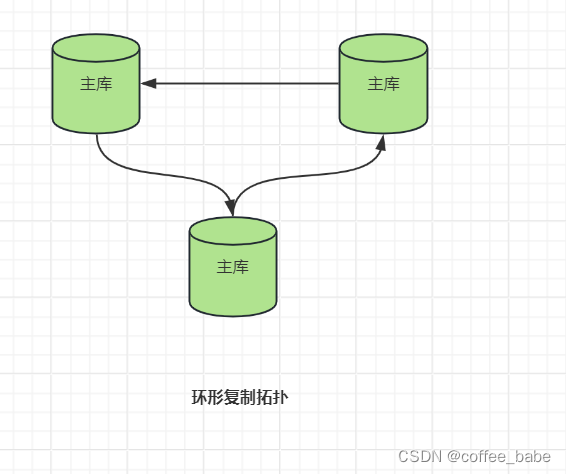
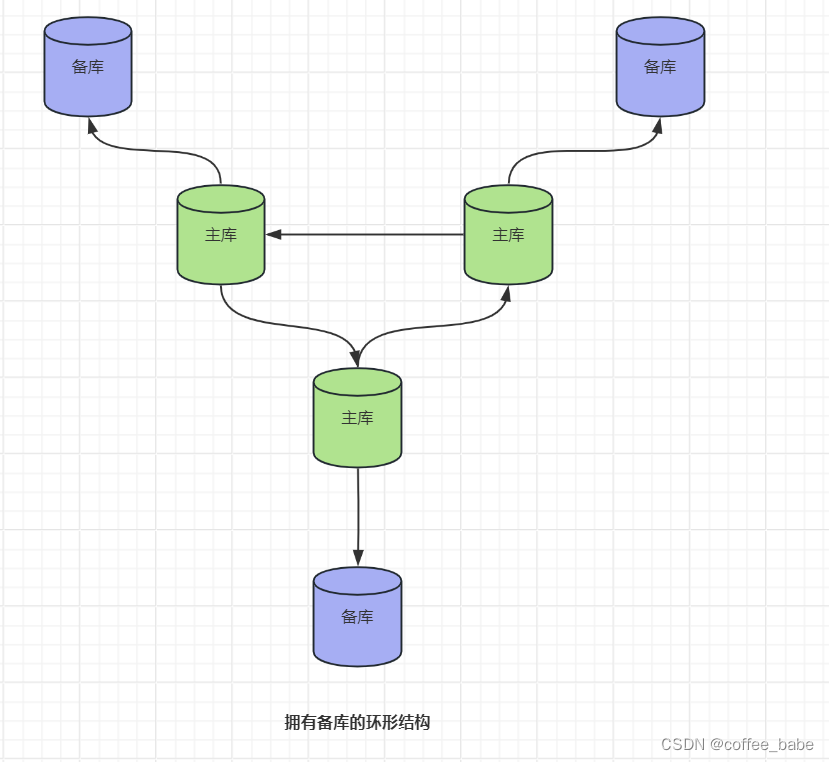
如图所示,双主结构实际上是环形结构的一种特例(也许应该说,是更明智的特例)。环形结构可以有三个或更多的主库。每个服务器都是在它之前的服务器的备库,是它在之后的服务器的主库。这种结构也称为环形复制(circular replication).环形结构没有双主结构的一些优点,例如对称配置和简单的故障转移,并且完全依赖于环上的每一个可用节点,这大大增加了整个系统失效的几率。如果从环中移除一个节点,这个节点发起的时间就会陷入无限循环:它们将永远绕着服务器链循环。总地来说,环形结构非常脆弱,应该尽量避免。可以通过为每个节点增加备库的方式来减少环形复制的风险,如图所示,但这仅仅防范了服务器失效的危险,断电或者其他一些影响到网络连接的问题都可能破坏整个环
主库、分发主库以及备库
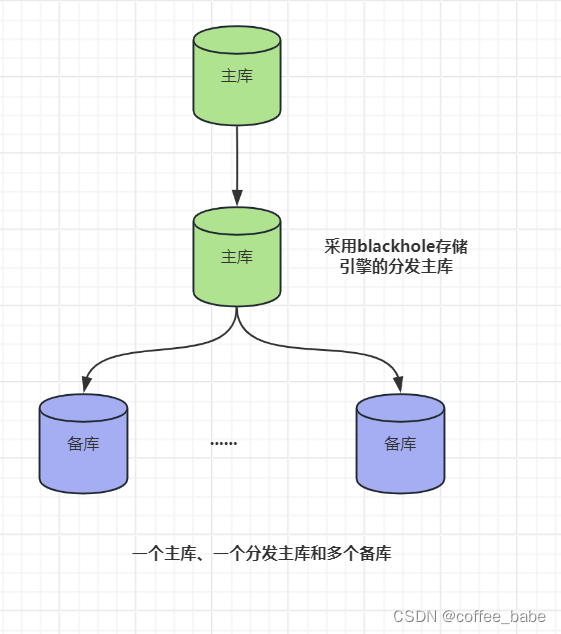
我们之前提到当备库足够多时,会对主库造成很大的负载。每个备库会在主库上创建一个线程,并执行binlog dump命令。该命令会读取二进制日志文件中的数据并将其发送给备库。每个备库都会重复这样的工作,它们不会共享binlog dump的资源。如果有很多备库,并且有大的事件时,例如一次很大的LOAD DATA INFILE操作,主库上的负载会显著上升,甚至可能由于备库同时请求同样的事件而耗尽内存并崩溃。另一方面,如果备库请求的数据不在文件系统的缓存中,可能会导致大量的磁盘检索,这同样会影响主库的性能并增加锁的竞争。因此,如果需要多个备库,一个好办法时从主库移除负载并使用分发主库。分发主库事实上也是一个备库,它的唯一目的就是提取和提供主库的二进制日志。多个备库连接到分发主库,这使原来的主库摆脱了负担。为了避免在分发主库上做实际的查询,可以将它的表修改为blackhole存储疫情,如图所示。很难说当备库数据达到多少时需要一个分发主库。按照通用准则,如果主库接近满负载,不应该为其建立10个以上的备库。如果有少量的写操作,或者只复制其中一部分表,主库就可以提供更多的复制。另外,也不一定只适用一个分发主库。如果需要的话,可以使用多个分发主向大量的备库进行复制,或者使用金字塔状的分发主库。在某些情况下,可以通过设置slave_compressed_protocol来节约一些主库带宽。这对跨数据中心复制很有好处。
还可以通过分发主库实现其他目的,例如,对二进制日志事件执行过滤和重写规则。这比在每个备库上重复进行日志记录、重写和过滤要高效得多。如果在分发主库上使用blackhole表,可以支持更多得备库。虽然会在分发主库执行查询,但其代价非常小,因为blackhole表中没有任何数据。blackhole表得缺点是其存在Bug,例如在某些情况下会忘记将自增ID写入到二进制日志中。所以要小心使用blackhole表。
一个比较常见得问题是如何确保分发服务器上得每个表都是blackhole存储引擎。如果有人在主库创建了一个表并指定了不同的存储引擎呢?确实,不管什么时候,在备库上使用不同的存储引擎总会导致同样的问题。常见的解决方案是设置服务器的storage_engine选项:
storage_engine=blackhole
这只会影响哪些没有指定存储引擎的CREATE TABLE的语句。如果有一个无法控制的应用,这种拓扑结构可能会非常脆弱。可以通过skip_innodb选项禁止InnoDB,将表退化为MyISAM。但你无法禁止MyISAM或者Memory引擎。使用分发主库另外一个主要的缺点是无法使用一个备库来代替主库,因为由于分发主库的存在,导致各个备库与原始主库的二进制日志坐标已经不相同。
树或金字塔形
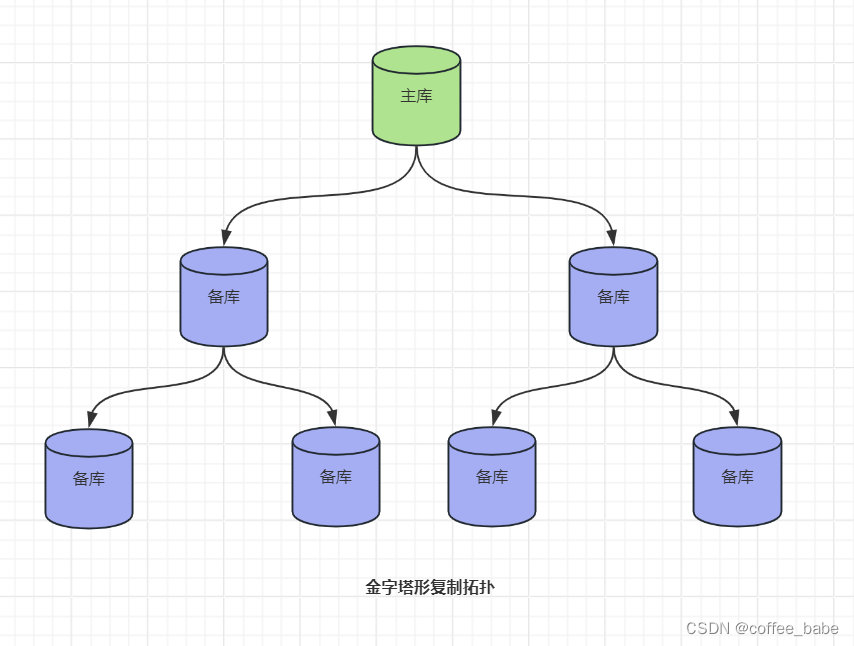
如果正在将主库复制到大量的备库中,不管是把数据分发到不同的地方,还是提供更高的读性能,使用金字塔结构都能够更好地管理,如图所示。
这种设计地好处是减轻了主库地负担,就像前面提到地分发主库一样。它的缺点是中间层出现的任何错误都会影响到多个服务器。如果每个备库和主库直接相连就不会存在这样的问题。同样,中间层次越多,处理故障会更困难、更复杂。
定制的复制方案
MySQL的复制非常灵活,可以根据需要定制解决方案。典型的定制方案包括组合过滤、分发和向不同的存储引擎复制。也可以使用"黑客手段",例如,从一个使用blackhole存储引擎的服务器上复制或复制到这样的服务器上。可以根据需要任意设计。这其中最大的限制是合理地监控和管理,以及所拥有资源额约束(网络带宽、CPU能力等)
选择性复制
为了利用访问局部性原理(locality of reference),并将需要读的工作集驻留在内存中,可以复制少量数据到备库中。如果每个备库只拥有主库的一部分数据,并且将读分配备库,就可以更好地利用备库的内存。并且每个备库也只有主库一部分的写入负载,这样主库的能力更强并能保证备库延迟。
这个方案优点类似水平数据划分,但它的优势在于主库包含了所有的数据集,这意味着无须为了一条写入查询去访问多个服务器。如果读操作无法在备库上找到数据,还可以通过主库来查询。即使不能从备库上读取所有数据,也可以移除大量的主库读负担。
最简单的方法是在主库上将数据划分到不同的数据库里,然后将每个数据库复制到不同的备库上。例如,若需要将公司的每一个部门的数据复制到不同的备库,可以创建名为sales、marketing、procurement等的数据库,每个备库通过选项replicate_wild_do_table选项来限制给定数据库的数据。下面是sales数据库的配置:
replicate_wild_do_table=sales.%
也可以通过一台分发主库进行分发。举个例子,如果想通过一个很慢或者非常昂贵的网络,从一台负载很高的数据库上复制一部分数据,就可以使用一个包含blackhole表和过滤规则的本地分发主库,分发主库可以通过复制过滤不需要的日志。这可以避免在主库上进行不安全的日志选项设定,并且无须传输所有的数据到远程备库
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











