







可扩展性
向外扩展
可以把向外扩展(有时也称为横向扩展或水平扩展)策略划分为三个部分:复制、拆分以及数据分片(sharding).最简单也最常见的向外扩展的方法是通过复制将数据分发到多个服务器上,然后将备库用于读查询。这种技术对于以读为主的应用很有效。它也有一些缺点,例如重复缓存,但如果数据规模有限这就不是问题。另外一个比较常见的向外扩展是工作负载分布到多个"节点"。具体如何分布工作负载是一个复杂的话题。许多大型的MySQL应用不能自动分布负载,就算有也没有做到完全的自动化。后面会讨论一些可能的分布负载的方案,并探讨它们的优点和缺点。
在MySQL架构中,一个节点(node)就是一个功能部件。如果没有规划冗余和高可用性。那么一个节点可能就是一台服务器。如果设计的是能够故障转移的冗余系统,那么一个节点通常可能是下面的某一种:
- 1.一个主——主复制双机结构,拥有一个主动服务器和被动服务器
- 2.一个主库和多个备库
- 3.一个主动服务器,并使用分布式复制块设备(DRBD)作为备用服务器
- 4.一个基于存储区域网络(SAN)的"集群"
大多数情况下,一个节点内的所有服务器应该拥有相同的数据。我们倾向把主——主复制架构作为两台服务器的主动——被动节点
1.按功能拆分

按功能拆分,或者说按职责拆分,意味着不同的节点执行不同的任务。我们之前已经提到了一些类似的实现,。按功能拆分采取的策略比这些更进一步,将独立的服务器或节点分配给不同的应用,这样每个节点只包含它的特定应用所需要的数据。
这里我们显式地使用了"应用"一词。所指的并不是一个单独的计算机程序,而是相关的一系列程序,这些程序可以很容易地批彼此分离,没有关联。例如如果有一个网站,各个部分无须共享数据,那么可以按照网站的功能进行划分。门户网站常常把不同的栏目放在一起;在门户网站,可以浏览网站新闻、论坛,寻求支持和访问知识库等,等等。这些不同功能区域的数据可以放到专用的MySQL服务器中,如图所示。
如果应用很庞大,每个功能区域还可以拥有其专用的Web服务器,但没有专用的数据库服务器这么常见。另一个可能的按功能划分方法是对单个服务器的数据进行划分,并确保划分的表集合之间不会执行关联操作。当必须执行关联操作时,如果对性能要求不高,可以在应用中做关联。虽然有一些变通的方法,但它们有一个共同点,就是每种类型的数据只能在单个节点上找到。这并不是一种通用的分布数据方法,因为很难做到高效,并且相比其他方案没有任何优势。
归根结底,还是不能通过功能划分来无限地进行扩展,因为如果一个功能区域被捆绑到单个MySQL节点,就只能进行垂直扩展。其中的一个应用或者功能区域最终增长到非常庞大时,都会迫使你去寻求一个不同的策略。如果进行了太多的功能划分,以后就很难采用更具扩展性的设计了
2.数据分片

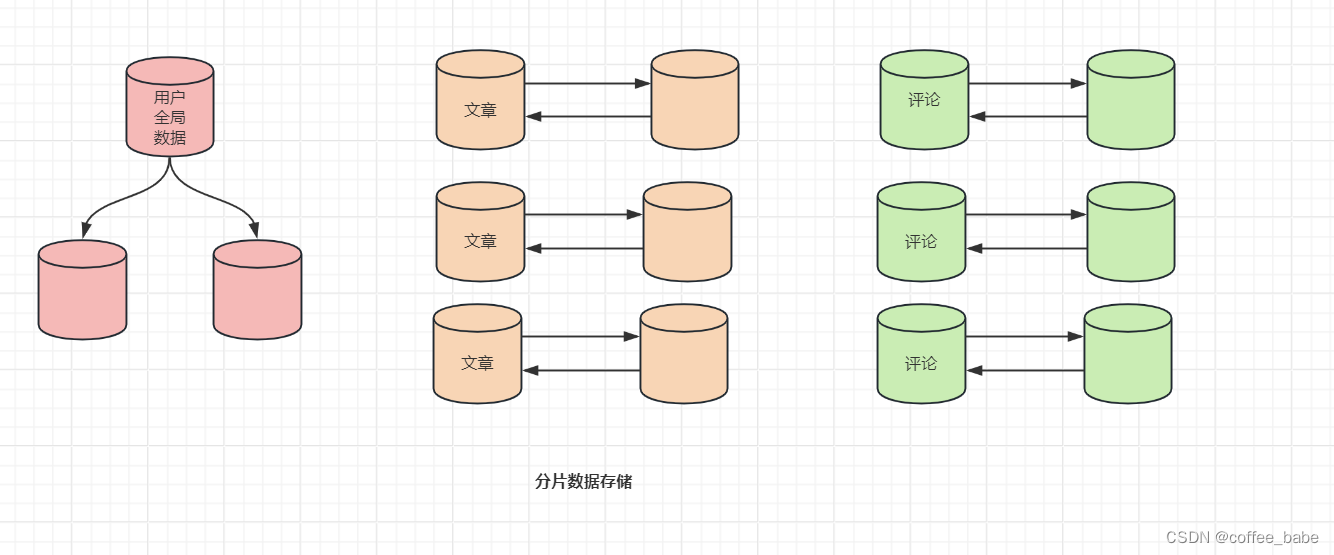
在目前用于扩展大型MySQL应用的方案中,数据分片(分片也被称为"分裂"、“分区”,但是我们使用"分片"以避免混淆。谷歌将它称为"分片",如果谷歌觉得这样称呼合适,我们采取这种称呼也就合适了)是最通用且最成功的方法。它把数据分割成一小片,或者说一块,然后存储到不同的节点中。数据分片在和某些类型的按功能划分联合使用时非常有用。大多数分片系统也有一些"全局的"数据不会被分片(例如城市列表或者登录数据)。全局数据一般存储在单个节点上,并且通常保存在类似memcached这样的缓存里。
事实上,大多数应用只会对需要的数据做分片——通常那些将会增长得非常庞大的数据。假设正在构建的博客服务,预计会有1000万用户,这时候就无须对注册用户进行分片,因为完全可以将所有的用户(或者其中的活跃用户)放到内存中。加入用户数达到5亿,那么就可能需要对用户数据分片。用户产生的内容,例如发表的文章和评论,几乎肯定需要进行数据分片,因为这些数据非常庞大,并且还会越来越多。
大型应用可能有多个逻辑数据集,并且处理方式也可以各不相同。可以将它们存储到不同的服务器组上,但这并不是必需的。还可以以多种方式对数据进行分片,这取决于如何使用它们。
分片技术和大多数应用的最初设计有着显著的差异,并且很难将应用从单一数据存储转换为分片架构。如果在应用设计储器就已经预计到分片,那实现起来就容易得多。许多一开始没有建立分片架构的应用都会碰到规模扩大的情形。例如,可以使用复制来扩展博客服务的读查询,直到它不再奏效。然后可以把服务器划分为三个部分:用户信息、文章,以及评论。可以将这些数据放到不同的服务器上(按功能划分),也许可以使用面向服务的架构,并在应用层执行联合查询,如图显示了从单台服务器到按功能划分的演变。
最后可以通过用户ID来对文章和评论进行分片,而将用户信息保留在单个节点上,如果为全局节点配置一个主——备结构并为分片节点使用主——主结构,最终的数据可能如图所示。如果事先直到应用会扩大到很大的规模,并且清楚按功能划分的局限性,就可以台哦过中间步骤,直接从单个节点升级为分片数据存储。事实上,这种前瞻性可以帮你避免由于粗糙的分片方案带来的挑战。采用分片的应用常会有一个数据库访问抽象层,用以降低应用和分片数据存储之前通信的复杂度,但无法完全隐藏分片。因为相比数据存储,应用通常更了解跟查询相关的一些信息。太多的抽象会导致低效率,例如查询所有的节点,可实际上需要的数据只在单一节点上。分片数据存储看起来像是优雅的解决方案,单很难实现。那为什么要选择这个架构呢?答案很简单:如果想扩展写容量,就必需切分数据。如果只有单台主库,那么不管有多少备库,写容量都是无法扩展的。对于上述缺点而言,数据分片是我们首选的解决方案
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











