







Django ORM性能优化
#1 环境
Python3.7.3
Django==2.0.7
#2 QuerySet优化
#2.1 性能优化1 – select_related
#2.1 select_related()函数
select_related()函数优化QuerySet只针对一对一字段(OneToOneField)/外键字段(ForeignKey)
from django.db import models
class test(models.Model):
name = models.CharField(max_length=100)
class Tag(models.Model):
kk = models.OneToOneField(test,on_delete=models.CASCADE,default="")
name = models.CharField(max_length=100)
class Blog(models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField()
class Author(models.Model):
name = models.CharField(max_length=200)
email = models.EmailField()
class Entry(models.Model):
blog = models.ForeignKey(
Blog,
on_delete=models.CASCADE,
related_name="entryblogs",
related_query_name="entryqueryblogs"
)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateField()
mod_date = models.DateField()
authors = models.ManyToManyField(Author)
n_comments = models.IntegerField()
n_pingbacks = models.IntegerField()
rating = models.IntegerField()
tag = models.OneToOneField(Tag,on_delete=models.CASCADE,default="")
- 标准查找
queryset_entry = models.Entry.objects.all()
for foo in queryset_entry:
foo.blog.name
SQL语句
SELECT "app_entry"."id", "app_entry"."blog_id", "app_entry"."headline", "app_entry"."body_text", "app_entry"."pub_date", "app_entry"."mod_date", "app_entry"."n_comments", "app_entry"."n_pingbacks", "app_entry"."rating", "app_entry"."_order" FROM "app_entry" ORDER BY "app_entry"."_order" ASC; args=()
SELECT "app_blog"."id", "app_blog"."name", "app_blog"."tagline" FROM "app_blog" WHERE "app_blog"."id" = 1; args=(1,)
SELECT "app_blog"."id", "app_blog"."name", "app_blog"."tagline" FROM "app_blog" WHERE "app_blog"."id" = 1; args=(1,)
SELECT "app_blog"."id", "app_blog"."name", "app_blog"."tagline" FROM "app_blog" WHERE "app_blog"."id" = 1; args=(1,)
SELECT "app_blog"."id", "app_blog"."name", "app_blog"."tagline" FROM "app_blog" WHERE "app_blog"."id" = 1; args=(1,)
Entry表中存放外键blog,并且有四条数据,所以在迭代时,会执行4条SQL语句查询
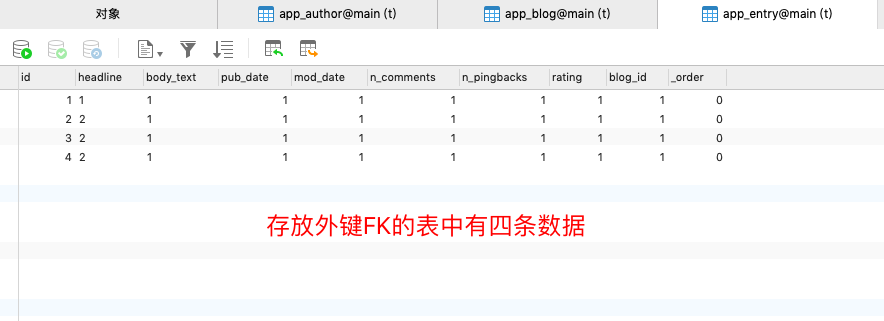

- 使用select_related()优化
queryset_entry = models.Entry.objects.select_related('blog').all()
for foo in queryset_entry:
foo.blog.name
SQL语句:
SELECT "app_entry"."id", "app_entry"."blog_id", "app_entry"."headline", "app_entry"."body_text", "app_entry"."pub_date", "app_entry"."mod_date", "app_entry"."n_comments", "app_entry"."n_pingbacks", "app_entry"."rating", "app_entry"."_order", "app_blog"."id", "app_blog"."name", "app_blog"."tagline" FROM "app_entry" INNER JOIN "app_blog" ON ("app_entry"."blog_id" = "app_blog"."id") ORDER BY "app_entry"."_order" ASC; args=()

由此得出,通过使用 select_related 减少SQL查询的次数来进行优化、提高性能
#2.1.2 select_related()使用
def select_related(self, *fields)
- 不传参数
默认会认为是表中的所有外键,包括多层外键
models.Entry.objects.select_related().all()
- 传参数
传什么参数,就会优化相应的外键,没有传递的参数,不会被优化
关联多层外键,可以使用双下划线__
models.Entry.objects.select_related('blog').all()
models.Entry.objects.select_related('tag__kk').all()
#2.1.3 总结
- select_related主要针一对一和多对一关系进行优化。
- select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
- 可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询。没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
- 也可以通过depth参数指定递归的深度,Django会自动缓存指定深度内所有的字段。如果要访问指定深度外的字段,Django会再次进行SQL查询。
- 也接受无参数的调用,Django会尽可能深的递归查询所有的字段。但注意有Django递归的限制和性能的浪费。
#2.1.4 打印SQL语句
这里使用 logger 打印SQL语句
在setting.py添加以下代码即可在终端看到执行的SQL语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
#2.2 性能优化2 – prefetch_related
prefetch_related()函数优化QuerySet只针对多对多字段(ManyToManyField)
- 标准查找
queryset_entry = models.Entry.objects.all()
for foo in queryset_entry:
foo.authors.all()
SQL语句
SELECT "app_entry"."id", "app_entry"."blog_id", "app_entry"."headline", "app_entry"."body_text", "app_entry"."pub_date", "app_entry"."mod_date", "app_entry"."n_comments", "app_entry"."n_pingbacks", "app_entry"."rating", "app_entry"."tag_id", "app_entry"."_order" FROM "app_entry" ORDER BY "app_entry"."_order" ASC; args=()
SELECT "app_author"."id", "app_author"."name", "app_author"."email" FROM "app_author" INNER JOIN "app_entry_authors" ON ("app_author"."id" = "app_entry_authors"."author_id") WHERE "app_entry_authors"."entry_id" = 1 LIMIT 21; args=(1,)
SELECT "app_author"."id", "app_author"."name", "app_author"."email" FROM "app_author" INNER JOIN "app_entry_authors" ON ("app_author"."id" = "app_entry_authors"."author_id") WHERE "app_entry_authors"."entry_id" = 2 LIMIT 21; args=(2,)
SELECT "app_author"."id", "app_author"."name", "app_author"."email" FROM "app_author" INNER JOIN "app_entry_authors" ON ("app_author"."id" = "app_entry_authors"."author_id") WHERE "app_entry_authors"."entry_id" = 3 LIMIT 21; args=(3,)
SELECT "app_author"."id", "app_author"."name", "app_author"."email" FROM "app_author" INNER JOIN "app_entry_authors" ON ("app_author"."id" = "app_entry_authors"."author_id") WHERE "app_entry_authors"."entry_id" = 4 LIMIT 21; args=(4,)
Entry表中存放外键authors,并且有四条数据,所以在迭代时,会执行4条SQL语句查询

- 使用 prefetch_related()优化
queryset_entry = models.Entry.objects.prefetch_related('authors').all()
for foo in queryset_entry:
foo.authors.all()
SQL语句
SELECT "app_entry"."id", "app_entry"."blog_id", "app_entry"."headline", "app_entry"."body_text", "app_entry"."pub_date", "app_entry"."mod_date", "app_entry"."n_comments", "app_entry"."n_pingbacks", "app_entry"."rating", "app_entry"."tag_id", "app_entry"."_order" FROM "app_entry" ORDER BY "app_entry"."_order" ASC; args=()
SELECT ("app_entry_authors"."entry_id") AS "_prefetch_related_val_entry_id", "app_author"."id", "app_author"."name", "app_author"."email" FROM "app_author" INNER JOIN "app_entry_authors" ON ("app_author"."id" = "app_entry_authors"."author_id") WHERE "app_entry_authors"."entry_id" IN (1, 2, 3, 4); args=(1, 2, 3, 4)
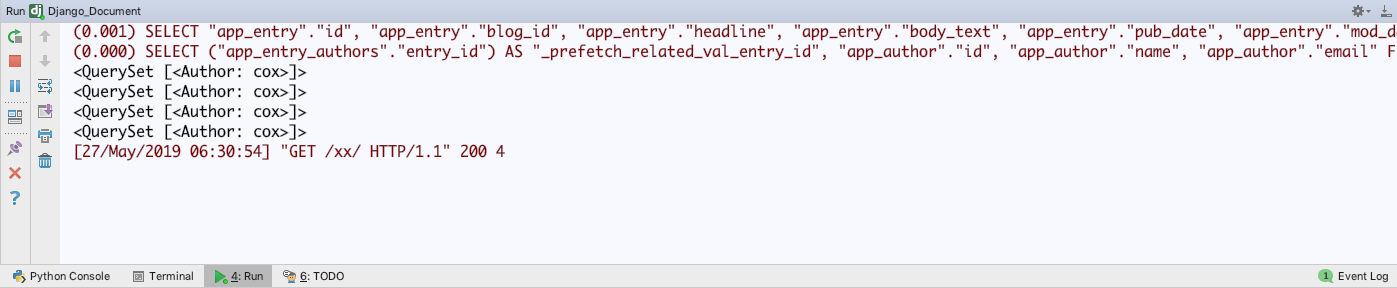
prefetch_related() 的使用和 select_related()相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增量和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi行的结果表.prefetch_related
#2.3 性能优化3 – django F()表达式
F表达式在优化中使用场景如下:
在某个表中存在一个字段,这个字段的用途适用于记录博客访问量,字段会随着访客而自增(+1)
一个F()对象表示一个模型字段或注释的列的值。它可以引用模型字段值并使用它们执行数据库操作,而无需将它们从数据库中拉出到Python内存中。相反,Django使用该F()对象生成一个SQL表达式,该表达式描述了数据库级别所需的操作。
- 普通自增
obj_entry = models.Entry.objects.all().first()
obj_entry.n_comments += 1
obj_entry.save()
在这里,我们 obj_entry.n_comments 将数据库的值从数据库中提取到内存中并使用熟悉的Python运算符对其进行操作,然后将对象保存回数据库。
- 使用F()表达式优化
obj_entry = models.Entry.objects.all().first()
obj_entry.n_comments = F("n_comments") 1
obj_entry.save()
- 虽然看起来像是对实例属性的普通Python赋值,但实际上它是描述数据库操作的SQL构造。obj_entry.n_comments = F(“n_comments”) 1
- 当Django遇到一个实例时F(),它会覆盖标准的Python运算符来创建一个封装的SQL表达式; 在这种情况下,指示数据库增加由…表示的数据库字段 obj_entry.n_comments。
- 无论是什么价值obj_entry.n_comments,Python都不会知道它 - 它完全由数据库处理。所有Python都通过Django的F()类创建SQL语法来引用该字段并描述操作。
- 优点
- 直接在数据库中操作而不是python
- 减少一些操作所需的数据库查询次数
- 注意
F()操作在 obj.save() 后会持续存在
- 如果times的值是1,那么经过n次save()之后,times的值是2
obj_entry = models.Entry.objects.all().first()
obj_entry.n_comments += 1
obj_entry.save() # n_comments == 2
obj_entry.save() # n_comments == 2
obj_entry.save() # n_comments == 2
- 如果times的值是1,那么经过n次save()之后,times的值是1+n,而不是2,就是因为F()操作在 obj.save() 后会持续存在
obj_entry = models.Entry.objects.all().first()
obj_entry.n_comments = F("n_comments") 1
obj_entry.save() # n_comments == 2
obj_entry.save() # n_comments == 3
obj_entry.save() # n_comments == 4
obj_entry.save() # n_comments == 5
#2.4 性能优化4 – 使用唯一的索引列检索单个对象
使用唯一的索引列检索单个对象
>>> entry = Entry.objects.get(id=10)
会比以下更快:
>>> entry = Entry.objects.get(headline="News Item Title")
因为它id是由数据库索引的,并保证是唯一的。
执行以下操作可能非常慢:
>>> entry = Entry.objects.get(headline__startswith="News")
首先,headline没有索引,这将使底层数据库获取更慢。
其次,查找不保证只返回一个对象。如果查询匹配多个对象,它将从数据库中检索并传输所有对象。如果返回数百或数千条记录,这种惩罚可能会很大。如果数据库位于单独的服务器上,那么惩罚将会加剧,其中网络开销和延迟也是一个因素。
#2.5 性能优化5 – 判断queryset是否为空
QuerySet.exists()
效果好于:
len(queryset)
#2.6 性能优化6 – 获取外键数据对应的id
如果只需要外键值,请使用已有对象上的外键值,而不是获取整个相关对象并获取其主键。即做:
entry.blog.id
好于:
entry.blog_id
#2.7 性能优化7 – 批量插入
在可能的情况下创建对象时,请使用该 bulk_create()方法来减少SQL查询的数量。例如:
Entry.objects.bulk_create([
Entry(headline='This is a test'),
Entry(headline='This is only a test'),
])
好于:
Entry.objects.create(headline='This is a test')
Entry.objects.create(headline='This is only a test')
#2.8 性能优化8 – 数据库持久连接
持久连接避免了在每个请求中重新建立与数据库的连接的开销。它们由CONN_MAX_AGE定义连接最大生命周期的参数控制 。可以为每个数据库单独设置。
没有持久化连接,每一个网站的请求都会与数据库建立一个连接。如果数据库不在本地,尽管网速很快,这也将花费20-75ms.
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'xxx',
'USER': 'root',
'PASSWORD': 'root',
'HOST': '127.0.0.1',
'PORT': '3306',
'CONN_MAX_AGE': 600, # 秒
}
}
| CONN_MAX_AGE | 描述 |
|---|---|
| 0(默认) | 保留在每个请求结束时关闭数据库连接的历史行为 |
| 600(正秒数) | 要启用持久连接的秒数 |
| None | 对于无限制的持久连接 |















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









