







DCASE(Detection and Classification of Acoustic Scenes and Events)系列挑战赛包含多个与声音计算相关的子任务,以DCASE2023为例,其包含如下七个与声音计算相关的任务。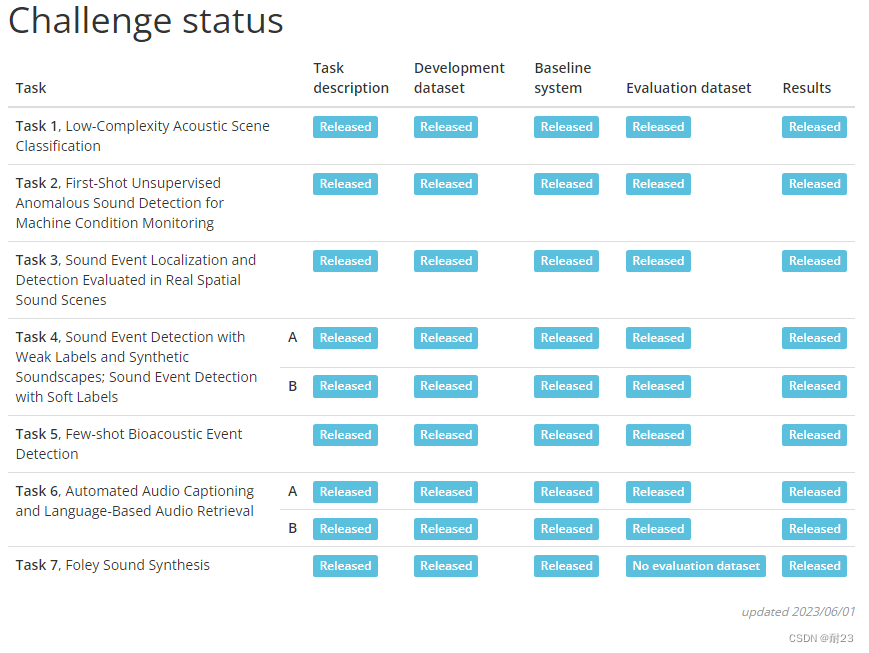
(source:DCASE challenge website)
声音事件检测与定位作为DCASE挑战赛的子任务已经举办多个轮次。
声音事件检测与定位SELD(Sound Event Localization and Detection)指的是,给定多声道音频输入,声音计算模型为每个目标声音类输出一个时间激活轨迹,当轨迹指示活动时,还输出一个或多个相应的空间轨迹。
声音事件检测与定位系统可以用于广泛的机器认知任务,如识别环境类型、定位、在没有视觉输入或是视觉遮挡情况下进行导航、跟踪特定类型的声源、智能家居、场景可视化和声学监测等。
1、任务介绍
SELD任务可以描述为下图,针对给定的多通道声音数据,采用声学计算模型(sound event localization and detection system)同时检测该时序信号中包含的声音事件类型,并在它们出现的时候定位其在空间中的位置(这里估计的是角度azimuth和elevation)。

(source:DCASE challenge website)
2、挑战赛发展历程
DCASE2023(DCASE2023 Challenge - DCASE)是SELD子任务的第5次迭代。前3个挑战是基于模拟的多通道记录,由事件样本库生成,这些样本库包含在不同房间捕获的空间房间脉冲响应(spatial room impulse responses, SRIRs),并混合了在相同位置记录的空间环境噪声。
SELD从2019年开始作为DCASE系列挑战赛的第三个子任务(task3)出现,最初由Tampere University(坦佩雷大学)Audio research group组织;从DCASE2022开始,由Tampere University和SONY共同组织。
SELD模拟数据集的合成过程可描述为下图
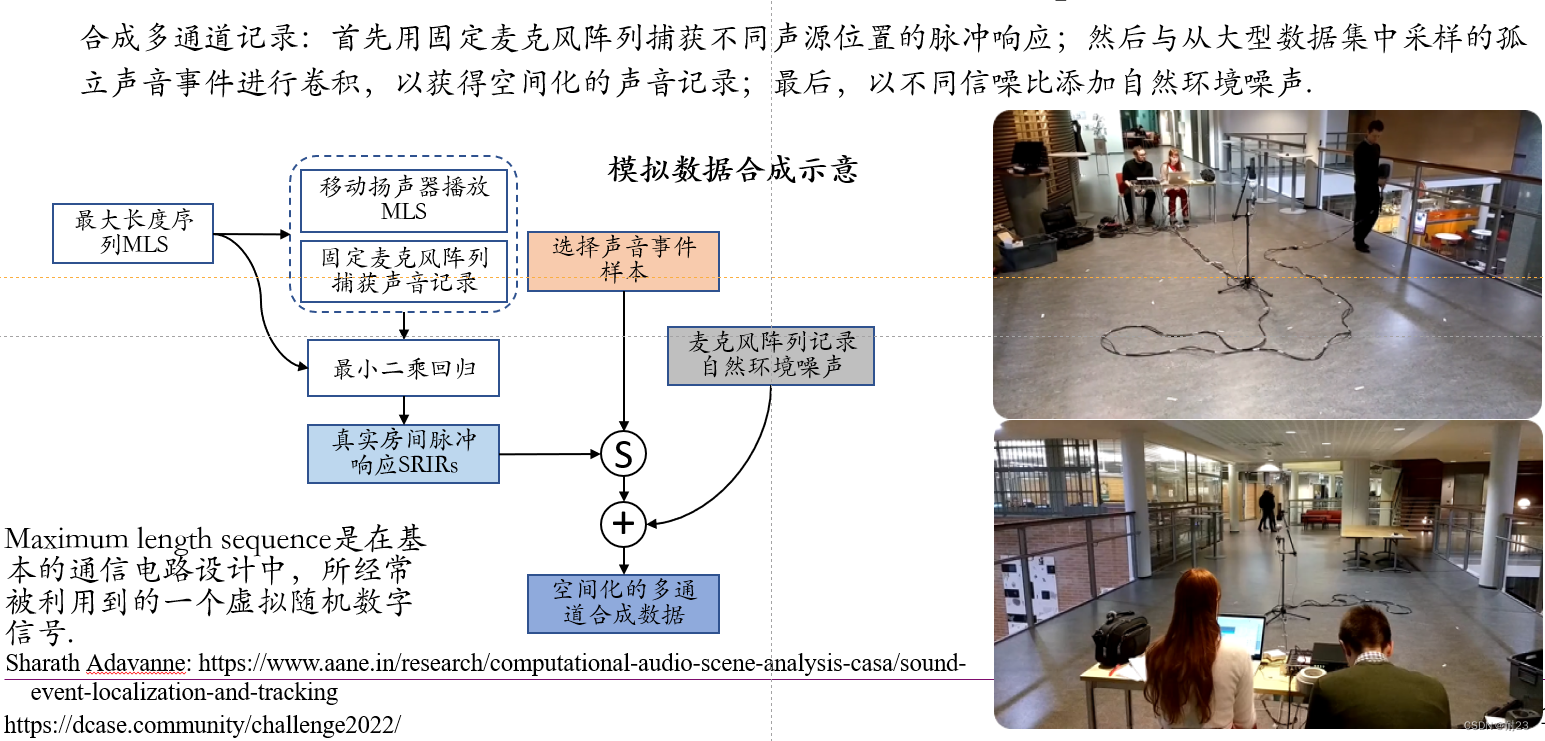
(source:作者自画) ,图中右侧的两幅图展示的是用于空间化声音事件位置的房间脉冲响应记录过程(上),以及真实环境噪声记录过程(下)
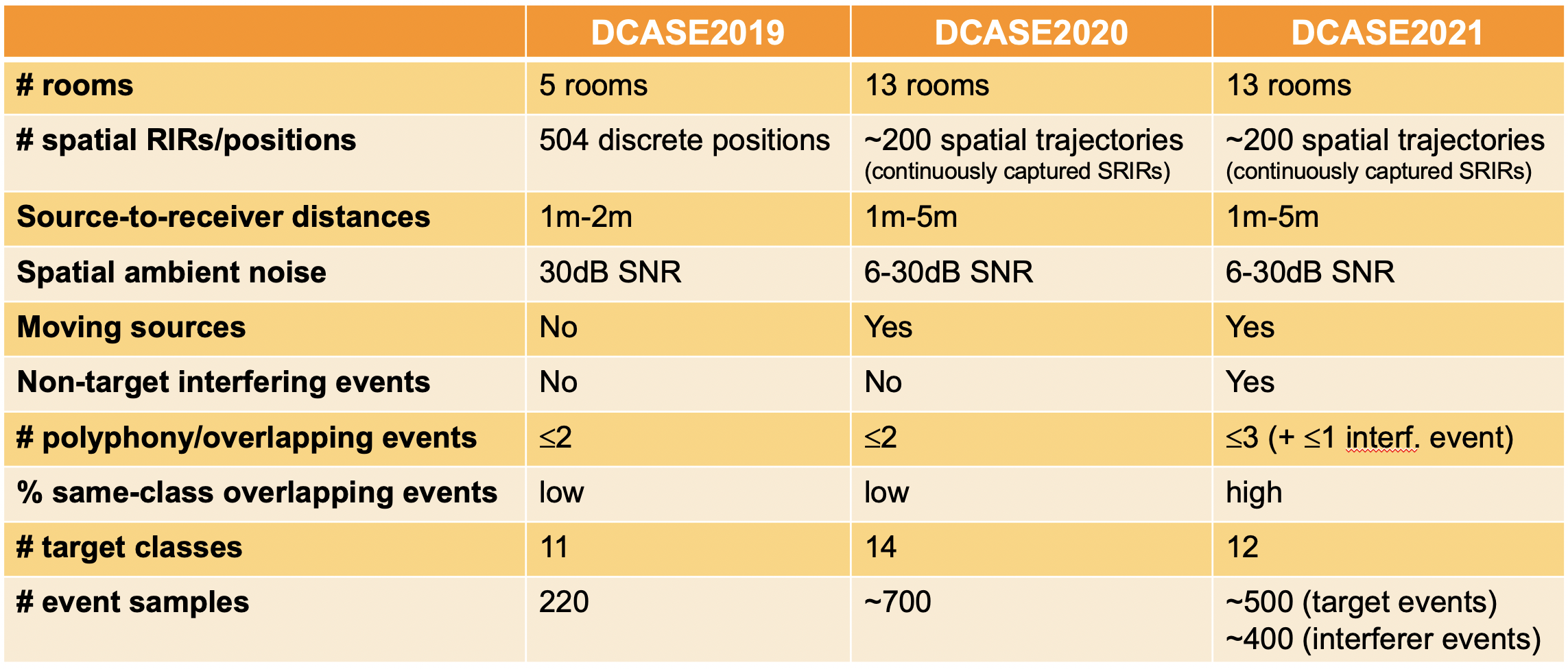
在每一个连续的迭代中,声学条件的复杂性增加,以便使任务更接近现实世界的挑战性条件。下面的表格显示了前3个挑战之间的基本差异
Table 1: Differences between SELD challenges in DCASE2019-2021. (source:DCASE challenge website)
随着相关SELD方法的不断发展,自然向前迈出的一步是在真实空间声音场景记录上测试系统的性能。为了应对该挑战,DCASE2022收集了真实声学场景下记录的多通道声音数据并发布了新一轮的挑战赛,与前几年相比,这一过渡带来了一些变化,其中一些总结如下
Table 2: Differences between previous SELD challenges and the current one.
| DCASE 2019-2021 | DCASE 2022 |
| 在模拟场景记录数据中训练并测试 | 在真实标注场景记录数据中测试 |
| 在由组织者提供的固定尺寸的合成数据集上训练 | 提供了一小部分在真实场景下采集的声音数据用于训练;参与者也可以采用其它训练数据 |
| 在训练阶段,额外的数据是不允许的 | 允许采用额外的数据进行训练 |
| 目标声音事件类别由使用的事件样本库决定 | 目标声音事件类别由真实场景中活动的声音类别组成 |
| 事件的发生是随机的 | 事件的发生取决于场景中的动作与交互 |
| 声音事件的类别,声音事件的密度,声音事件重叠的程度均由数据生成控制 | 声音事件的类别,声音事件的密度,声音事件重叠的程度由真实场景声音决定 |
| 基线方法不能检测两个同类别的重合声音事件 | 基线方法可以检测两个以上重叠的同类别声音事件 |
SELD2023相对于2022而言,同为真实场景下记录的数据且在SELD2022的基础上发布了更多的声音数据,并发布了记录场景下对应的真实360°视频数据,用于社区研究视听融合的声音事件检测与定位。
3、SELD2022描述
用于SELD2022的数据集为Sony-TAu Realistic Spatial Soundscapes 2022 (STARSS22),该数据集是在两个不同的国家(由芬兰坦佩雷大学的音频研究小组(ARG)组织,和日本东京的索尼公司组织)使用类似的设置和注释程序收集的。与前面的挑战一样,数据集以两种空间记录格式(FOA、MIC)发布。
这些录音被组织成一个个录音会话,每个会话都在一个独特的房间里进行。除了少数例外,参与者的分组、声音制作道具和场景都是独特的。在每个会话中捕获多个声音事件的1-5min录音。为了在声音事件的出现、密度、运动和/或空间分布方面实现数据的良好可变性和效率,数据记录情景被松散地剧本化处理过。
在实验记录设备方面,使用高声道数球形麦克风阵列(Eigenmike em32,由mh Acoustics公司提供)捕捉声音场景记录,同时使用与球形阵列记录(Ricoh Theta V)空间对齐的360视频记录。此外,主要声源配备了空间跟踪标记,即在整个录音过程中,都会使用Optitrack Flex 13系统围绕每个场景进行跟踪。所有的场景都是基于人类演员执行某些动作,他们之间以及与场景中的物体进行互动,而动态设计的。
由于演员在场景中制造了大部分声音(但不是全部),他们额外配备了DPA Wireless Go II麦克风,提供主要事件的近距离录音。录音会根据正在进行的场景进行启动和停止,通常持续1~5分钟。所有的麦克风和跟踪设备都会在场景开始前开始录音,然后立即停止。拍手声将启动动作,它将作为参考信号,用于em32录音、理光Theta V视频、DPA无线麦克风录音和Optitrack跟踪器数据之间的同步。
下图展示了SELD2022真实数据记录场景的标注图,

来自360度视频的场景示意帧,EM32生成的空间声学功率图,光学跟踪标记数据,带注释的事件标签,用于可视化验证
总结:有关挑战赛数据集的详细描述可参考挑战赛官网介绍,以及随历届挑战赛发布的挑战赛介绍相关论文。该系列挑战赛都提供了声学计算基线系统,包括对数据的预处理和特征提取等,极大地方便了关联社区在此基础上研究声学计算模型。
可参考资源:
挑战赛介绍:Sound Event Localization and Detection Evaluated in Real Spatial Sound Scenes - DCASE
描述数据集组织和基线系统方面的论文:https://github.com/sharathadavanne/seld-dcase2022

















 2265
2265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









