








K8s 集群巡检
上次发文 K8s 无备份,不运维,文章开篇,插入了一张 K8s 集群巡检的图片,好多小伙伴私信留言,问我要开源地址。由于其通用性不高,大多数公司需要结合自身的架构情况进行不同的巡检,所以我没有开源。
今天发现有小伙伴还在群里讨论,有没有类似的工具/平台,虽然没有开源,我把其关键的 巡检指标 和 后端核心伪代码 分享出来,供各位同行参考。
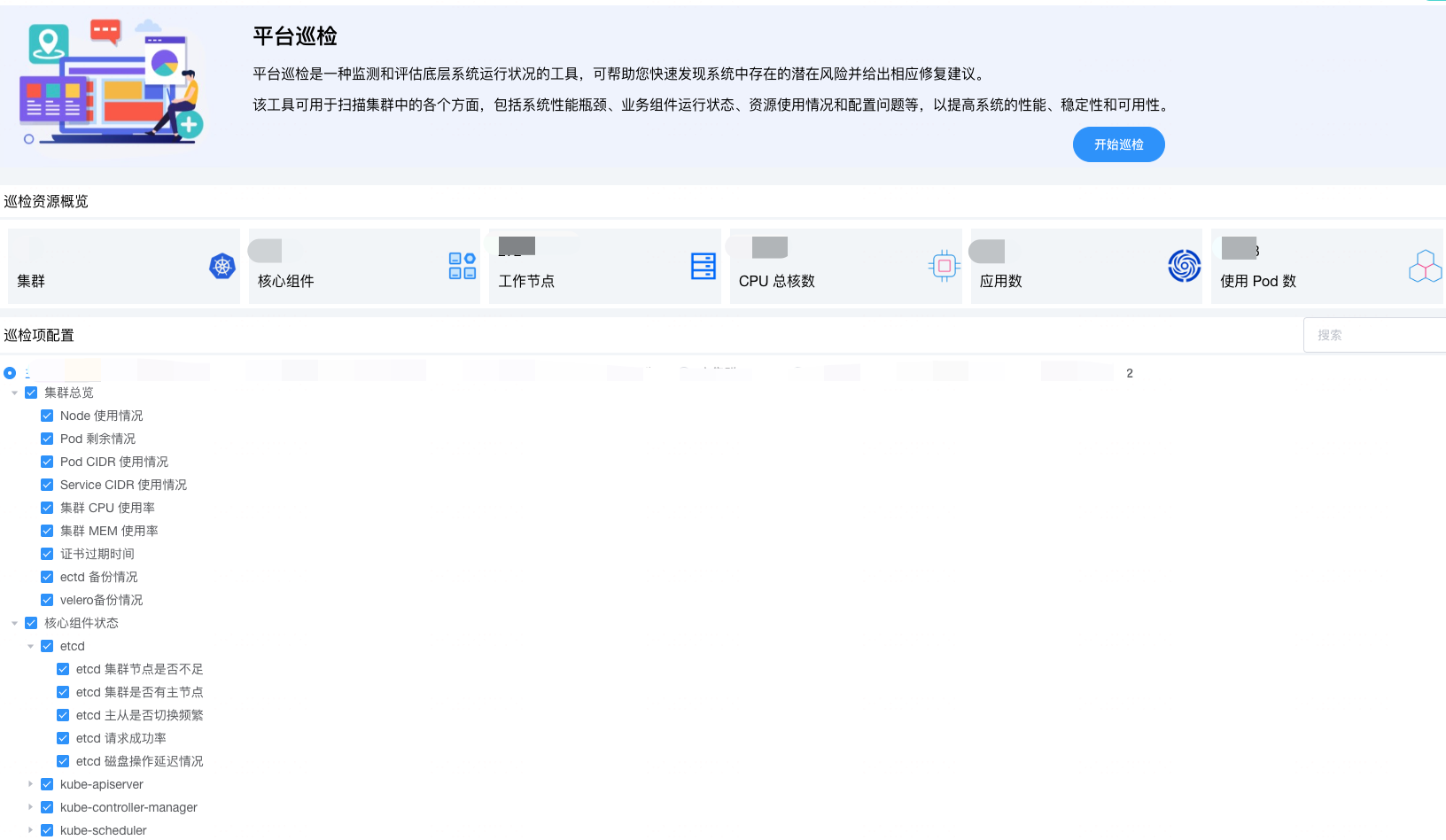
什么是平台巡检
平台巡检是一种监测和评估底层系统运行状况的工具,可帮助您快速发现系统中存在的潜在风险并给出相应修复建议。
该工具可用于扫描集群中的各个方面,包括系统性能瓶颈、业务组件运行状态、资源使用情况和配置问题等,以提高系统的性能、稳定性和可用性。
巡检的意义
我反复思考,有了 metrics/logs/traces + grafana + alert ,还需要巡检做什么?以下是我总结巡检的意义:
- 是监控的补充,比如证书过期、Pod CIDR 使用情况、Etcd 备份情况、Velero 备份情况,通过脚本更方便查看状态,编写 exporter 周期较长
- 可以监控 Prometheus、VictorMetric 等组件的状态,拉取最新数据情况,监控是否收集了各个组件的 metrics
- 是主动式的发现问题,能迅速了解整个集群的核心指标的状态,集中式检查,不用一个个 Grafana 图标检查
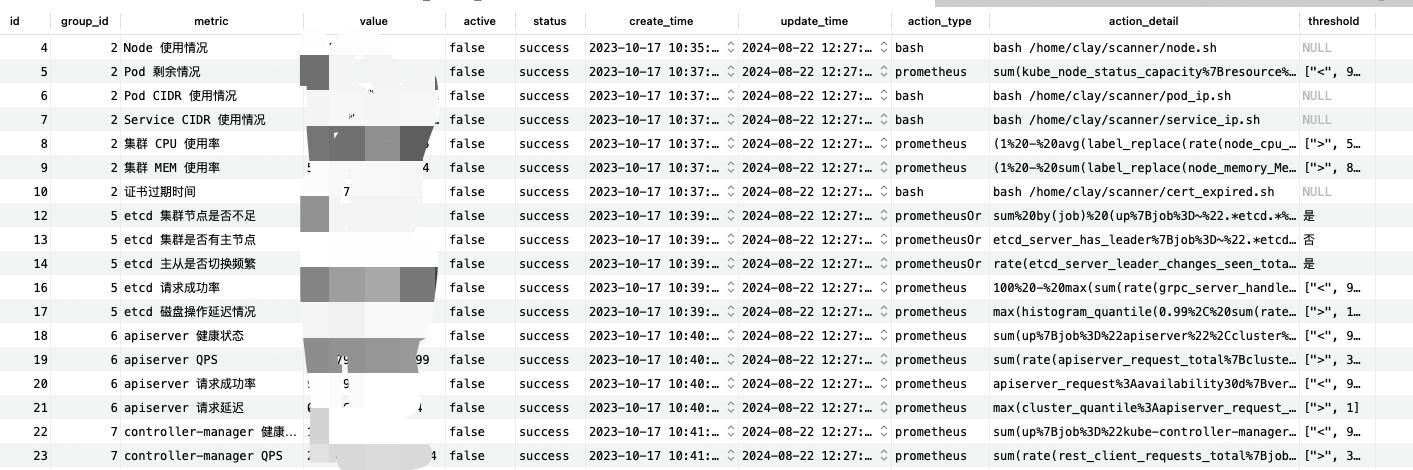
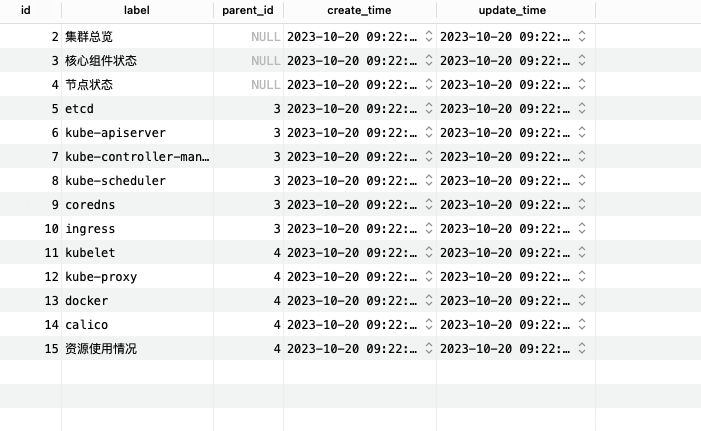
K8s 巡检关键指标
分三类
- 集群总览
- 核心组件状态
- 节点状态
里面的 Promql 和 Bash 脚本内容,需要根据实际情况进行配置!
集群总览
巡检项名称:Node 使用情况
描述:旨在查看集群 是否有备用资源
动作来源:bash
具体动作:
#!/bin/bash
#
# Node 数量巡检脚本
set -o errexit
set -o nounset
node_sum=$(kubectl get nodes | awk 'NR>1' | grep -v master -c)
node_ready=$(kubectl get nodes | awk 'NR>1' | grep -v master | grep -v SchedulingDisabled -c)
echo "| " "${node_ready}/${node_sum}"
if [[ $node_sum -gt $node_ready ]]; then
echo "success"
else
echo "warning"
fi
巡检项名称:Pod 剩余情况
描述:旨在查看 有无 Pod 资源可供分配
动作来源:prometheus
具体动作:
sum(kube_node_status_capacity{resource='pods'} * on(node) group_left(label_env) kube_node_labels{label_env=~"prod",cluster="core",zone=~"shanghai"} unless on(node) kube_node_role) -
sum(kube_pod_info *on (node) group_left(label_env) kube_node_labels{label_env=~"prod",cluster="core",zone=~"shanghai"} unless on(node) kube_node_role)
阈值:["<", 90]
巡检项名称:Pod CIDR 使用情况
描述:Pod 剩余可分配 IP 数量
动作来源:bash
具体动作:
#!/bin/bash
#
# Pod IP 剩余数量 巡检脚本
set -o errexit
set -o nounset
pod_ip_free=$(calicoctl ipam show | grep '%' | awk '{print $12}')
echo '| IP 剩余数量:' ${pod_ip_free}
if [[ $pod_ip_free -gt 500 ]]; then
echo "success"
elif [[ $pod_ip_free -gt 100 ]]; then
echo "warning"
else
echo "error"
fi
巡检项名称:集群 CPU 使用率
动作来源:prometheus
具体动作:
(1 - avg(label_replace(rate(node_cpu_seconds_total{mode="idle", cluster="core",zone=~"shanghai"}[60s]), "internal_ip", "$1", "instance", "(.+):(\\d+)") and on(internal_ip) kube_node_labels{cluster="core",zone=~"shanghai"} * on(node) group_left(internal_ip) kube_node_info)) * 100
阈值:[">", 50]
巡检项名称:集群 MEM 使用率
动作来源:prometheus
具体动作:
(1 - sum(label_replace(node_memory_MemAvailable_bytes{cluster="core",zone=~"shanghai"}, "internal_ip", "$1", "instance", "(.+):(\\d+)") and on(internal_ip) kube_node_labels{cluster="core",zone=~"shanghai"} * on(node) group_left(internal_ip) kube_node_info) / sum(label_replace(node_memory_MemTotal_bytes{cluster="core",zone=~"shanghai"}, "internal_ip", "$1", "instance", "(.+):(\\d+)") and on(internal_ip) kube_node_labels{cluster="core",zone=~"shanghai"} * on(node) group_left(internal_ip) kube_node_info)) * 100
阈值:[">", 85]
巡检项名称:证书过期时间
动作来源:bash
具体动作:
#!/bin/bash
#
# 证书过期时间 巡检脚本
set -o errexit
set -o nounset
ct=$(date -d "$(openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -dates |awk -F '=' '/notAfter/{print $2}'|awk '{print $1,$2,$3,$4}')" +%s)
dt=$(date +%s)
expired=$(($(($ct-$dt))/(60*60*24)))
echo "| " $expired "天后过期"
if [[ $expired -gt 60 ]]; then
echo "success"
elif [[ $expired -gt 15 ]]; then
echo "warning"
else
echo "error"
fi
巡检项名称:ectd 备份情况
描述:是否有最新备份
动作来源:bash
具体动作:
#!/bin/bash
#
# Etcd 备件检查脚本
set -o nounset
result=$(find /var/lib/docker/etcd_backup/ -mmin -120)
if [[ -n ${result} ]]; then
echo "正常"
echo "success"
else
echo "异常"
echo "error"
fi
巡检项名称:velero备份情况
描述:是否有最新备份
动作来源:bash
具体动作:
#!/bin/bash
#
# Velero 备件检查脚本
set -o nounset
current_date=$(date +%F)
backup_date=$(velero backup get | grep core-shanghai | awk '{print $5}' | sort -nr | head -1)
backup_date_2d=$(date -d "$backup_date +2 days" +%F)
if [[ $backup_date_2d > $current_date && $backup_date != "" ]]; then
echo "正常"
echo "success"
else
echo "异常"
echo "error"
fi
核心组件状态
etcd
巡检项名称:etcd 集群节点是否不足
动作来源:prometheusOr
具体动作:
sum by(job) (up{job=~".*etcd.*",cluster="core",zone="shanghai"} == bool 1) < ((count by(job) (up{job=~".*etcd.*",cluster="core",zone="shanghai"}) + 1) / 2)
阈值:是
巡检项名称:etcd 集群是否有主节点
动作来源:prometheusOr
具体动作:
etcd_server_has_leader{job=~".*etcd.*",cluster="core",zone="shanghai"} == 1
阈值:否
巡检项名称:etcd 主从是否切换频繁
动作来源:prometheusOr
具体动作:
rate(etcd_server_leader_changes_seen_total{job=~".*etcd.*",cluster="core",zone="shanghai"}[15m]) > 3
阈值:是
巡检项名称:etcd 请求成功率
动作来源:prometheus
具体动作:
100 - max(sum(rate(grpc_server_handled_total{grpc_type="unary",grpc_code!="OK",cluster="core",zone="shanghai"}[1m])) by (grpc_service) / sum(rate(grpc_server_started_total{grpc_type="unary",cluster="core",zone="shanghai"}[1m])) by (grpc_service) * 100.0)
阈值:["<", 99]
巡检项名称:etcd 磁盘操作延迟情况
动作来源:prometheus
具体动作:
max(histogram_quantile(0.99, sum(rate(etcd_disk_wal_fsync_duration_seconds_bucket{cluster="core",zone="shanghai"}[1m])) by (instance,le))) * 1000
阈值:[">", 10]
kube-apiserver
巡检项名称:apiserver 健康状态
动作来源:prometheus
具体动作:
sum(up{job="apiserver",cluster="core",zone="shanghai"}) / count(up{job="apiserver",cluster="core",zone="shanghai"}) *100
阈值:["<", 90]
巡检项名称:apiserver QPS
动作来源:prometheus
具体动作:
sum(rate(apiserver_request_total{cluster="core",zone="shanghai"}[1m]))
阈值:[">", 3000]
巡检项名称:apiserver 请求成功率
动作来源:prometheus
具体动作:
apiserver_request:availability30d{verb="all",cluster="core",zone="shanghai"} * 100
阈值:["<", 99]
巡检项名称:apiserver 请求延迟
动作来源:prometheus
具体动作:
max(cluster_quantile:apiserver_request_duration_seconds:histogram_quantile{cluster="core",zone="shanghai"})
阈值:[">", 1]
kube-controller-manager/kube-scheduler 巡检项同 apiserver 略
coredns/ingress 只巡检了健康状态 略
节点状态
kubelet
巡检项名称:kubelet 节点不可用列表
动作来源:prometheusList
具体动作:
sum by(node) (kube_node_status_condition{condition="Ready",job="kube-state-metrics",status="true",cluster="core",zone="shanghai"}) == 0
巡检项名称:PLEG relist 耗时过高列表
动作来源:prometheusList
具体动作:
histogram_quantile(0.99, sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet", metrics_path="/metrics",cluster="core",zone="shanghai"}[1m])) by (node,le)) * 1000 > 1000
资源使用情况
**巡检项名称:CPU 使用率大于50%的列表 **
动作来源:prometheusList
具体动作:
(1 - avg by(internal_ip) (label_replace(rate(node_cpu_seconds_total{mode="idle", cluster="core",zone=~"shanghai"}[60s]), "internal_ip", "$1", "instance", "(.+):(\\d+)")) and on(internal_ip) kube_node_labels{cluster="core",zone=~"shanghai",label_env=~"prod"} * on(node) group_left(internal_ip) kube_node_info) * 100 > 50
巡检项名称:MEM 使用率大于80%的列表
动作来源:prometheusList
具体动作:
sum by (internal_ip) (label_replace(1 - (node_memory_MemAvailable_bytes{cluster="core",zone=~"shanghai"} / node_memory_MemTotal_bytes{cluster="core",zone=~"shanghai"}), "internal_ip", "$1", "instance", "(.+):(\\d+)") and on(internal_ip) kube_node_labels{cluster="core",zone=~"shanghai",label_env=~"prod"} * on(node) group_left(internal_ip) kube_node_info) * 100 > 80
巡检项名称:磁盘 / 使用率大于80%的列表
动作来源:prometheusList
具体动作:
sum by (internal_ip) (label_replace(100 - ((node_filesystem_avail_bytes{job="node-exporter",mountpoint="/",fstype!="rootfs",cluster="core",zone="shanghai"} * 100) / node_filesystem_size_bytes{job="node-exporter",mountpoint="/",fstype!="rootfs",cluster="core",zone="shanghai"}), "internal_ip", "$1", "instance", "(.+):(\\d+)") and on(internal_ip) kube_node_labels{cluster="core",zone=~"shanghai",label_env=~"prod"} * on(node) group_left(internal_ip) kube_node_info) > 80
巡检项名称:PID 使用率大于80%的列表
动作来源:prometheusList
具体动作:
label_replace(node_processes_threads{cluster="core",zone="shanghai"} / on(instance) min by(instance) (node_processes_max_processes or node_processes_max_threads{cluster="core",zone="shanghai"}),"internal_ip", "$1", "instance", "(.+):(\\d+)") * 100 > 80
巡检项名称:FD 使用率大于70%的列表
动作来源:prometheusList
具体动作:
sum by(internal_ip) (label_replace(node_filefd_allocated{job="node-exporter",cluster="core",zone="shanghai"} * 100 / node_filefd_maximum{job="node-exporter",cluster="core",zone="shanghai"}, "internal_ip", "$1", "instance", "(.+):(\\d+)")) > 70
巡检项名称:时间不同步列表
动作来源:prometheusList
具体动作:
min_over_time(node_timex_sync_status{cluster="core",zone="shanghai"}[5m]) == 0 and node_timex_maxerror_seconds{cluster="core",zone="shanghai"} >= 16
巡检项名称:dockerHung 列表
动作来源:prometheusList
具体动作:
sum by(node) (rate(problem_counter{reason="DockerHung",cluster="core",zone="shanghai"}[1m])) > 0
kube-proxy/calico只巡检了健康状态 略
内核发生错误列表 同 dockerHung 列表 通过 NPD 收集的指标进行暴露判断 略
巡检平台(自动化)
细心的小伙伴可能已经发现,上文巡检项中的 “动作来源” 分为 bash、prometheus、prometheusOr、prometheusList 四种
-
bash 对应放置在 K8s Master 节点上指定目录下的 bash 脚本,脚本中有两行返回值,一行是具体结果,一行是正常 Or 异常
-
prometheus 对应通过 Promql 查询出来的结果再与 具体的阈值 做比较判断,最后得出是否正常
-
prometheusOr 逻辑类似,只不过阈值是 是 或 否
-
prometheusList 一样,只不过列表不为空就代表有异常
所有的执行语句、执行脚本名称,都放到了 mysql 表里进行了固定,想要新增 巡检项,只需在 mysql 表中插入一条规则即可
注意: 要将 promql 进行 URL 编码
核心伪代码如下
var mu sync.Mutex
type ScannerRequest struct {
CheckKeys []int `json:"check_keys"`
SelectedCluster int `json:"selected_cluster"`
}
// ScannerStart 执行巡检
func (s *ScannerController) ScannerStart(g *gin.Context) {
mu.Lock()
defer mu.Unlock()
// 先更新数据库状态 status: running 巡检中 | finish 巡检完成
s.store.UpdateAllStatus()
// 解析数据
var r ScannerRequest
if err := g.ShouldBindJSON(&r); err != nil {
v2api.AbnormalJsonResponse(g, "", "body parse error: "+err.Error())
return
}
var scannerItems []int
// 定义 Cluster 结构体
type Cluster struct {
ID int `json:"id"`
ClusterName string `json:"cluster_name"`
Zone string `json:"zone"`
Hosts string `json:"hosts"`
}
// 初始化数据
clusterData := []string{
`{"id": 11, "cluster_name": "core", "zone": "shanghai", "hosts": "10.10.10.10"}`,
`{"id": 12, "cluster_name": "other", "zone": "beijing", "hosts": "10.10.10.20"}`,
}
// 创建映射
clusterMap := make(map[int]Cluster)
// 解析JSON数据并填充映射
for _, d := range clusterData {
var cluster Cluster
err := json.Unmarshal([]byte(d), &cluster)
if err != nil {
fmt.Println("Error decoding JSON:", err)
return
}
clusterMap[cluster.ID] = cluster
}
for _, item := range r.CheckKeys {
if item > 300 {
scannerItems = append(scannerItems, item/100)
}
}
var wg sync.WaitGroup
wg.Add(len(scannerItems))
for _, scannerItem := range scannerItems {
go func(scannerItem int) {
defer wg.Done() // 在 Goroutine 完成时减少 WaitGroup 的计数
query, err := s.store.GetItem(scannerItem, "action_type", "action_detail", "threshold")
if err != nil {
fmt.Println("查询数据失败" + err.Error())
}
promql := strings.ReplaceAll(query.ActionDetail, "%22core%22", "%22"+clusterMap[r.SelectedCluster].ClusterName+"%22")
promql = strings.ReplaceAll(promql, "%22shanghai%22", "%22"+clusterMap[r.SelectedCluster].Zone+"%22")
switch query.ActionType {
case "prometheus":
value, err := prometheusQuery(promql)
if err != nil {
fmt.Println("查询 Prometheus 失败" + err.Error())
}
var thresholdArr []interface{}
err = json.Unmarshal([]byte(query.Threshold), &thresholdArr)
if err != nil {
fmt.Println("Error:", err)
}
var status string
intValue, err := strconv.ParseFloat(value, 64)
if err != nil {
// 处理转换错误
fmt.Println("Error converting string to int:", err)
}
switch v := thresholdArr[1].(type) {
case float64:
if thresholdArr[0] == "<" {
if intValue > v {
status = "success"
} else {
status = "warning"
}
}
if thresholdArr[0] == ">" {
if intValue < v {
status = "success"
} else {
status = "warning"
}
}
default:
fmt.Println("Type of thresholad", reflect.TypeOf(thresholdArr[1]))
}
err = s.store.UpdateItem(scannerItem, value, status)
if err != nil {
fmt.Println("更新数据失败" + err.Error())
}
case "prometheusOr":
value, err := prometheusQueryOr(promql)
if err != nil {
fmt.Println("查询 Prometheus 失败" + err.Error())
}
if value == query.Threshold {
err = s.store.UpdateItem(scannerItem, value, "error")
if err != nil {
fmt.Println("更新数据失败" + err.Error())
}
} else {
err = s.store.UpdateItem(scannerItem, value, "success")
if err != nil {
fmt.Println("更新数据失败" + err.Error())
}
}
case "prometheusList":
value, err := prometheusQueryList(promql)
if err != nil {
fmt.Println("查询 Prometheus 失败" + err.Error())
}
if value == "空" {
err = s.store.UpdateItem(scannerItem, value, "success")
if err != nil {
fmt.Println("更新数据失败" + err.Error())
}
} else {
err = s.store.UpdateItem(scannerItem, value, "warning")
if err != nil {
fmt.Println("更新数据失败" + err.Error())
}
}
case "bash":
res, err := executeSSHCommand(clusterMap[r.SelectedCluster].Hosts+":22", "root", "/root/.ssh/id_rsa", query.ActionDetail)
if err != nil {
fmt.Println(err)
}
resArray := strings.Split(res, "\n")
value := resArray[0]
status := resArray[1]
err = s.store.UpdateItem(scannerItem, value, status)
if err != nil {
fmt.Println("更新数据失败" + err.Error())
}
}
}(scannerItem)
}
v2api.NormalJsonResponse(g, "开始巡检", "")
}
type Result struct {
ResultType string `json:"resultType"`
ResultData []struct {
Metric map[string]interface{} `json:"metric"`
Value []interface{} `json:"value"`
} `json:"result"`
}
type Response struct {
Status string `json:"status"`
IsPartial bool `json:"isPartial"`
Data Result `json:"data"`
}
var promURL = "http://victoria-select.xxx.xxx/select/1/prometheus/api/v1/query?query="
func prometheusQuery(promql string) (string, error) {
var res Response
currentTimestamp := time.Now().Unix()
reqURL := promURL + promql + "&start=" + strconv.Itoa(int(currentTimestamp))
// 发起 GET 请求
response, err := http.Get(reqURL)
if err != nil {
return "", err
}
defer response.Body.Close()
// 读取响应内容解析
body, err := io.ReadAll(response.Body)
if err != nil {
return "", err
}
if err := json.Unmarshal(body, &res); err != nil {
return "", err
}
if len(res.Data.ResultData) == 0 {
fmt.Println(reqURL)
fmt.Println(res.Data.ResultData)
return "", err
}
value, ok := res.Data.ResultData[0].Value[1].(string)
if !ok {
return "", errors.New("conversion failed")
}
return value, nil
}
func prometheusQueryOr(promql string) (string, error) {
var res Response
currentTimestamp := time.Now().Unix()
reqURL := promURL + promql + "&start=" + strconv.Itoa(int(currentTimestamp))
// 发起 GET 请求
response, err := http.Get(reqURL)
if err != nil {
return "", err
}
defer response.Body.Close()
// 读取响应内容解析
body, err := io.ReadAll(response.Body)
if err != nil {
return "", err
}
if err := json.Unmarshal(body, &res); err != nil {
return "", err
}
if len(res.Data.ResultData) == 0 {
return "否", nil
}
return "是", nil
}
func prometheusQueryList(promql string) (string, error) {
var res Response
currentTimestamp := time.Now().Unix()
reqURL := promURL + promql + "&start=" + strconv.Itoa(int(currentTimestamp))
// 发起 GET 请求
response, err := http.Get(reqURL)
if err != nil {
return "", err
}
defer response.Body.Close()
// 读取响应内容解析
body, err := io.ReadAll(response.Body)
if err != nil {
return "", err
}
if err := json.Unmarshal(body, &res); err != nil {
return "", err
}
if len(res.Data.ResultData) == 0 {
return "空", nil
}
var value string
for _, v := range res.Data.ResultData {
switch s := v.Metric["node"].(type) {
case string:
value = value + " " + s
}
}
if len(value) == 0 {
for _, v := range res.Data.ResultData {
switch s := v.Metric["internal_ip"].(type) {
case string:
value = value + " " + s
}
}
}
return value, nil
}
func executeSSHCommand(serverAddr, username, privateKeyPath, command string) (string, error) {
key, err := ioutil.ReadFile(privateKeyPath)
if err != nil {
return "", err
}
signer, err := ssh.ParsePrivateKey(key)
if err != nil {
return "", err
}
config := &ssh.ClientConfig{
User: username,
Auth: []ssh.AuthMethod{
ssh.PublicKeys(signer),
},
HostKeyCallback: ssh.InsecureIgnoreHostKey(),
}
client, err := ssh.Dial("tcp", serverAddr, config)
if err != nil {
return "", err
}
defer client.Close()
session, err := client.NewSession()
if err != nil {
return "", err
}
defer session.Close()
output, err := session.CombinedOutput(command)
if err != nil {
return "", err
}
return string(output), nil
}
页面展示
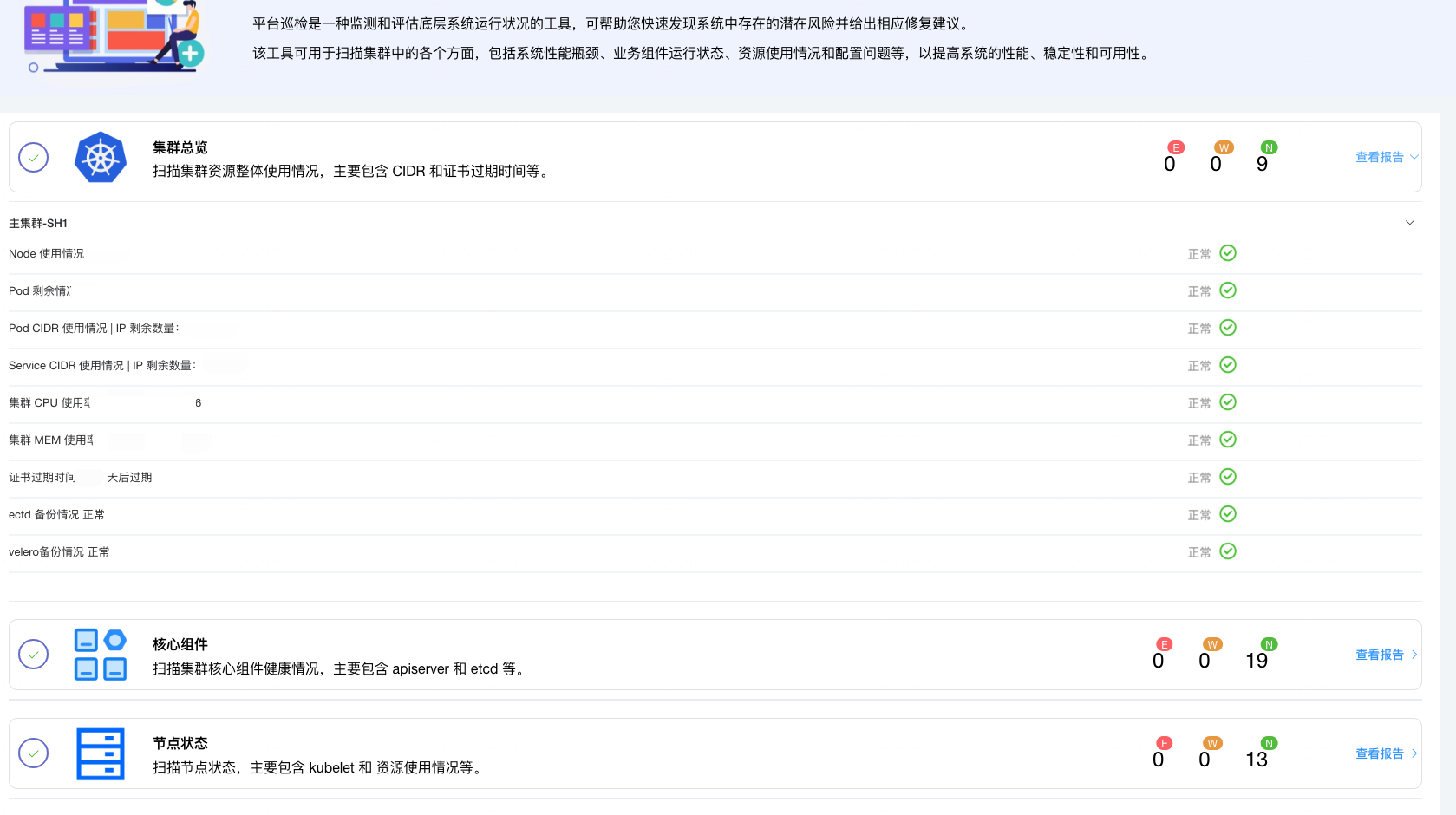
巡检有没有必要?大家关心哪些巡检指标,欢迎在留言区 讨论
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/SreGuide 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









