









 本文深入探讨了伪共享现象,解析了CPU缓存的工作原理,包括缓存行和MESI协议,以及伪共享如何影响多线程程序的性能。通过实例测试,展示了伪共享的解决方案,如字节填充和Java注解。
本文深入探讨了伪共享现象,解析了CPU缓存的工作原理,包括缓存行和MESI协议,以及伪共享如何影响多线程程序的性能。通过实例测试,展示了伪共享的解决方案,如字节填充和Java注解。
前言
前几天看到了伪共享这个概念,但是并没有去做深入的了解,今天又看到了这个概念,才想起来要好好研究一下伪共享究竟是个什么东西,反而在学习的过程中又引发了我对JMM(Java内存模型)的思考,前几天有个同事分享了JMM相关内容,当时我感觉自己已经比较了解了,但是今天来看似乎并没有能做到真的“比较理解“,因此痛定思痛,决定记录一下自己的学习过程。
1.从CPU说起
1.1 CPU缓存
我们知道,CPU中存在高速缓存(Cache),其主要用处是将主存中的数据预加载,方便CPU核心快速取到数据,因为CPU的运算速度是远高于内存读写速度的,如果CPU每次运算都需要取寻址再读内存中的数据,就需要很大的时间开销,缓存预加载数据的目的就是减少这个时间。
当然现代CPU已经发展到有多级缓存,缓存距离CPU核心越近,缓存的读写速度越快,当然处于成本考虑,距离CPU核心越近缓存容量也越小。
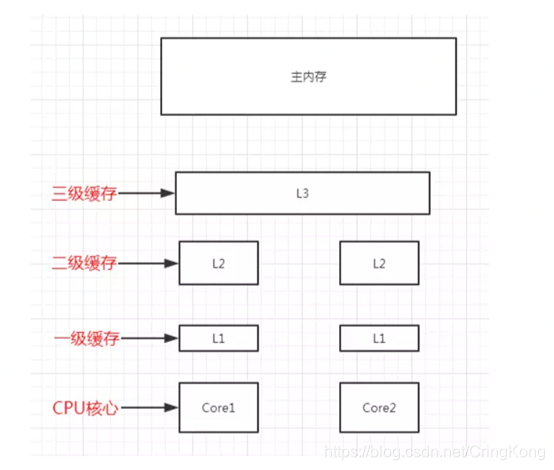
CPU缓存大家可能都知道,毕竟Intel和AMD都明明白白的给我们标出来缓存大小,但是关于缓存的机制以及缓存会怎么影响我们编写程序的效率,我们往往不太清楚。
1.2 缓存行
CPU缓存的最小的可操作单位是缓存行,缓存行中的数据其实就是内存中的一块数据,现代CPU中的缓存行大小一般是64字节(因为CPU一般都是64位),在这里我们不考虑多级缓存,当CPU进行一次运算操作时,会一次性将内存中连续的64字节的数据加载到缓存行中,然后CPU核心会直接读写缓存内容,如下图:
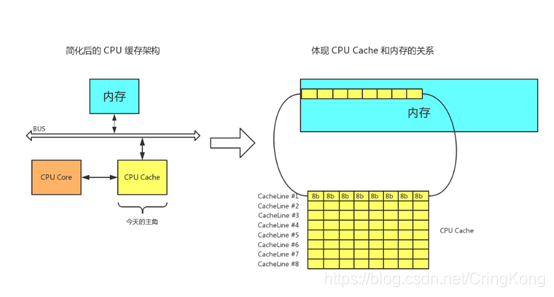
比如说Java中long类型数组的,当CPU需要读取其中某个值时,会同时将后续7位的数据也读入缓存中,这8个long类型的值会在同一行缓存行中。
这种缓存机制的好处很明显,对于连续数据的读写操作,缓存减少CPU和内存的数据交换和传输时间。CPU和内存以及缓存的传输交互时间可见下图:

可见,就像Linux中的PageCache机制作为内存和硬盘的读写缓存,用来加速连续数据的读写,CPU缓存是可以极大的加速内存和CPU的数据交互速度。这里我们提供一个例子来验证缓存行的作用:
public class CacheLineEffect {
static long[][] arr;
public static void main(String[] args) {
// 64位CPU的缓存行大小一般是64字节,因此我们每行填充8个long类型
arr = new long[2 << 20][8];
Random random = new Random();
for (int i = 0; i < 2 << 20; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = random.nextInt(100);
}
}
long sum = 0L;
long begin = System.currentTimeMillis();
for (int i = 0; i < 2 << 20; i += 1) {
for (int j = 0; j < 8; j++) {
sum += arr[i][j];
}
}
System.out.println("利用缓存行性质横向遍历时间:" + (System.currentTimeMillis() - begin) + "ms" + ",求和值为 :" + sum);
sum = 0L;
begin = System.currentTimeMillis();
for (int i = 0; i < 8; i += 1) {
for (int j = 0; j < 2 << 20; j++) {
sum += arr[j][i];
}
}
System.out.println("不利用缓存行性质纵向遍历时间:" + (System.currentTimeMillis() - begin) + "ms" + ",求和值为 :" + sum);
}
}
可以看到,横向遍历二位数组时,缓存行会预加载8个long类型的值(理想情况),而纵向遍历则不会用到预加载的数据,利用缓存行的性质遍历数组比起不利用缓存行的性质遍历数组要时间要少的多。
但是也如同PageCache对于随机读写会带来负面影响一样,CPU缓存也有可能对于我们的程序性能带来一些影响。
1.3 MESI协议
现代CPU一般都会有多个CPU核心,不同核心对应着自己的CPU缓存,对于单线程的程序来说,可能没什么问题,但是对于多线程的程序来说,事情就变得没有这么简单了。
假设有线程A和线程B同时操作一个内存地址,前面我们说过,CPU缓存会预加载内存到其中,如果此时线程A和线程B正好在两个CPU核心上并行运行,问题就出现了,核心A和核心B同时对内存数据进行修改,它们各自的缓存不就会出现冲突吗?当然CPU可以把每个访问都通过总线去修改主存数据,但是这样就失去了缓存的意义,同时过于频繁的总线传输也会极大的降低多核CPU的性能。
因此现代CPU就诞生了MESI协议来保证缓存一致性,同时也避免了每次CPU核心操作都要对主存进行操作。
CPU中每个缓存行(caceh line)使用4种状态进行标记(使用额外的两位(bit)表示):
M: 被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。
当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。
同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
S: 共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
I: 无效的(Invalid)
该缓存是无效的(可能有其它CPU修改了该缓存行)。
下图是MESI状态转化图:
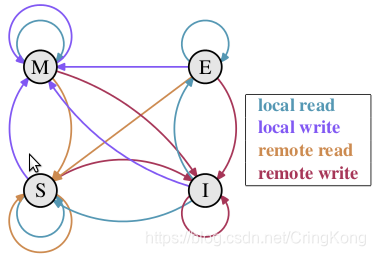
这里需要解释一下:
local read:CPU核心读取数据local write:CPU核心修改数据remote read:其他CPU核心读取与本核心缓存相同的数据remote write:其他CPU核心修改与本核心缓存相同的数据
这里需要注意的是,无论是read还是write操作,其实都是指对于内存中内容的读写,但是之前我们说过,现代CPU不会直接对内存进行读写,而是直接对缓存进行读写,但是最终还会回写到内存,所以还请读者自行体会上面四种操作的含义。
下图是MESI协议与四种操作的具体关系,相信看过下图以后能更好的理解上面我说的。
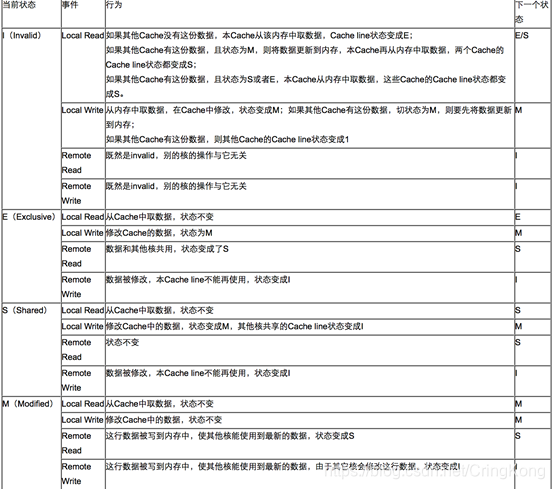
AMD的Opteron处理器使用从MESI中演化出的MOESI协议,O(Owned)是MESI中S和M的一个合体,表示本Cache line被修改,和内存中的数据不一致,不过其它的核可以有这份数据的拷贝,状态为S。
Intel的core i7处理器使用从MESI中演化出的MESIF协议,F(Forward)从Share中演化而来,一个Cache line如果是Forward状态,它可以把数据直接传给其它内核的Cache,而Share则不能。
2. 伪共享
了解了CPU缓存行和MESI协议以后,我们才能引出伪共享的概念,之前我们说了,CPU缓存的最小操作单位是缓存行,也就是说CPU无论是要去读内存中的什么数据,都会一次性将一个缓存行的数据全部读入,而同时我们也了解到,在多核CPU中对于,MESI协议用来保障缓存一致性,当出现远程写的情况,MESI协议会保证其他CPU核心对应的缓存失效,基于以上两点,多线程编程中一个隐藏很深的陷阱出现了——伪共享(false sharing)现象出现了。
伪共享现象出现的原因如下图:
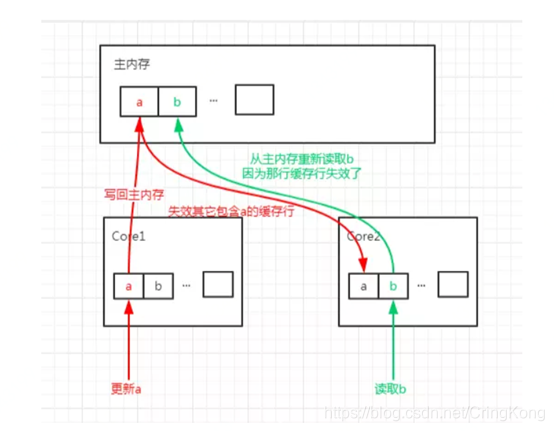
线程1运行在CPU核心1上,线程2运行在CPU核心2上,此时他们操作了内存中相邻的数据,这些数据恰好会被CPU读入同一个缓存行,线程1操作了数据a,线程2操作了数据b,但是因为要保证多核缓存一致性,会出现以下流程:
- cpu核心1需要修改数据a,因此进入
local write流程,发出RFO(Request For Owner)请求获取对于此缓存行的独占权 - cpu核心2进入到
remote write流程,核心2的该行缓存失效,进入Invalid状态 - cpu核心1的
local write流程完毕,缓存行数据a被更新,核心1的改行缓存进入Modified状态,同时将脏缓存写回主存 - cpu核心2需要数据b,此时就进入
local read流程,因为该行缓存为Invalid失效状态,需要重新去内存取值,同时核心1和核心2的改行缓存都进入Sharing状态 - 核心1或者核心2如果需要对a或者b进行修改,那么就又进入一次这个复杂的流程
相信大家已经发现了,a和b是内存中的两个数据,并且线程1和线程2对于数据并没有竞争关系,但是a和b因为被加载进了同一个缓存行,CPU会浪费很多无意义的时间来保证缓存一致性,导致多线程程序运行的效率降低,这就是所谓的伪共享。
3. 解决方案
理解了伪共享产生的原因以后,我们就可以针对性的制定解决方案
- 字节填充:将多线程中频繁使用的对象填充到至少64字节,防止这个对象因为和其他对象预加载到同一个缓存行导致伪共享现象出现,降低多线程性能
- 使用Java8提供注解:原理和字节填充一样,只不过JVM会自动帮我们填充字节,防止多线程环境中出现伪共享现象
测试
我们下面用一个例子来测试一下伪共享以及其解决方案到底会给程序带来多大的影响,对于每组例子,都选择1-4个线程同时进行操作,当然这个是有一定误差的,因为ThreadLocalRandom类可能会带来一定的测试影响。
public class FalseSharing implements Runnable {
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
// 测试时需要替换成不同的类
private static ValuePadding[] longs;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for (int i = 1; i < 5; i++) {
System.gc();
runTest(i, false);
}
}
private static void runTest(int NUM_THREADS, boolean testFalseSharing) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longs = new ValuePadding[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new ValuePadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
// 计算多线程运行时间
final long start = System.currentTimeMillis();
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
System.out.println("Thread num " + NUM_THREADS + " duration = " + (System.currentTimeMillis() - start));
}
@Override
public void run() {
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = threadLocalRandom.nextLong();
}
}
public final static class ValuePadding {
// 手动填充数据
protected long p1, p2, p3, p4, p5, p6, p7;
protected long value = 0L;
}
public final static class ValueNoPadding {
// 不填充任何数据
protected long value = 0L;
}
@Contended
public final static class ValuePaddingAnnotation {
// 始用Java注解自动填充
protected long value = 0L;
}
}
这里我的机器是双核四线程,理论上来说超过四线程就会出现线程上下文切换带来的时间损耗,最多只测试了4个线程。
测试结果如下
使用字节填充
Thread count: 1 duration = 731
Thread count:2 duration = 883
Thread count:3 duration = 913
Thread count:4 duration = 1184
使用@Contended注解
Thread count:1 duration = 637
Thread count:2 duration = 858
Thread count:3 duration = 931
Thread count:4 duration = 1231
无填充,无注解
Thread count:1 duration = 756
Thread count:2 duration = 1353
Thread count:3 duration = 1421
Thread count:4 duration = 2137
从上面的测试结果来看,伪共享现象确实在多线程环境下降低了程序的性能,而使用字节填充或者@Contended注解,都可以避免伪共享现象的出现。
需要注意一点:
要想让我们程序中的@Contended注解生效,需要指定JVM参数-XX:-RestrictContended

4. 后记
在学习伪共享现象的时候,我对于volatile关键字又有了进一步的认实,关于MESI协议存在的一些问题,以及JMM模型以前有些不理解的内容,又进行了深一步的学习,准备最近整理成博客,记录一下自己的深挖过程。
参考文章:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









