








作者 | 火山引擎EMR团队
众所周知,基于 Hadoop 的 EMR 体系发展到现在,经历了很多个阶段。从基于 IDC 机房通过 CDH 去部署的 1. 0 阶段,演进到在公有云上面按照存算分离的办法去进行的 2. 0 阶段。
而在这些基础上,火山引擎数智平台 VeDI 的 EMR 团队又探索出了无状态的 EMR 3.0 演进阶段。上个月底,火山引擎 EMR 正式上线瞬态集群新功能,该能力基于业界领先的 EMR Stateless 理念,可以实现集群级别的弹性伸缩,即无业务需求时释放集群,有业务需求时再拉起集群,从而帮助企业大幅降低产品使用和平台运维成本。
什么是瞬态集群,什么是 Stateless 理念,本文从基础概念、架构体系、演进过程、实际运用场景&使用价值等多个角度全方位介绍 EMR Stateless 的创新理念以及应用。


什么是 Stateless?
Stateless——它的本质是一个瞬态集群的概念,但又不完全是瞬态集群,它属于一个轻量级交付的、无状态的瞬态集群。那无状态的瞬态集群又是什么意思呢?
首先,Stateless 的集群是在存算分离的基础上,进一步演化而得来的一个瞬态集群。普通的存算分离集群,像 Hadoop 体系里的相关内容都是绑定在集群中的,没有彻底将这些有状态的内容剥离出来成为一个独立的服务。而 Stateless 是把 Hive Metastore 以及 History Server 等进行了服务化,也就是从计算集群中把它们剥离出来了。
在 Stateless 的加持下,我们所指的 Hadoop 体系中的 Master、Core、Task 等节点就组成一个无状态的轻量级瞬态集群,可以被随时创建或释放,并拥有多个副本,这无疑可以让集群具备一个更好的扩展性。基于此,接下来就能够在云原生的基础上,以集群的视野,去更好的做能力的成长以及成本的优化。

接下来,为大家对比一下 Stateful 模式和 Stateless 模式,它们两个之间有什么典型的差异点?
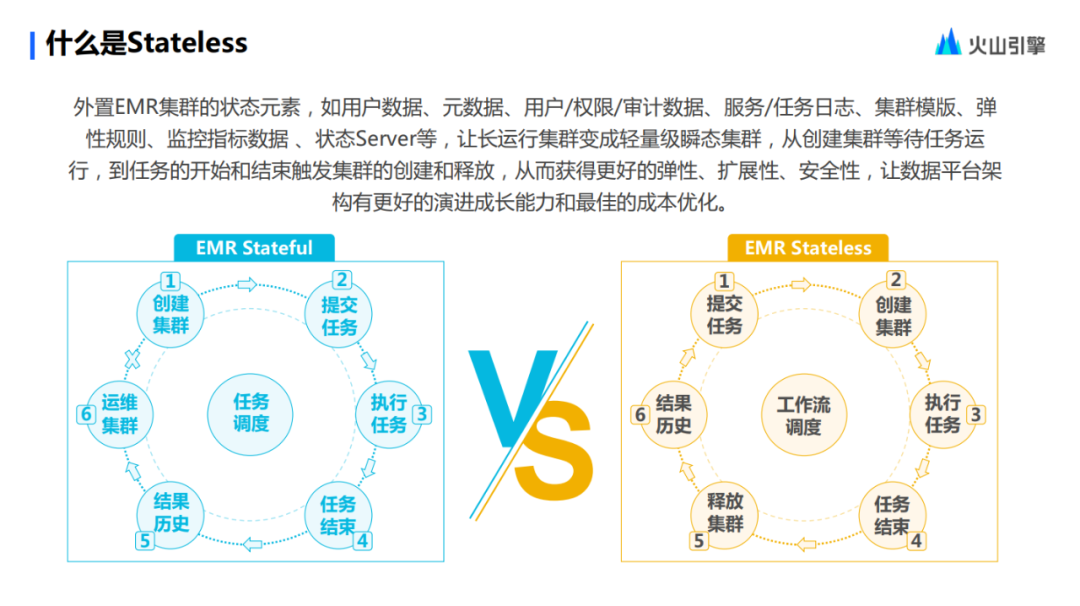
左边这个流程图,是一个传统的 Stateful 模式。
在这个模式下,大家要提交一个任务的数据流程通常是这样的,首先必须要有一个长时间运行的集群,有了集群以后,再将任务提交上去,接下来无论是通过 IO 的直接返回,还是把数据写入到 HDFS 或是对象存储,执行结束后都将拿到历史结果。
站在大数据维护视角来看,在提交任务的流程结束以后,运维长时间运行的集群,无论是对它的运行状态进行监控,看看它是否出现了故障,还是对它存在的服务进行日志采集,这些动作都会产生一定量的运维成本。同时,在任务结束后,这些集群事实上变为了一个空置的集群。站在总成本承受的角度上来讲,这其实是一个不利的选项,以上就是典型的Stateful模式。
而在 Stateless 的模式下,这一切就会有所变化。
首先,操作的第一步直接变为了提交任务。在提交任务以后,集群会被及时地、按需地创建出来用于运行任务。当任务运行完成以后,集群将会被释放掉。在用户拿到计算结果之后,意味着整个的任务提交过程随之结束。
在这个过程中,由于 Stateless 已经把具有状态属性的,像日志服务之类的功能外置于集群。在集群释放以后,用户仍可以通过日志服务查询到任何一个时间段内,在 Stateless 集群模板下面的集群里执行过的任何一个任务结果。
在这样的流程中,用户是不需要去运维执行集群的。这
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1
1











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









