







微调(fine-tuning)
在平时的训练中,我们通常很难拿到大量的数据,并且由于大量的数据,如果一旦有调整,重新训练网络是十分复杂的,而且参数不好调整,数量也不够,所以我们可以用微调。
微调网络:
通常我们有一个初始化的模型参数文件,我们可以在ImageNet上1000类分类训练好的参数的基础上,根据我们的分类识别任务进行特定的微调
步骤
在网络的微调中,分为以下几个流程
- 准备好训练集和数据集
- 计算数据集的均值文件,因为集中特定领域的图像均值文件会跟ImageNet上比较General 的数据的均值不太一样
- 修改网络最后一层的输出类别,加快最后一层的参数学习速率
- 调整solver的配置参数,通常修改学习速率和步长,迭代次数
- 启动训练,加载pretrained模型的参数
在进行实例之前,先来看一下要用到的所有的文件的作用
/home/caffe/models/bvlc_reference_caffenet
train_val.prototxt文件
网络配置文件,在训练的时候用的
deploy.prototxt
在测试的时候用的
以上的这些操作都是用系统自带的网络来跑自己的数据
我们现在做的两个例子都有自己跑数据,并且训练模型,所以只要修改lenet_solver.prototxt和lenet_train_test.prototxt文件就可以有微调效果了,之后会尝试用caffenet来跑自己的数据
MNIST数据集微调
之前训练好了mnsit,并且也对数据集数目进行修改,并测试
这次来进行微调
lenet_solver.prototxt:
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: CPU修改
lr_policy: “step”
stepsize: 100
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "step"
gamma: 0.0001
stepsize: 100
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 500
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: CPUsudo ./build/tools/caffe train
--solver ./examples/mnist/lenet_solver.prototxt
--weights ./examples/mnist/lenet_iter_10000.caffemodel 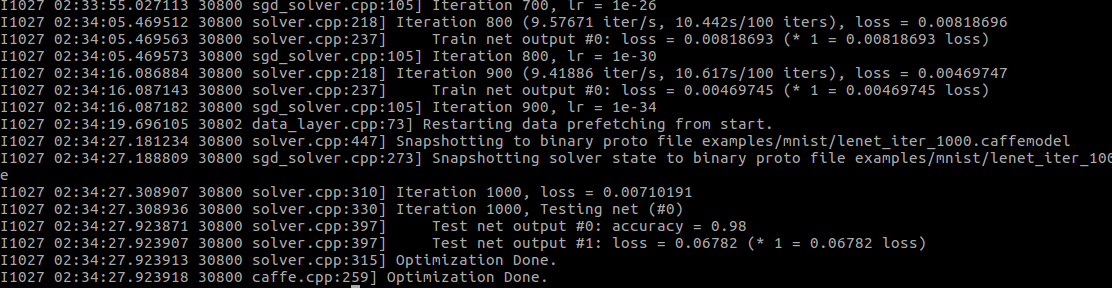
base_lr = 0.001
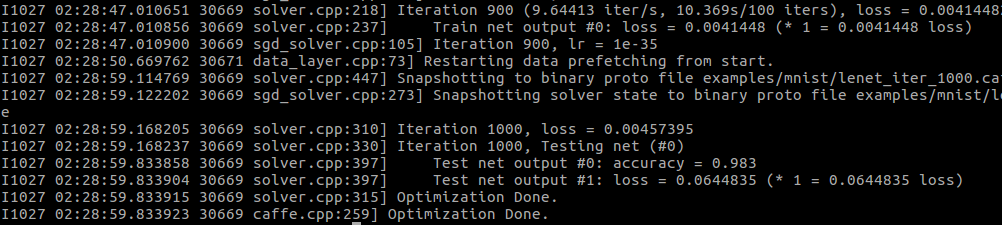
可以看到准确率和损失值有变化















 2294
2294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









