







HDFS是一种分布式文件系统,它采用的是master/slave架构对海量文件进行管理。一个HDFS集群是由一个NameNode和一定数目的DataNode组成的,NameNode是一个中心服务器,它负责管理集群中的执行调度,而DataNode则是具体任务的执行节点。
HDFS以block为基本单位来处理文件,每个DataNode上都存储一个block,block默认大小为64MB,开发者也可以根据需要自行配置。HDFS客户端会将需要存储的大小划分为多个block,再通过NameNode的管理调度将每个block存储到相应的DataNode中。一般情况下,每个block都会有相应的两份备份节点,一个存储在跟自己同一个的机架,另一个存储在另外一个机架上,这样做是为了防止其中一个机架宕机后不会使数据丢失,同时又能保证高效读取。
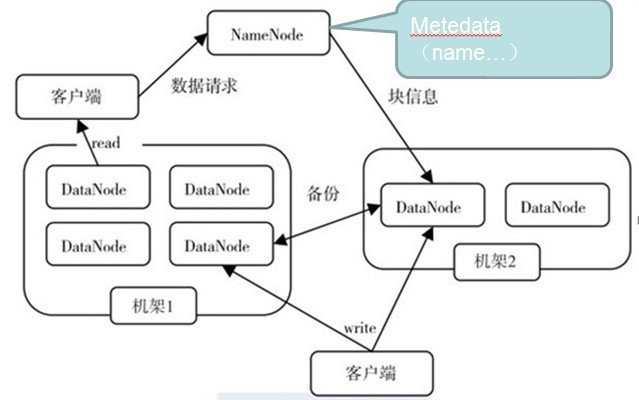
NameNode:充当master角色,负责管理调度DataNode并存储节点位置和日志信息等。
DataNode:充当slave角色,负责存储block形式的文件。
HDFS的写操作:
假设现在要对一个A文件有128MB进行分布式存储。有两台机架,block按默认的大小配置。
- 客户端先将A文件进行分割成两个大小为64MB的block1和block2.
- 客户端向NameNode发送写数据的请求
- NameNode查询并返回可用的DataNode信息给客户端
- 客户端向DataNode以流式写入block1
以流式写入DataNode的过程如下: - 将64MB的文件按照64KB的形式划分成一个个package
- 然后将package1发送给DataNode1(以下简称DN)
- DN1接收到package1后将其发送到DN2,同时客户端向DN1发送package2
- DN2接收到package1之后发送给DN3,同时接收到DN1发送来的package2
- 以此类推,直到block1完成全部写入成功后返回客户端一个确认信号再进行block2的写入流程
注:如果写入过程中DN出现故障,则该DN的写入流将会被关闭,剩余的block继续传输给剩下的DN。
HDFS的读操作:
条件配置与上面相同
1. 客户端向NameNode(以下简称NN)发起读的请求
2. NN会返回给客户端一个文件的部分或者全部的block列表,对于每个block,NN都会返回该block的备份节点的地址
3. 客户端会选取离其最近的DN来读取block,读取完block的数据之后关闭与当前DN的连接,并寻找下一个最佳的DN存储的block
4. 如果读取完列表的block之后还没有文件还没读取结束,客户端会向NN申请下一批block列表
注:如果读取当前DN数据的时候出现错误,客户端会通知NN,NN将出错DN的备份节点信息返回给客户端,让客户端读取备份节点的block
HDFS的缺陷
1. 因为NN把文件系统的元数据存储在内存中,所以文件系统中所能容纳的文件数目是由NN的内存大小来决定,所以当客户端需要存储大量的小文件的时候便不适合使用HDFS
2. 由于HDFS是采用流的形式写入,写入只能一条一条的进行,不支持并发处理,所以不适合多个用户对同一个文件的写操作
3. HDFS是对大型数据的一种存储系统,所以对读和写的操作并不是很高效,这样就导致了数据访问的延迟,如果用户需要低延迟的数据访问建议不要使用HDFS















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









