







OK,之前主要是讲解了一下关于前端的知识的,如果你们还没看过的,可以先去看看前面的内容,因为真正的是干货,都是自己在学习的过程中觉得还不错的知识点就进行整理的。那么,我将对J2EE企业级中的几大框架进行知识点的讲解。首先,这一篇接我将讲解一下Hibernate框架的一些知识点,其余的框架将在后续进行整理。
咳咳,来说一说JDBC的一些缺点,然后引出Hibernate的原因。
(1)JDBC缺点:
1、代码比较繁琐
2、sql语句平台的移植性不是很强
3、没有data pool(数据缓存)
4、当jdbc调用mysql的存储过程的时候,存储过程本身移植性比较差
5、没有做到面向对象开发
(2)Hibernate优点:
1、面向对象的编程
2、缓存
重点
一级缓存 二级缓存 查询缓存
如果数据量不是特别大
hibernate缓存
oscache 不支持分布式缓存
ehcache 不支持分布式缓存
redis 分布式缓存
memorycache 分布式缓存
3、代码操作比较简单
4、平台的移植性比较强
(3)Hibernate缺点:如果该项目对sql的优化要求特别高,不适合用hibernate
如果数据库的数据量特别大,也不适合用hibernate
如果表与表之间的关系比较复杂,也不能用hibernate来做
首先讲一下Hibernate框架搭建的步骤,然后再细细的对其中的内容进行讲解:
(1)导包
(2)准备实体类(也就是一般中的JavaBean类) 以及 orm元数据
(3)创建主配置文件
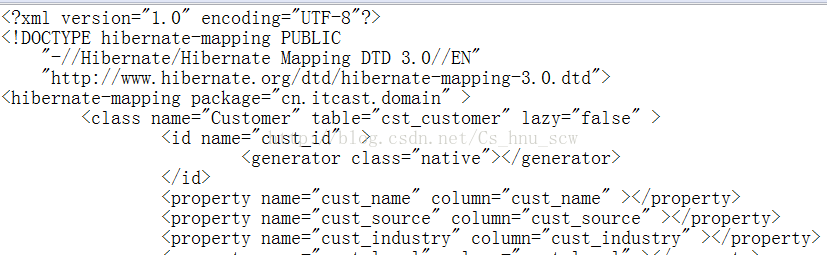
1:Hibernate中的数据库表与实体对象的映射配置详解(ORM元数据)<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<!-- 配置表与实体对象的关系 -->
<!-- package属性:填写一个包名.在元素内部凡是需要书写完整类名的属性,可以直接写简答类名了. -->
<hibernate-mapping package="cn.itheima.domain" >
<!--
class元素: 配置实体与表的对应关系的
name: 完整类名
table:数据库表名
-->
<class name="Customer" table="cst_customer" >
<!-- id元素:配置主键映射的属性
name: 填写主键对应属性名
column(可选): 填写表中的主键列名.默认值:列名会默认使用属性名
type(可选):填写列(属性)的类型.hibernate会自动检测实体的属性类型.
每个类型有三种填法: java类型|hibernate类型|数据库类型
not-null(可选):配置该属性(列)是否不能为空. 默认值:false
length(可选):配置数据库中列的长度. 默认值:使用数据库类型的最大长度
-->
<id name="cust_id" >
<!-- generator:主键生成策略 -->
<generator class="native"></generator>
</id>
<!-- property元素:除id之外的普通属性映射
name: 填写属性名
column(可选): 填写列名
type(可选):填写列(属性)的类型.hibernate会自动检测实体的属性类型.
每个类型有三种填法: java类型|hibernate类型|数据库类型
not-null(可选):配置该属性(列)是否不能为空. 默认值:false
length(可选):配置数据库中列的长度. 默认值:使用数据库类型的最大长度
-->
<property name="cust_name" column="cust_name" >
<!-- <column name="cust_name" sql-type="varchar" ></column> -->
</property>
<property name="cust_source" column="cust_source" ></property>
<property name="cust_industry" column="cust_industry" ></property>
<property name="cust_level" column="cust_level" ></property>
<property name="cust_linkman" column="cust_linkman" ></property>
<property name="cust_phone" column="cust_phone" ></property>
<property name="cust_mobile" column="cust_mobile" ></property>
</class>
</hibernate-mapping>2:Hibernate主配置(位置:写在src下面的一个xml文件,并且名字要为hibernate.cfg.xml)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!--
#hibernate.dialect org.hibernate.dialect.MySQLDialect
#hibernate.dialect org.hibernate.dialect.MySQLInnoDBDialect
#hibernate.dialect org.hibernate.dialect.MySQLMyISAMDialect
#hibernate.connection.driver_class com.mysql.jdbc.Driver
#hibernate.connection.url jdbc:mysql:///test
#hibernate.connection.username gavin
#hibernate.connection.password
-->
<!-- 数据库驱动 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<!-- 数据库url -->
<property name="hibernate.connection.url">jdbc:mysql:///hibernate_32</property>
<!-- 数据库连接用户名 -->
<property name="hibernate.connection.username">root</property>
<!-- 数据库连接密码 -->
<property name="hibernate.connection.password">1234</property>
<!-- 数据库方言
不同的数据库中,sql语法略有区别. 指定方言可以让hibernate框架在生成sql语句时.针对数据库的方言生成.
sql99标准: DDL 定义语言 库表的增删改查
DCL 控制语言 事务 权限
DML 操纵语言 增删改查
注意: MYSQL在选择方言时,请选择最短的方言.
-->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- #hibernate.show_sql true
#hibernate.format_sql true
-->
<!-- 将hibernate生成的sql语句打印到控制台 -->
<property name="hibernate.show_sql">true</property>
<!-- 将hibernate生成的sql语句格式化(语法缩进) -->
<property name="hibernate.format_sql">true</property>
<!--
## auto schema export 自动导出表结构. 自动建表
#hibernate.hbm2ddl.auto create 自动建表.每次框架运行都会创建新的表.以前表将会被覆盖,表数据会丢失.(开发环境中测试使用)
#hibernate.hbm2ddl.auto create-drop 自动建表.每次框架运行结束都会将所有表删除.(开发环境中测试使用)
#hibernate.hbm2ddl.auto update(推荐使用) 自动生成表.如果已经存在不会再生成.如果表有变动.自动更新表(不会删除任何数据).
#hibernate.hbm2ddl.auto validate 校验.不自动生成表.每次启动会校验数据库中表是否正确.校验失败.
-->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 引入orm元数据
路径书写: 填写src下的路径
-->
<mapping resource="cn/itheima/domain/Customer.hbm.xml" />
</session-factory>
</hibernate-configuration>(1)Configuration对象
public void fun1(){
//1 创建,调用空参构造
Configuration conf = new Configuration();
//2 读取指定主配置文件 => 空参加载方法,加载src下的hibernate.cfg.xml文件
conf.configure();
//3 读取指定orm元数据(扩展),如果主配置中已经引入映射配置.不需要手动加载
//conf.addResource(resourceName);
//conf.addClass(persistentClass);
//4 根据配置信息,创建 SessionFactory对象
SessionFactory sf = conf.buildSessionFactory();
} SessionFactory功能: 用于创建操作数据库核心对象session对象的工厂.
简单说功能就一个---创建session对象
注意:1.sessionfactory 负责保存和使用所有配置信息.消耗内存资源非常大.
2.sessionFactory属于线程安全的对象设计.
3:sessionFactory是单例模式
4:sessionFatory封装的信息全部都是公共的
结论: 保证在web项目中,只创建一个sessionFactory.
下面代码就是两种获取Session对象的方法。区别两个方法的不同点。
//5 获得session
//打开一个新的session对象
sf.openSession();
//获得一个与线程绑定的session对象
sf.getCurrentSession();稍微讲解一下关于openSession()方法的细节内容:

2、这种方式效率不是很高
3、利用这种方式很容器的就可以操作session的缓存
这里重点分析一下关于第二种方法getCurrentSession()的详细内容(非常重要,里面用到的设计模式很经典):
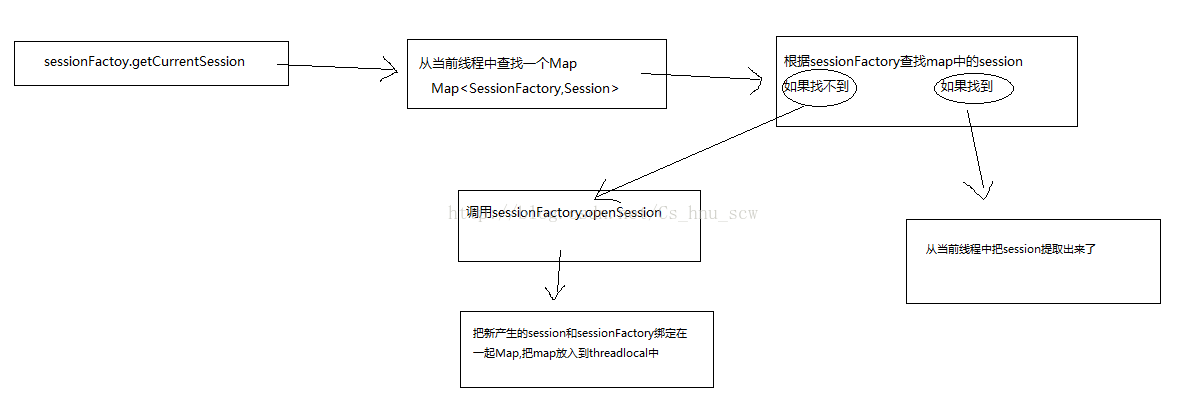
从上面的简化图,应该就能明白具体改方法做了些什么了,如果想了解更加详细的执行过程,就可以根据该方法进入源码进行阅读了。
好了,这里说一下,为什么要把Session对象放入到threadloacl对象中,有以下几个好处:
1、把session放入到threadlocal中,确保线程安全
2、在整个线程中可以共享session,并且该session只有一个
3、在threadlocal中存放Map<SessionFactory,Session>,因为整个hibernate应用sessionFactory只有一个,所以session肯定只有一个
咳咳,注意了,如果要用getCurrentSession()方法的话,可不是直接调用这个方法就可以了的,是需要进行下面的配置的,否则就会报错报错报错!!!
第一步:在hibernate.cfg.xml文件中添加一个属性配置
<property name="current_session_context_class">thread</proerty>第三步:在进行完crud操作的事务commit()操作之后,不需要手动再进行session对象的close()方法,这是会自动关闭的,如果手动关闭了,会报错。-----------这个嘛,就把事务和session对象给绑定了,也有不好的地方,比如在事务提交之后,还想操作session的话,这样就是不行的了。也正是这个原因,后面在Spring框架的时候,对这个设置可以进行了配置修改。
(3)Session对象(主要就是进行与数据库之间的CRUD操作)
session对象功能: 表达hibernate框架与数据库之间的连接(会话).session类似于JDBC年代的connection对象. 还可以完成对数据库中数据的增删改查操作。创建一个session相当于打开一个数据库连接,关闭session就相当于关闭一个数据库连接。
session是hibernate操作数据库的核心对象
//4 session获得操作事务的Transaction对象
//获得操作事务的tx对象
//Transaction tx = session.getTransaction();
//开启事务并获得操作事务的tx对象(建议使用)
Transaction tx2 = session.beginTransaction();
//----------------------------------------------
//----------------------------------------------
tx2.commit();//提交事务
tx2.rollback();//回滚事务
session.close();//释放资源
sf.close();//释放资源1:添加数据
public void fun2(){
//1 创建,调用空参构造
Configuration conf = new Configuration().configure();
//2 根据配置信息,创建 SessionFactory对象
SessionFactory sf = conf.buildSessionFactory();
//3 获得session
Session session = sf.openSession();
//4 session获得操作事务的Transaction对象
//获得操作事务的tx对象
//Transaction tx = session.getTransaction();
//开启事务并获得操作事务的tx对象(建议使用)
Transaction tx2 = session.beginTransaction();
//----------------------------------------------
Customer c = new Customer();
c.setCust_name("我是第一个测试哦");
session.save(c);
//----------------------------------------------
tx2.commit();//提交事务
session.close();//释放资源
sf.close();//释放资源
} //----------------------------------------------
Customer customer = session.get(Customer.class, 1l);
System.out.println(customer);
//----------------------------------------------//----------------------------------------------
//1 获得要修改的对象
Customer c = session.get(Customer.class, 1l);
//2 修改
c.setCust_name("哈哈");
//3 执行update
session.update(c);
//----------------------------------------------//----------------------------------------------
//1 获得要修改的对象
Customer c = session.get(Customer.class, 1l);
//2 调用delete删除对象
session.delete(c);
//----------------------------------------------(4)Transaction对象(主要功能:打开事务,提交事务,回滚事务,这上面的session中已经进行了代码的演示了,可以翻上去看看,比较简单)
在Hibernate中,默认是关闭的,必须手动打开。(JDBC也是默认不打开的,所以才会发生很多多线程处理的问题)
4:封装获取session对象的工具方法(这个在开发中是需要的,因为都需要有工具类,这样能够优化程序)
public class HibernateUtils {
private static SessionFactory sf;
static{
//1 创建,调用空参构造
Configuration conf = new Configuration().configure();
//2 根据配置信息,创建 SessionFactory对象
sf = conf.buildSessionFactory();
}
//获得session => 获得全新session
public static Session openSession(){
//3 获得session
Session session = sf.openSession();
return session;
}
//获得session => 获得与线程绑定的session
public static Session getCurrentSession(){
//3 获得session
Session session = sf.getCurrentSession();
return session;
}5:Hibernate中的实体类的JavaBean的编写规则
(1)持久化类提供无参数构造,(非常重要,必须有个无参构造,否则就会在Hibernate操作的时候出现问题)
(2)成员变量私有,提供公有的Get、Set方法,需提供属性(注意一个JavaBean中什么才叫做属性?只有当是get、set方法得到的才是叫属性,比如private String name,这只能叫做成员变量,而不是属性,只有当有setName这个方法或者GetName这方法的时候,才能将这个称作属性,这可是面试常考的哦!!)
(3)持久化类中的属性,应尽量使用包装类型(包装类型,可以防止由于读取到数据库中的null字段而引起的异常)
(4)持久化类需要提供oid,与数据库中的主键对应(没有主键的数据库,是无法映射到Hibernate当中的)
(5)不要用final修饰class(因为Hibernate是通过CGlib来实现的动态代理生成对象,代理对象是继承被代理的对象)
6:主键类型
(1)自然主键(少见):数据库中表的业务中,有某业务列符合主键的规范,则称为自然主键(比如人的身份证号,学号这些)
(2)代理主键(常见):数据库中表中,没有业务列符合主键的规范,则需要创建一个没有意义的列,则称为代理主键(比如数据库中的id这个列,一般都没有实际意义。)
7:Hibernate中对主键生成策略(7种,主要就是在xml配置文件中进行控制)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itheima.domain" >
<class name="Customer" table="cst_customer" >
<id name="cust_id" >
<!-- generator:主键生成策略.就是每条记录录入时,主键的生成规则.(7个)
identity : 主键自增.由数据库来维护主键值.录入时不需要指定主键.
sequence: Oracle中的主键生成策略.
increment(了解): 主键自增.由hibernate来维护.每次插入前会先查询表中id最大值.+1作为新主键值.
hilo(了解): 高低位算法.主键自增.由hibernate来维护.开发时不使用.
native:hilo+sequence+identity 自动三选一策略.
uuid: 产生随机字符串作为主键. 主键类型必须为string 类型.
assigned:自然主键生成策略. hibernate不会管理主键值.由开发人员自己录入.
-->
<generator class="increment"></generator>
</id>
<property name="cust_name" column="cust_name" ></property>
<property name="cust_source" column="cust_source" ></property>
<property name="cust_industry" column="cust_industry" ></property>
<property name="cust_level" column="cust_level" ></property>
<property name="cust_linkman" column="cust_linkman" ></property>
<property name="cust_phone" column="cust_phone" ></property>
<property name="cust_mobile" column="cust_mobile" ></property>
</class>
</hibernate-mapping>(1)瞬时(临时)状态:没有id,没有与session关联----------------------肯定是从new创建来的
(2)持久化状态:有id,有与session关联
(3)游离|托管状态:有id,没有与session关联-----------------------肯定是从持久化状态转换过来的
上面三种状态的互相转变:
瞬时----》持久化----------------------通过session中的save()方法
持久化---》游离----------------------通过session中的close()/clear()/evcit()方法
游离----》持久化------------------- 通过session中的update()方法
持久化---》瞬时---------------------通过session中的delete()方法
直接到持久化-----------------------通过session中的get()方法
文字变成图就可以利用下面这个来看清楚一点了。

实例分析:用一个例子来说明上面理论的分析:
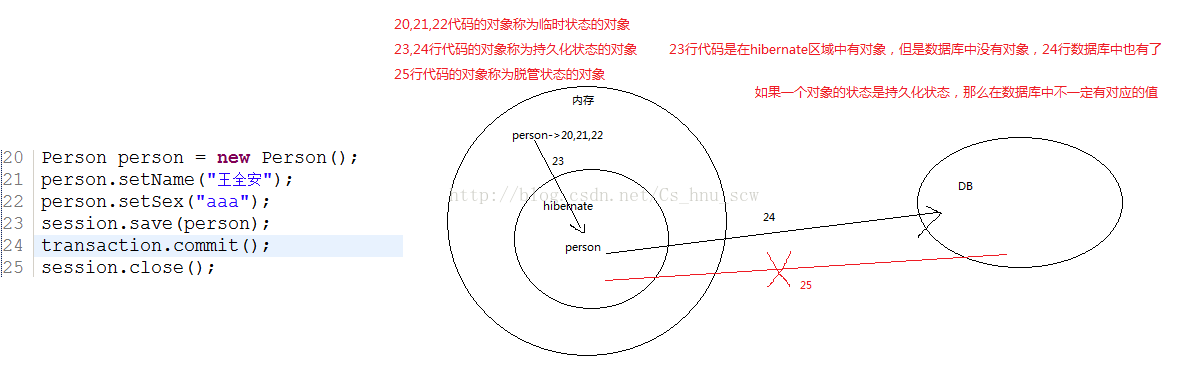
再说一个知识点,就是关于session的flush()方法的原理.。当执行session.flush方法的时候,hibernate内部会检查所有的持久化对象会判断该对象和数据库有没有对应的数据(根据标示符id),如果没有则发出insert语句,如果有,则再让该对象和副本进行对比,如果和副本一样,则什么都不做,如果不一样,则发出update语句session.flush的时候,只不过是向数据库发送了sql语句,但是值在数据库中并不存在。
9:Hibernate的一级缓存
功能:提高效率
(1)提高查询效率
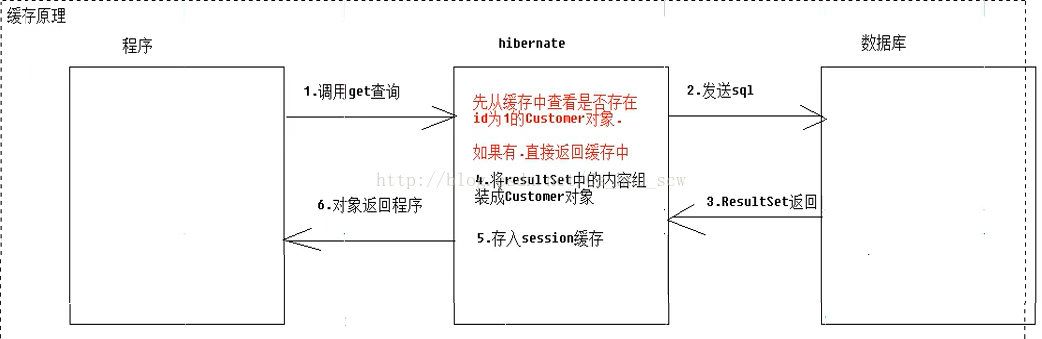
(2)减少不必要的修改语句的发送(通过快照)
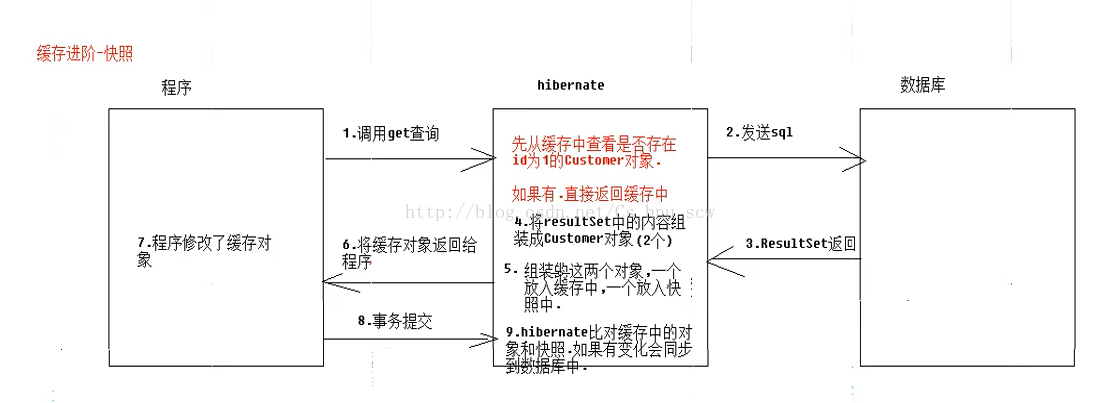
缓存的类型:
(1)对象缓存:把对象的标示符作为key值,把对象本身作为value值
(2)数据缓存:可以把sql语句作为key值,把结果作为value值
Hibernate的一级缓存的测试实例:
先写一个获取SessionFactory的工具类(主要是用于方便获取Session对象)
package com.itheima11.hibernate.utils;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtils {
public static SessionFactory sessionFactory;
static{
Configuration configuration = new Configuration();
configuration.configure();
sessionFactory = configuration.buildSessionFactory();
}
}测试代码:
public class SessionCacheTest extends HibernateUtils{
@Test
public void testGet(){
Session session = sessionFactory.openSession();
Person person = (Person)session.get(Person.class, 1L);//发出sql语句
person = (Person)session.get(Person.class, 1L);//没有发出sql语句 该对象来自于缓存
session.close();
}
/**
* 统计机制
*/
@Test
public void testStatistics(){
Session session = sessionFactory.openSession();
Person person = (Person)session.get(Person.class, 1L);//发出sql语句
System.out.println(session.getStatistics().getEntityCount());//计算hibernate的一级缓存中的对象的个数
session.close();
}
}咳咳,好了,现在总结一下知识点(面试会问的哦),通过上面的例子,我们可以看到:
(1):执行session.get()方法的时候,会把对象放入到一级缓存中
(2):当session执行get(),save(),update(),list()方法的时候,都会把对象放入到一级缓存(如果想测试的话,也很简单,类似那面的写法进行不断的输入缓存里面的对象个数的值就能够明白了)
(3):当session执行evict(),close(),clear()方法的时候,都会清除一级缓存中的对象
(4):咱们再联系一下关于hibernate中对象的三种状态,然后再结合这一级缓存知识,难道没有发现什么相关联的东西吗?
答案就是(敲黑板):其实只要对象是持久化状态,那么就在一级缓存中,这就是为什么第(2)点和第(3)点会有这样的结论。所以,总结起来就是,判断是否存在于一级缓存中,就看是否是执行了持久化状态的操作,这样就能够把Hibernate的对象状态和一级缓存技术知识连起来。是不是是不是一下就明白了两个知识点,是否很开心呢?这个可是在面试的时候经常问到的问题哦。
10:hibernate中的批量查询(概述)
(1)HQL语句:hibernate特有的语句(使用于多表但不复杂的查询)
下面通过例子来进行说明不同情况的查询方法(大家请仔细看,区别原生的SQL语句):
//基本查询
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
// String hql = " from cn.itheima.domain.Customer "; //如果名字都没有重复的,则可以利用下面的语句
String hql = " from Customer "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//3> 根据查询对象获得查询结果
List<Customer> list = query.list(); // 返回list结果
//query.uniqueResult();//接收唯一的查询结果
System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//条件查询
//HQL语句中,不可能出现任何数据库相关的信息的
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer where cust_id = 1 "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//3> 根据查询对象获得查询结果
Customer c = (Customer) query.uniqueResult();
System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
//条件查询
//问号占位符
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer where cust_id = ? "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//设置参数
//query.setLong(0, 1l);
query.setParameter(0, 1l);
//3> 根据查询对象获得查询结果
Customer c = (Customer) query.uniqueResult();
System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//条件查询
//命名占位符
public void fun4(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer where cust_id = :abc "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//设置参数
query.setParameter("abc", 1l);
//3> 根据查询对象获得查询结果
Customer c = (Customer) query.uniqueResult();
System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//分页查询
public void fun5(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//设置分页信息 limit ?,?
query.setFirstResult(1);
query.setMaxResults(1);
//3> 根据查询对象获得查询结果
List<Customer> list = query.list();
System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}下面也同样用例子来进行解析:
//基本查询
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//查询所有的Customer对象
Criteria criteria = session.createCriteria(Customer.class); //参数是实体类,也就是对应的数据库中的JavaBean
List<Customer> list = criteria.list();
System.out.println(list); //返回多条数据使用
// Customer c = (Customer) criteria.uniqueResult(); //返回唯一的值使用
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//条件查询
//HQL语句中,不可能出现任何数据库相关的信息的
// > gt
// >= ge
// < lt
// <= le
// == eq
// != ne
// in in
// between and between
// like like
// is not null isNotNull
// is null isNull
// or or
// and and
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//创建criteria查询对象
Criteria criteria = session.createCriteria(Customer.class);
//添加查询参数 => 查询cust_id为1的Customer对象
criteria.add(Restrictions.eq("cust_id", 1l));
//执行查询获得结果
Customer c = (Customer) criteria.uniqueResult();
System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//分页查询
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//创建criteria查询对象
Criteria criteria = session.createCriteria(Customer.class);
//设置分页信息 limit ?,?
criteria.setFirstResult(1);
criteria.setMaxResults(2);
//执行查询
List<Customer> list = criteria.list();
System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//查询总记录数
public void fun4(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//创建criteria查询对象
Criteria criteria = session.createCriteria(Customer.class);
//设置查询的聚合函数 => 总行数
criteria.setProjection(Projections.rowCount());
//执行查询
Long count = (Long) criteria.uniqueResult();
System.out.println(count);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
}同样的,下面也通过实际的例子来进行讲解:
//基本查询
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer";
//2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql);
//3 调用方法查询结果
List<Object[]> list = query.list(); //这是原生的SQL返回的类型,在没有指定返回的类型时候,原生查询出来的就是object数组类型
//query.uniqueResult();
for(Object[] objs : list){
System.out.println(Arrays.toString(objs));
}
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//基本查询(查询返回的是JavaBean对象类型)
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer";
//2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql);
//指定将结果集封装到哪个对象中
query.addEntity(Customer.class);
//3 调用方法查询结果
List<Customer> list = query.list();
System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//条件查询
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer where cust_id = ? ";
//2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql);
query.setParameter(0, 1l);
//指定将结果集封装到哪个对象中
query.addEntity(Customer.class);
//3 调用方法查询结果
List<Customer> list = query.list();
System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}//分页查询
public void fun4(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer limit ?,? ";
//2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql);
query.setParameter(0, 0);
query.setParameter(1, 1);
//指定将结果集封装到哪个对象中
query.addEntity(Customer.class);
//3 调用方法查询结果
List<Customer> list = query.list();
System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}(1)一对多的关系(比如客户与联系人的关系)
客户的xml中的配置:
<!-- 集合,一对多关系,在配置文件中配置 -->
<!--
name属性:集合属性名
column属性: 外键列名
class属性: 与我关联的对象完整类名
-->
<!--
级联操作: cascade
save-update: 级联保存更新
delete:级联删除
all:save-update+delete
级联操作: 简化操作.目的就是为了少些两行代码.
-->
<!-- inverse属性: 配置关系是否维护.
true: customer不维护关系
false(默认值): customer维护关系
inverse属性: 性能优化.提高关系维护的性能.
原则: 无论怎么放弃,总有一方必须要维护关系.
一对多关系中: 一的一方放弃.也只能一的一方放弃.多的一方不能放弃.
-->
<set name="linkMens" inverse="true" cascade="delete" >
<key column="lkm_cust_id" ></key>
<one-to-many class="LinkMan" />
</set>联系人的xml中的配置:
<!-- 多对一端的xml配置(其中那些属性的配置是和正常的是一样的都需要进行配置的) -->
<!--
name属性:引用属性名
column属性: 外键列名
class属性: 与我关联的对象完整类名
-->
<!--
级联操作: cascade
save-update: 级联保存更新
delete:级联删除
all:save-update+delete
级联操作: 简化操作.目的就是为了少些两行代码.
-->
<!-- 多的一方: 不能放弃维护关系的.外键字段就在多的一方. -->
<many-to-one name="customer" column="lkm_cust_id" class="Customer" >
</many-to-one>总结:
1、一般情况下,一对多,多的一方维护关系,效率比较高
2、一对多,如果一的一方维护关系,实际上就是发出更新外键的update语句
3、如果多的一方维护关系,实际上就是更新了多的一方所对应表的所有的字段
4、一般情况下,一的一方的文件中,针对set集合的invserse的值为true,不维护关系
(2)多对对关系(比如用户和角色关系)注意事项:在多对多中,对于表的维护,一定只需要一方进行维护第三方表,而不能两方都同时维护,会出错用户实体的xml配置:
说明:
1、关系操作
增加关系相当于在第三张表中插入一行数据
解除关系相当于在第三张表中删除一行数据
更新关系 相当于 先删除后增加
谁维护关系,效率都一样,看页面的需求
2、级联操作
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.domain" >
<class name="User" table="sys_user" >
<id name="user_id" >
<generator class="native"></generator>
</id>
<property name="user_code" ></property>
<property name="user_name" ></property>
<property name="user_password" ></property>
<property name="user_state" ></property>
<!-- 多对多关系表达 -->
<!--
name: 集合属性名
table: 配置中间表名
key
|-column:外键,别人引用"我"的外键列名
class: 我与哪个类是多对多关系
column:外键.我引用比人的外键列名
-->
<!-- cascade级联操作:
save-update: 级联保存更新
delete:级联删除
all:级联保存更新+级联删除
结论: cascade简化代码书写.该属性使不使用无所谓. 建议要用只用save-update.
如果使用delete操作太过危险.尤其在多对多中.不建议使用.
-->
<set name="roles" table="sys_user_role" cascade="save-update" >
<key column="user_id" ></key>
<many-to-many class="Role" column="role_id" ></many-to-many>
</set>
</class>
</hibernate-mapping><?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.domain" >
<class name="Role" table="sys_role" >
<id name="role_id" >
<generator class="native"></generator>
</id>
<property name="role_name" ></property>
<property name="role_memo" ></property>
<!-- 使用inverse属性
true: 放弃维护外键关系
false(默认值):维护关系
结论: 将来在开发中,如果遇到多对多关系.一定要选择一方放弃维护关系.
一般谁来放弃要看业务方向. 例如录入员工时,需要为员工指定所属角色.
那么业务方向就是由员工维护角色. 角色不需要维护与员工关系.角色放弃维护
-->
<set name="users" table="sys_user_role" inverse="true" >
<key column="role_id" ></key>
<many-to-many class="User" column="user_id" ></many-to-many>
</set>
</class>
</hibernate-mapping>
总结:1、多对多的结构是三张表
2、映射文件中,与一对多的配置也不一样,需要指定一个第三张表的联系
3、多对多,谁维护关系,效率都一样
4、多对多是类与集合的关系
12:查询的进阶操作
(1)HQL语句:
单表查询操作:
//基本语法
@Test
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = " from cn.itcast.domain.Customer ";//完整写法
String hql2 = " from Customer "; //简单写法
String hql3 = " from java.lang.Object "; //查询所有的对象实体的语句
Query query = session.createQuery(hql3);
List list = query.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}//排序
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql1 = " from cn.itcast.domain.Customer order by cust_id asc ";//完整写法
String hql2 = " from cn.itcast.domain.Customer order by cust_id desc ";//完整写法
Query query = session.createQuery(hql2);
List list = query.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}//条件查询
public void fun3(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql1 = " from cn.itcast.domain.Customer where cust_id =? ";//完整写法
String hql2 = " from cn.itcast.domain.Customer where cust_id = :id ";//完整写法
Query query = session.createQuery(hql2);
// query.setParameter(0, 2l);
query.setParameter("id", 2l);
List list = query.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}//分页查询
public void fun4(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql1 = " from cn.itcast.domain.Customer ";//完整写法
Query query = session.createQuery(hql1);
//limit ?,?
// (当前页数-1)*每页条数
query.setFirstResult(2);
query.setMaxResults(2);
List list = query.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}//统计查询
//count 计数
//sum 求和
//avg 平均数
//max
//min
public void fun5(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql1 = " select count(*) from cn.itcast.domain.Customer ";//完整写法
String hql2 = " select sum(cust_id) from cn.itcast.domain.Customer ";//完整写法
String hql3 = " select avg(cust_id) from cn.itcast.domain.Customer ";//完整写法
String hql4 = " select max(cust_id) from cn.itcast.domain.Customer ";//完整写法
String hql5 = " select min(cust_id) from cn.itcast.domain.Customer ";//完整写法
Query query = session.createQuery(hql5);
Number number = (Number) query.uniqueResult(); //这里用了Number类型来接受,主要是考虑上面可能出现Long和Int型,在实际中用对应的字段类型即可。
System.out.println(number);
//----------------------------------------------------
tx.commit();
session.close();
}//投影查询
public void fun6(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql1 = " select cust_name from cn.itcast.domain.Customer "; //查询某个字段的内容数据,返回的是对应字段的类型数据
String hql2 = " select cust_name,cust_id from cn.itcast.domain.Customer "; //查询多个字段的内容,返回的是object[] 的数组类型数据
String hql3 = " select new Customer(cust_id,cust_name) from cn.itcast.domain.Customer "; //查询多个字段,并且返回的是对象类型的数据。通过这样的方式,返回的是customer对象,注意必须在对应的实体中,存在对于的构造方法,否则报错。
Query query = session.createQuery(hql3);
List list = query.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}编写一个非常强大的Dao层的一个方法,实现能够通用查询(也就是只要给实体类和查询数据,就能够实现对应表的数据的查询,这个在DAO层的查询方法非常方便)
private void testQueryClasses_Where_AnyCondition(Class className,Map<String, String> variables){
StringBuffer stringBuffer = new StringBuffer();
/**
* 通过className得到该实体类的字符串形式
*/
stringBuffer.append("from "+sessionFactory.getClassMetadata(className).getEntityName());
stringBuffer.append(" where 1=1");
/**
* 动态的拼接查询语句,如果一个属性的值为"",则不往条件中添加
*/
for (Entry<String, String> entry : variables.entrySet()) {
if(!entry.getValue().equals("")){//如果属性不为""
stringBuffer.append(" and "+entry.getKey()+"=:"+entry.getKey());
}
}
Session session = sessionFactory.openSession();
Query query = session.createQuery(stringBuffer.toString());
/**
* 动态的给条件赋值
*/
for (Entry<String, String> entry : variables.entrySet()) {
if(!entry.getValue().equals("")){
query.setParameter(entry.getKey(), entry.getValue());
}
}
List<Classes> classes = query.list();
System.out.println(classes.size());
session.close();
}
@Test
public void testQueryEntry_Where_AnyCondition(){
/**
* Map<String,String>
* key为持久化对象的属性
* value为持久化对象的属性的值
*/
Map<String, String> variables = new HashMap<String, String>();
variables.put("name", "");
variables.put("description", "");
this.testQueryClasses_Where_AnyCondition(Classes.class,variables);//只需要传入实体类的类和数据,就能够实现相应的查询
}/**
* 元数据
* 数据仓库
*/
@Test
public void testClassMetaData(){
/**
* ClassMetaData可以得到持久化类的信息
* 标示符的名称
* 一般属性的名称
* 。。。。。
*/
Map<String,ClassMetadata> map = sessionFactory.getAllClassMetadata();
for (Entry<String, ClassMetadata> entry : map.entrySet()) {
System.out.println(entry.getKey());
ClassMetadata classMetadata = entry.getValue();
System.out.println("entityName:"+classMetadata.getEntityName()); //获取到对应实体的类名
System.out.println("identityName:"+classMetadata.getIdentifierPropertyName()); //获取到主键的名字
String[] propertiesNames = classMetadata.getPropertyNames(); //获取到实体类对应数据库中的名称
for (String string : propertiesNames) {
System.out.println(string);
}
}
ClassMetadata classMetadata = sessionFactory.getClassMetadata(Classes.class);
System.out.println(classMetadata.getEntityName());
}HQL中的多表查询语法:
先贴一下关于多表查询的一些知识点://回顾-原生SQL
// 交叉连接-笛卡尔积(避免)
// select * from A,B
// 内连接
// |-隐式内连接
// select * from A,B where b.aid = a.id
// |-显式内连接
// select * from A inner join B on b.aid = a.id
// 外连接
// |- 左外
// select * from A left [outer] join B on b.aid = a.id
// |- 右外
// select * from A right [outer] join B on b.aid = a.id//HQL 内连接 => 将连接的两端对象分别返回.放到数组中.
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = " from Customer c inner join c.linkMens ";
Query query = session.createQuery(hql);
List<Object[]> list = query.list();
for(Object[] arr : list){
System.out.println(Arrays.toString(arr));
}
//----------------------------------------------------
tx.commit();
session.close();
}//HQL 迫切内连接 => 帮我们进行封装.返回值就是一个对象
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = " from Customer c inner join fetch c.linkMens ";
Query query = session.createQuery(hql);
List<Customer> list = query.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}//HQL 左外连接 => 将连接的两端对象分别返回.放到数组中.
public void fun3(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = " from Customer c left join c.linkMens ";
Query query = session.createQuery(hql);
List<Object[]> list = query.list();
for(Object[] arr : list){
System.out.println(Arrays.toString(arr));
}
//----------------------------------------------------
tx.commit();
session.close();
}//HQL 右外连接 => 将连接的两端对象分别返回.放到数组中.
public void fun4(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = " from Customer c right join c.linkMens ";
Query query = session.createQuery(hql);
List<Object[]> list = query.list();
for(Object[] arr : list){
System.out.println(Arrays.toString(arr));
}
//----------------------------------------------------
tx.commit();
session.close();
}基本查询:
//基本语法
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Criteria c = session.createCriteria(Customer.class);
List<Customer> list = c.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//条件语法
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Criteria c = session.createCriteria(Customer.class);
// c.add(Restrictions.idEq(2l));
c.add(Restrictions.eq("cust_id",2l));
List<Customer> list = c.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//分页语法 - 与HQL一样
public void fun3(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Criteria c = session.createCriteria(Customer.class);
//limit ?,?
c.setFirstResult(0);
c.setMaxResults(2);
List<Customer> list = c.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//排序语法
public void fun4(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Criteria c = session.createCriteria(Customer.class);
c.addOrder(Order.asc("cust_id"));
//c.addOrder(Order.desc("cust_id"));
List<Customer> list = c.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//统计语法
public void fun5(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Criteria c = session.createCriteria(Customer.class);
//设置查询目标
c.setProjection(Projections.rowCount());
List list = c.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}
用一个小例子来解析上面的这个图的内容:

public void fun1(){
//模拟为Service/web层
DetachedCriteria dc = DetachedCriteria.forClass(Customer.class);
dc.add(Restrictions.idEq(6l));//拼装条件(全部与普通Criteria一致)
//----------------------------------------------------
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Criteria c = dc.getExecutableCriteria(session);
List list = c.list();
System.out.println(list);
//----------------------------------------------------
tx.commit();
session.close();
}下面的13,14,15这三个小点的内容都是属于查询优化(包括单表,一对多的关系,多对多的关系)中的内容哦,可以看看!!!!!这个在面试的时候一般用于回答Hibernate可以从哪些方面进行优化效率!!!
13:类级别的加载策略(立即加载和懒加载策略)
立即加载:当session进行使用get方法时,立即进行数据库对应的查询操作
懒加载:当session进行load方法时,并不是直接马上进行数据库的操作,而是产生一个代理对象,当使用这个对象的时候,才进行真正的数据库的操作。
(1)session的get()方法。(不存在懒加载策略,只有立即加载策略)
// get方法 : 立即加载.执行方法时立即发送sql语句查询结果
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Customer c = session.get(Customer.class, 2l);
System.out.println(c);
//----------------------------------------------------
tx.commit();
session.close();
}// load方法(默认):是在执行时,不发送任何sql语句.返回一个对象.使用该对象时,才执行查询.
// 延迟加载: 仅仅获得没有使用.不会查询.在使用时才进行查询.
// 是否对类进行延迟加载: 可以通过在class元素上配置lazy属性来控制.
//lazy:true 加载时,不查询.使用时才查询b
//lazy:false 加载时立即查询.
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Customer c = session.load(Customer.class, 2l);
//----------------------------------------------------
tx.commit();
session.close();
System.out.println(c);
}
上面的lazy属性可以为:true(实施懒加载策略);false(不实施懒加载策略);extra(针对需要进行什么操作,就发出对应的SQL语句,比较有针对性,比如查数据的条数,那么就只会发出select count from XXXX这种语句)三种
结论:懒加载策略是为了提高效率(关键就是控制SQL语句是什么时候进行发出)。但是要注意的就是,再进行懒加载策略的时候要确保session是打开的,否则会抛出异常。
14:关联级别的策略(抓取策略)
(1)集合策略(也就是一对多的关系中存在的策略,这里是配置多的那一方的内容)
xml中的配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.domain" >
<class name="Customer" table="cst_customer" lazy="false" >
<id name="cust_id" >
<generator class="native"></generator>
</id>
<property name="cust_name" column="cust_name" ></property>
<property name="cust_source" column="cust_source" ></property>
<property name="cust_industry" column="cust_industry" ></property>
<property name="cust_level" column="cust_level" ></property>
<property name="cust_linkman" column="cust_linkman" ></property>
<property name="cust_phone" column="cust_phone" ></property>
<property name="cust_mobile" column="cust_mobile" ></property>
<!--
lazy属性: 决定是否延迟加载
true(默认值): 延迟加载,懒加载
false: 立即加载
extra: 极其懒惰
fetch属性: 决定加载策略.使用什么类型的sql语句加载集合数据
select(默认值): 单表查询加载
join: 使用多表查询加载集合
subselect:使用子查询加载集合
-->
<set name="linkMens" fetch="select" lazy="true" >
<key column="lkm_cust_id" ></key>
<one-to-many class="LinkMan" />
</set>
</class>
</hibernate-mapping>//集合级别的关联
//fetch:select 单表查询
//lazy:true 使用时才加载集合数据.
@Test
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Customer c = session.get(Customer.class, 2l);
Set<LinkMan> linkMens = c.getLinkMens();//关联级别
System.out.println(linkMens);
//----------------------------------------------------
tx.commit();
session.close();
}
//集合级别的关联
//fetch:select 单表查询
//lazy:false 立即记载集合数据
@Test
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Customer c = session.get(Customer.class, 2l);
Set<LinkMan> linkMens = c.getLinkMens();//关联级别
System.out.println(linkMens);
//----------------------------------------------------
tx.commit();
session.close();
}
//集合级别的关联
//fetch:select 单表查询
//lazy:extra 极其懒惰.与懒加载效果基本一致. 如果只获得集合的size.只查询集合的size(count语句)
@Test
public void fun3(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Customer c = session.get(Customer.class, 2l);
Set<LinkMan> linkMens = c.getLinkMens();//关联级别
System.out.println(linkMens.size());
System.out.println(linkMens);
//----------------------------------------------------
tx.commit();
session.close();
}
//集合级别的关联
//fetch:join 多表查询
//lazy:true|false|extra 失效.立即加载.
@Test
public void fun4(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
Customer c = session.get(Customer.class, 2l);
Set<LinkMan> linkMens = c.getLinkMens();//关联级别
System.out.println(linkMens.size());
System.out.println(linkMens);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//fetch: subselect 子查询
//lazy: true 懒加载
public void fun5(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = "from Customer";
Query query = session.createQuery(hql);
List<Customer> list = query.list();
for(Customer c:list){
System.out.println(c);
System.out.println(c.getLinkMens().size());
System.out.println(c.getLinkMens());
}
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//fetch: subselect 子查询
//lazy: false 立即加载
public void fun6(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = "from Customer";
Query query = session.createQuery(hql);
List<Customer> list = query.list();
for(Customer c:list){
System.out.println(c);
System.out.println(c.getLinkMens().size());
System.out.println(c.getLinkMens());
}
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//fetch: subselect 子查询
//lazy: extra 极其懒惰
public void fun7(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = "from Customer";
Query query = session.createQuery(hql);
List<Customer> list = query.list();
for(Customer c:list){
System.out.println(c);
System.out.println(c.getLinkMens().size());
System.out.println(c.getLinkMens());
}
//----------------------------------------------------
tx.commit();
session.close();
}
一对多关系中,一的那方的xml中的配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.domain" >
<class name="LinkMan" table="cst_linkman" >
<id name="lkm_id" >
<generator class="native"></generator>
</id>
<property name="lkm_gender" ></property>
<property name="lkm_name" ></property>
<property name="lkm_phone" ></property>
<property name="lkm_email" ></property>
<property name="lkm_qq" ></property>
<property name="lkm_mobile" ></property>
<property name="lkm_memo" ></property>
<property name="lkm_position" ></property>
<!--
fetch 决定加载的sql语句
select: 使用单表查询
join : 多表查询
lazy 决定加载时机
false: 立即加载
proxy: 由customer的类级别加载策略决定. //也就是看一对多关系中,多的那一方中的xml配置中的class中的lazy属性配置的参数内容
-->
<many-to-one name="customer" column="lkm_cust_id" class="Customer" fetch="join" lazy="proxy" >
</many-to-one>
</class>
</hibernate-mapping>@Test
//fetch:select 单表查询
//lazy:proxy
//customer-true 懒加载
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
LinkMan lm = session.get(LinkMan.class, 3l);
Customer customer = lm.getCustomer();
System.out.println(customer);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//fetch:join 多表
//lazy: 失效
public void fun3(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
LinkMan lm = session.get(LinkMan.class, 3l);
Customer customer = lm.getCustomer();
System.out.println(customer);
//----------------------------------------------------
tx.commit();
session.close();
}
@Test
//fetch:select 单表查询
//lazy:proxy
//customer-false 立即加载
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
LinkMan lm = session.get(LinkMan.class, 3l);
Customer customer = lm.getCustomer();
System.out.println(customer);
//----------------------------------------------------
tx.commit();
session.close();
}15:批量抓取(含义:对于一对多的关联查询中,设置要查询关联表中的数据个数,避免每次都需要查询关联表内容,优化程序)
在关系为多的一方中的xml中的配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.domain" >
<class name="Customer" table="cst_customer" lazy="false" >
<id name="cust_id" >
<generator class="native"></generator>
</id>
<property name="cust_name" column="cust_name" ></property>
<property name="cust_source" column="cust_source" ></property>
<property name="cust_industry" column="cust_industry" ></property>
<property name="cust_level" column="cust_level" ></property>
<property name="cust_linkman" column="cust_linkman" ></property>
<property name="cust_phone" column="cust_phone" ></property>
<property name="cust_mobile" column="cust_mobile" ></property>
<!-- batch-size: 抓取集合的数量为3. 可以设置为任意个数
抓取客户的集合时,一次抓取几个客户的联系人集合.
-->
<set name="linkMens" batch-size="3" >
<key column="lkm_cust_id" ></key>
<one-to-many class="LinkMan" />
</set>
</class>
</hibernate-mapping>@Test
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//----------------------------------------------------
String hql = "from Customer ";
Query query = session.createQuery(hql);
List<Customer> list = query.list();
//效果就在下面,大家可以打断点在下面进行Debug的测试,看看设置上面抓取数量参数和没设置的区别哦!!如果没有设置的话,每次循环就要进行一次访问关联表(这里就是LinkMen)的操作,而设置了之后,那么就可以一次性把设置的个数的抓取数量的内容获取,而不需要每次去获取。是不是方便了哦?
for(Customer c:list){
System.out.println(c.getLinkMens());
}
//----------------------------------------------------
tx.commit();
session.close();
}
16:解析Hibernate的加载流程
咳咳,上面这些内容已经足够使用Hibernate了,但是没发现,少了点什么吗?那就是Hibernate到底是如何基于JDBC而进行的操作CRUD的呢?下面就用一个简单的例子结合图进行分析下。

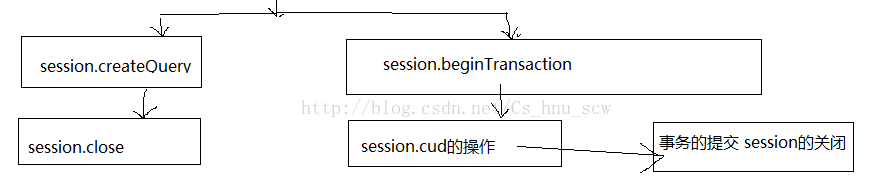
Hibernate的内部加载过程:(以插入数据为例子分析)
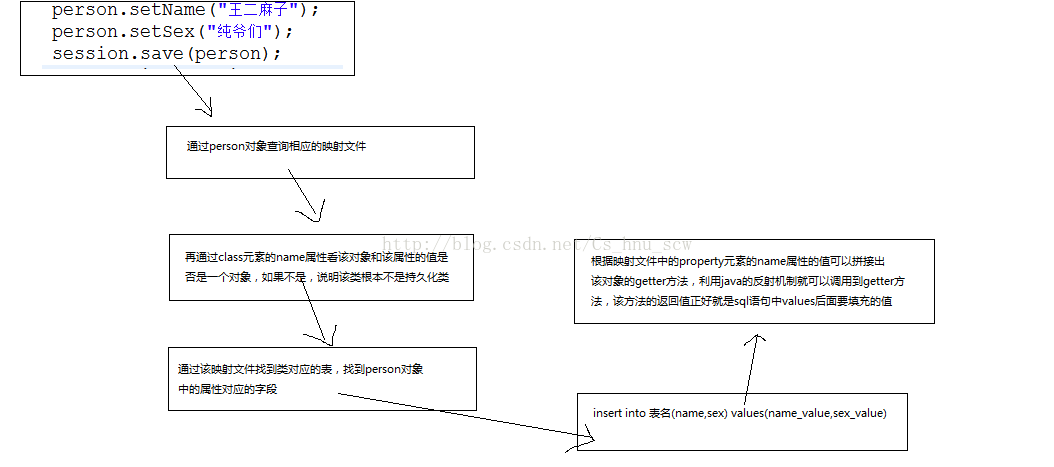
十七:二级缓存机制的详细分析
(1)存放在二级缓存中的数据的一些特点
1、公共的数据
2、不经常修改的数据
3、私密性不是很高的数据
(2)二级缓存的生命周期
当Hibernate程序开始的时候,二级缓存就存在了;当Hibernate容器销毁的时候,二级缓存就销毁了。
(3)使用二级缓存的步骤
因为在Hibernate内部中,默认是没有提供二级缓存的实现的,默认情况下,使用的是ehcache缓存机制(关于这个机制,可以百度一下,进行了解,主要的是这种缓存机制有两种缓存方式:内存和硬盘缓存,这样的话对于很大的数据的时候是一种非常好的解决方案)。
1:在Hibernate配置文件中,添加如下的属性标签
<!-- 开启二级缓存 -->
<property name="cache.use_second_level_cache">true</property>
<!-- 配置缓存供应商-->
<property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property>2:开启类级别的缓存配置
方法一:在Hibernate.cg.xml中进行配置
<!-- 开启类级别的缓存 -->
<class-cache usage="read-only" class="com.scw.model.student"/>对上面的属性解释一下:
usage----->设置二级缓存的缓存策略
read-only----->只能进行读数据,无法进行写数据的操作;如果要能够配置可以进行写的话,就使用read-write
class-------->需要进行二级缓存的类的全路径
方法二:在Hibernate对应的类的映射文件中,在设置主键的前面,添加如下的标签内容(重点掌握)
<cache usage="read-only"/>(4)类级别操作的分析
在前面已经说过了关于一级缓存的原理和详细的内容了。对于二级缓存的话,其实没有过多的内容可以介绍。在一级缓存中,提到save,update,get,list方法都会将对象放置到一级缓存中(记住,一级缓存是私有的,别被单纯的名字给蒙蔽了,所以要理解一级缓存到底的实质作用是干嘛,它并不是说是存储了一份在容器中,然后再访问的时候就可以直接获取,而实质作用在于,是可以减少SQL语句的多次与数据库的操作,而是能够一次性进行交互,这样就节省了很多的资源了),然而对于二级缓存的话,只有get,list两个方法才会把对象放入到二级缓存中,所以这个是需要区分一下关于两者的差别的。
(5)简单介绍一下关于ehcache的缓存配置文件(注意,这个配置文件中是不能够有注释的,所以真的要使用的时候记得把注释给去掉,我这里只是为了看起来方便而已)
编译一个ehcache.xml文件
<diskStore path="e:\\TEMP1"/> 在磁盘上的存储路径
<defaultCache
maxElementsInMemory="12" 在内存中最大可以存储多少对象
eternal="false"
timeToIdleSeconds="1200"
timeToLiveSeconds="1200"
overflowToDisk="false" 如果内存中超过了最大的对象数,是否存储到磁盘上
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>
<Cache
name="com.itheima10.hibernate.domain.Classes"
maxElementsInMemory="3"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>十八:查询缓存的详细解析
作用:提高获取查询结果的效率。
注意点:(1)针对Query对象的list()方法才能够起效,而对于Iterate()方法无论是查询属性还是对象都没有效果,
(2)将查询到的内容的ID放置到查询缓存中,查询缓存缓存的key是HQL语句,缓存的value值是查询到结果的ID这样下次当有list()查询的时候,就会先去从查询缓存的ID进行匹配,如果缓存命中的话,就会去从二级缓存中获取(如果开启了二级缓存的情况,则不会发出SQL语句,而是直接从缓存中进行获取)否则的话,就会去数据库中进行查询手。查询缓存保存的是结果集的id列表,而不是结果集本身。
使用方法:(1)在Hibernate.cfg.xml配置文件中,添加如下的标签。
<property name="hibernate.cache.use_query_cache">true</property>例如下面的一个测试代码:
@Test
public void testList(){
Session session = sessionFactory.openSession();
Query query = session.createQuery("select name from Classes");
query.setCacheable(true);//可以访问查询缓存
query.list();
session.close();
session = sessionFactory.openSession();
query = session.createQuery("select name from Classes");
query.setCacheable(true);//可以访问查询缓存
query.list();
session.close();
}十九:一级缓存,二级缓存,查询缓存的对比与总结(干货,面试必问的内容)
(1)缓存的类别
一级缓存:Session级别
二级缓存:SessionFactory级别
查询缓存:不固定,因为如果当session对象进行了update方法之后,那么数据就进行了改变,那么查询缓存中的内容就会失效;同理,对于SessionFactory来说的话,要看是否有二级缓存的设置,毕竟查询缓存是基于二级缓存的基础之上来的,二级缓存的是否开启对于查询缓存是否进行缓存操作也是有影响的。
(2)生命周期
一级缓存:与Session对象共生,私有化的
二级缓存:与SessionFatory一致
查询缓存:不固定,如果数据库的数据有变化,那么查询缓存就会失效。并且对于相同的属性结果集查询和对象结果集查询,它们进行的查询缓存都不一样。
(3)使用方法
一级缓存:Hibernate自带,不需要进行配置
二级缓存:上面小点知识内容已经介绍
查询缓存 :上面小点知识内容已经介绍
(4)缓存保存的内容
一级缓存:实体对象
二级缓存:实体对象
查询缓存:查询出来的实体的部分属性结果集和实体的ID(注意这里不是实体)
(5)使用对象
一级缓存:save,list,get,update方法
二级缓存:只有查询方法,get(),list()
查询缓存:只有list()方法
大体列举了,这三种缓存的不同点,然后关于它们三者的具体内容,在上面的知识点中,都有进行了详细的讲解,如果不是很明白的可以回头看看上面的内容哦。
上面这些就是整理出来关于hibernate框架的干货知识点了,如果认真看了的话,我想应该对于如何使用这个框架和整个框架的知识点应该都有大概的了解的,在正常使用中应该都没什么问题,关于这个框架深层次中的知识点,我还会继续进行更新的。当我们在用框架的时候,会用是一方面,但是还是应该知道知其所以然这样才比较好。大家一起努力呗!!!!!!















 2215
2215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









