






1. Filter 过滤法
过滤方法通常用做预处理步骤,特征选择完全独立于任何机器学习算法。是根据各种统计检验中的分数以及相关性的各项指标来选择特征的。
1.1 方差过滤
通过特征本身的方差来筛选特征。若一个特征的方差很小,说明样本在这个特征上的差异性较小,可能特征中大部分数值相近,那么这个特征对于样本区分没有太大作用。所以方差过滤是消除方差为0或者很小的特征。
1.1.1 VarianceThreshold
feature_selection.VarianceThreshold中有一个参数VarianceThreshold,表示方差的阈值,舍弃所有方差小于threshold的特征,默认为0,为0的话就是删除所有记录都相同的特征。
#用到的数据集是digit recognizer.csv,Kaggle下载
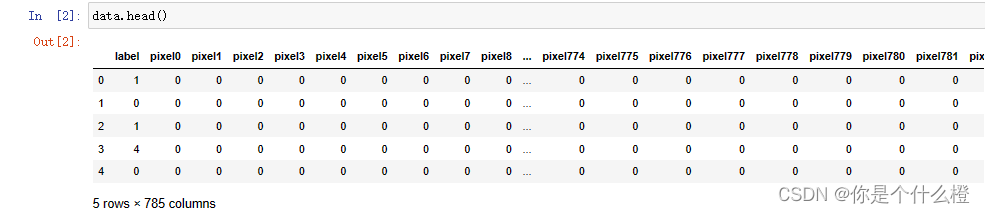
import pandas as pd
data = pd.read_csv(r"D:\Python\Python程序\digit recognizer.csv ")
data.head()
X = data.iloc[:,1:]
Y = data.iloc[:,0]
X.shape #(42000, 784)
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数
X_var0 = selector.fit_transform(X) # 获取特征选择后的新特征矩阵
X_var0.shape #维度变成708,少了76个特征
Out:(42000, 708)
阈值设置为方差的中位数:
#假设我们要去掉一半的特征,则阈值设置为方差的中位数
import numpy as np
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X) # 参数为中位数
X_fsvar.shape
Out:(42000, 392)
当特征是二分类时,特征的取值就是伯努利随机变量,变量的方差可以计算为:
其中X是特征矩阵,p是二分类特征中的一类在这个特征中所占的概率。
# 若特征是伯努利随机变量,假设p=0.8,即二分类特征中某种分类占到80%以上的时候删除特征
X_bvar = VarianceThreshold(0.8 *(1- 0.8)).fit_transform(X)
X_bvar.shape
Out:(42000, 685)
1.1.2方差过滤对模型的影响
用knn和随机森林分别在方差过滤前后效果和运行时间对比
KNN:
# knn vs 随机森林 在不同的方差过滤下的效果
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
import numpy as np
X = data.iloc[:,1:]
Y = data.iloc[:,0]
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
#方差过滤前:
cross_val_score(KNN(),X, Y, cv = 5).mean() # 0.9658
0.9658
#在jupter中用%%timeit来计算运行这个cell中的代码所需要的时间
%%timeit
cross_val_score(KNN(),X, Y, cv = 5).mean() # 33min
# 方差过滤后:
cross_val_score(KNN(),X_fsvar, Y, cv = 5).mean() # 0.9659
%%timeit
cross_val_score(KNN(),X_fsvar, Y, cv = 5).mean() # 20min
准确率上升了一点,时间缩短了。
随机森林:
#方差过滤前:
cross_val_score(RFC(n_estimators = 10, random_state = 0),X, Y, cv = 5).mean() # 0.93800
%%timeit
cross_val_score(RFC(n_estimators = 10, random_state = 0),X, Y, cv = 5).mean() # 11.5s
# 方差过滤后:
cross_val_score(RFC(n_estimators = 10, random_state = 0),X_fsvar, Y, cv = 5).mean() # 0.93880
%%timeit
cross_val_score(RFC(n_estimators = 10, random_state = 0),X_fsvar, Y, cv = 5).mean() # 11.1s
准确率上升了一点,时间缩短不明显。
观察到: 随机森林的准确率低于KNN,运行时间连KNN的1%不到。方差过滤后KNN的运行时间明显缩短,而随机森林的运行时间几乎不变。
KNN,单棵决策树,支持向量机SVM,神经网络,回归算法这些都需要遍历特征或者升维来计算,本身运算量就大,所以用特征选择减少维度有位重要。随机森林不需要遍历特征,随机选取特征进行分枝,本身运算就快,所以特征选择对它效果一般。无论如何减少特征的数量,随机森林也只会选取固定数量的特征来建模。
一般而言,我们会使用阈值很小或者0的方差过滤,优先消除一些明显用不到的特征,然后再用更优的特征选择方法继续削减特征数量。
1.2 相关性过滤
选择与标签相关且有意义的特征。在sklearn中有三种方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
1.2.1 卡方过滤
卡方过滤是专门针对离散型标签(分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并按照卡方统计量由高到低为特征排名。feature_selection.SelectKBest可以输入”评分标准“来选择前K个分数高的特征,由此可以去除与分类目的无关的特征。
如果卡方检验检测到某个特征中所有的值都相同,会提示先进行方差过滤。上面已经验证过方差过滤一半特征后模型的表现提升,因此使用阈值为中位数的方差过滤后的数据来做卡方检验:
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 假设我们知道需要300个特征
X_fschi = SelectKBest(chi2, k = 300).fit_transform(X_fsvar, Y)
X_fschi.shape
Out:(42000, 300)`
cross_val_score(RFC(n_estimators = 10, random_state = 0), X_fschi, Y, cv = 5).mean()
Out:0.9344
模型的效果降低了,说明我们设置K=300时删除了与模型相关性高的特征。因此,我们要么需要调整K值,要么放弃相关性过滤。
如何选取超参数K呢?
- 使用学习曲线:
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(390, 200, -10):
X_fschi = SelectKBest(chi2, k = i).fit_transform(X_fsvar, Y)
once = cross_val_score(RFC(n_estimators = 10, random_state = 0), X_fschi, Y, cv = 5).mean()
score.append(once)
plt.plot(range(390, 200,-10),score)
plt.show()
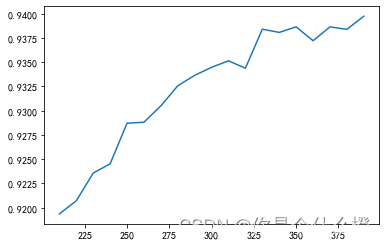
观察到:曲线呈现单调增长的情况,K越大,模型的表现越好。数据中所有的特征都是相关的。
- 看p值选择K:
p值一般使用0.01和0.05作为显著性水平,即p值判断的边界。p<=0.05或者0.01,两组数据相关;p>0.05或者0.01,两组数据独立。
chivalue, pvalues_chi = chi2(X_fsvar, Y)
chivalue #卡方值
pvalues_chi #p值
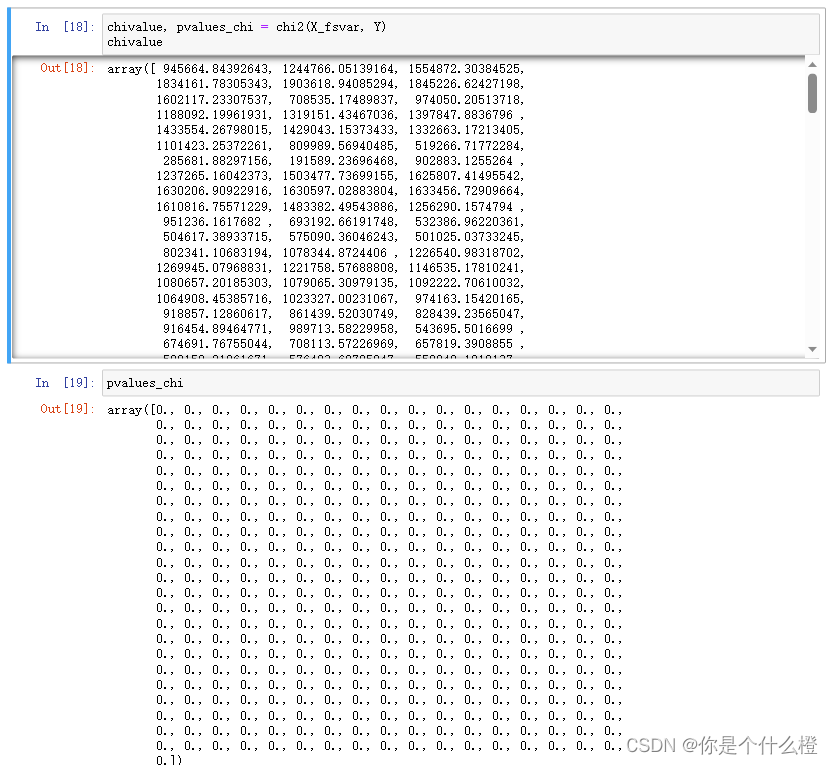
观察到:所有特征的p值都是0,说明所有的特征都是相关的。
# k取值为想要消除的所有p值大于设定值
k = chivalue.shape[0] - (pvalues_chi >0.05).sum()
'''
chivalue.shape[0]表示所有卡方的数量,即特征数量 392
pvalues_chi >0.05 返回True,False,True=1,False=0
True求和,减去后就是想要保留的特征数量
'''
1.2.2 F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间线性关系的过滤方法。既可以做回归(F检验分类,feature_selection.f_classif),也可以做分类(F检验回归,feature_selection.f_regression)。F检验分类用于标签是离散型变量的数据,F检验回归用于标签是连续型变量的数据。
F检验在数据服从正态分布时效果稳定,所以一般使用F检验前会先标准化,把数据转换成服从正态分布的方式。
其原假设是“数据不存在显著的线性关系”,返回F值和p值两个统计量。我们希望选取p值小于0.05或0.01的特征,这些特征与标签显著线性相关;p值大于0.05或0.01的特征则认为是和标签没有显著线性关系的标签,应被删除。
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar, Y) #得到F值和p值
k = F.shape[0] - (pvalues_f >0.05).sum() #设置k值
K值结果为392。
得到的结果与卡方过滤得到的一模一样。没有任何特征的p值大于0.05,所有特征相关,因此不需要相关性过滤。
1.2.3 互信息法
互信息法用来捕捉特征与标签之间任意关系(包括线性和非线性关系)的过滤方法。可以做回归和分类:feature_selection.mutual_info_classif(互信息分类)和feature_selection.mutual_info_regression(互信息回归)。它返回“每个特征与目标之间的互信息量的估计”,是0-1之间的取值,0表示两个变量独立,1表示两个变量完全相关。
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar, Y)
k = result.shape[0] - sum(result <=0)
得到的结果为392。所有特征的互信息量估计都大于0,因此所有特征都与标签相关。
2. Embedded 嵌入法
嵌入法让算法自己决定使用那些特征,即特征选择和算法训练同时进行。使用算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。比如决策树和树的集成模型中的feature_importanes_,可以列出各个特征对树的贡献,我们可以基于这种贡献的评估,找出对模型建立最有用的特征。嵌入法会更加精确到模型效用本身,对提高模型效力具有更好的效果。并且无关的特征(需要相关性过滤的特征)和无区分度的特征(需要方差过滤的特征)都会因为缺乏对模型的贡献而被删除,可谓是过滤法的进化版。但是嵌入法中使用的权值系数很难去界定一个临界值,可以通过学习曲线去找。
Embedded嵌入法使用的是feature_selection.SelectFromMedel。SelectFromMedel是一个元变化器,可以与任何在拟合后具有coef_,feature_importances_属性或者参数中具有惩罚项的评估器一起使用。比如随机森林和树模型就具有属性feature_importances_,逻辑回归带有l1和l2惩罚项,线性支持向量机有l2惩罚项。对于有feature_importances_的模型来说,若重要性低于提供的阈值参数,则认为这些特征不重要而被移除。feature_importances_的取值范围是[0,1],如果设置阈值很小,比如0.001,则可以删除那些对标签预测完全没有贡献的特征。
这边用随机森林和决策树模型的嵌入法。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators = 10, random_state = 0) #随机森林的实例化
X_embedded = SelectFromModel(RFC_, threshold = 0.005).fit_transform(X, Y) #得到选择的特征
#这边0.005对于780个特征数据来说,是非常高的阈值
X_embedded.shape # (42000, 47) 维度明显降低
#画学习曲线,寻找最佳阈值
import numpy as np
import matplotlib.pyplot as plt
steps = np.linspace(0, (RFC_.fit(X,Y).feature_importances_).max(),20) #在0-最大权值之间找20个数
score = []
for i in steps:
X_embedded = SelectFromModel(RFC_, threshold=i).fit_transform(X,Y)
once = cross_val_score(RFC_, X_embedded, Y, cv = 5).mean()
score.append(once)
fig = plt.figure(figsize=(20, 5))
steps_2 = [str(i) for i in steps]
plt.xticks(rotation=30)
plt.plot(steps_2, score)
plt.show()
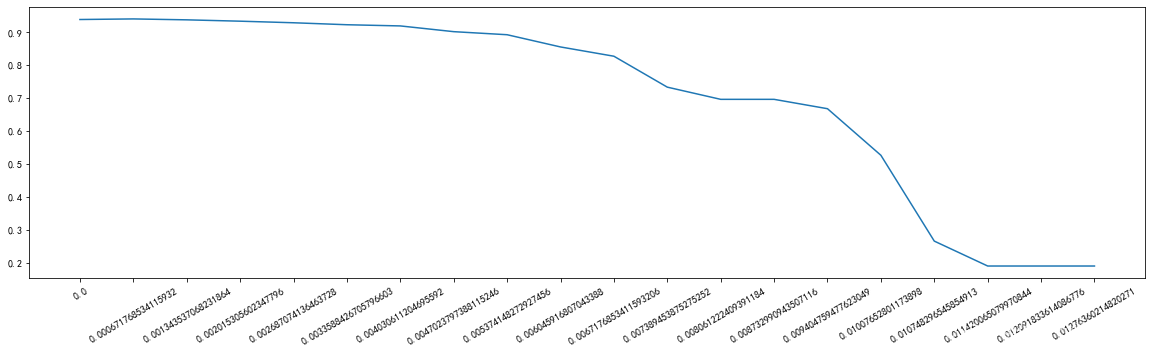
选择阈值为0.00067尝试一下
X_embedded = SelectFromModel(RFC_, threshold = 0.00067).fit_transform(X, Y)
X_embedded.shape
(42000, 324)
cross_val_score(RFC_, X_embedded, Y, cv = 5).mean()
0.9391190476190475
特征个数缩小到324,比方差过滤选择中位数过滤出的392列要小,交叉验证分数0.9391高于方差过滤后的结果0.9388。这是因为嵌入法比过滤法更加深入到模型的具体表现。在调参时,也可以第一次学习曲线后划分范围进一步画学习曲线得到阈值。
3. 包装法
包装法也是一个特征选择与算法训练同时进行的方法,与嵌入法相似,依赖于算法自身的coef_,feature_importances_属性完成特征选择。但不同的是,包装法中使用一个目标函数帮助选取特征,而不是自己输入的某个评估指标或统计量的阈值。最典型的目标函数是递归特征消除法(Recursive feature elimination, RFE),feature_selection.RFE(estimator, n_features_to_select=None, step=1, verbose=0)。参数estiamtor是需要填写的实例化后的评估器,n_features_to_select是想要选择的特征个数,step表示每次迭代中希望移除的特征个数。RFE有两个重要的属性,.support:返回所有的特征是否最后被选中的布尔矩阵,.ranking:返回特征按数次迭代中综合重要性的排名。feature_selection.RFECV增加了交叉验证,添加了参数cv。
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators = 10, random_state = 0)#实例化
selector = RFE(RFC_, n_features_to_select = 340, step = 50).fit(X,Y)
X_wrapper = selector.transform(X)
cross_val_score(RFC_, X_wrapper, Y, cv = 5).mean()
0.9379761904761905
#学习曲线调参
score = []
for i in range(1,751,50):
X_wrapper = RFE(RFC_, n_features_to_select = i, step = 50).fit_transform(X,Y)
once = cross_val_score(RFC_, X_wrapper, Y, cv = 5).mean()
score.append(once)
plt.figure(figsize= [20,5])
plt.plot(range(1,751,50), score)
plt.xticks(range(1,751,50))
plt.show()

X_wrapper = RFE(RFC_, n_features_to_select = 50, step = 50).fit_transform(X,Y)
cross_val_score(RFC_, X_wrapper, Y, cv = 5).mean()
0.9066190476190477
















 8554
8554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











