







Reference:
https://github.com/baidu/DDParser
https://blog.csdn.net/qq_27590277/article/details/107853326
目录
依存句法分析简介
依存句法分析旨在通过分析句子中词语之间的依存关系来确定句子的句法结构。其中依存句法分析标注关系集合如下图所示:

于是一个实例如下图所示:
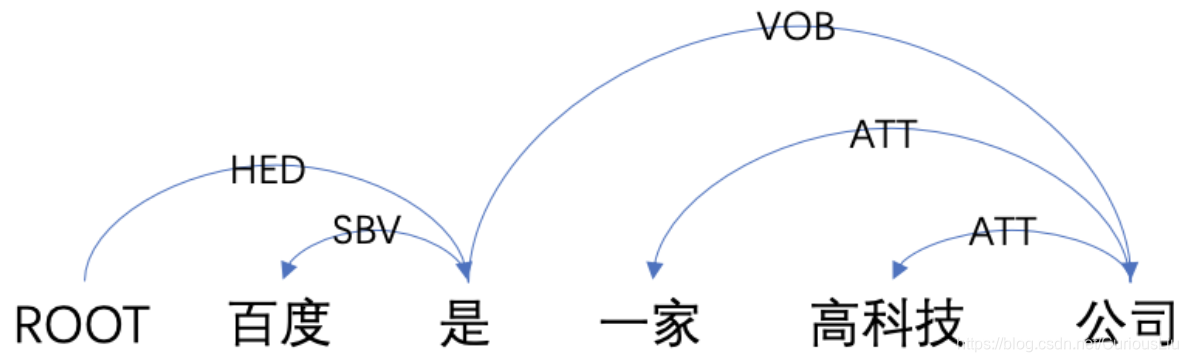
通过给出的依存句法分析标注关系集合可以进行对应:“是”这句话中的核心;“百度”和“是”之间存在主谓关系,“百度”是主语,“是”是谓语;“一家”、“高科技”和“公司”之间存在着定中关系(定语与中心词的关系),个人理解既可以说是“一家公司”,也可以说是“高科技公司”;“是”和“公司”之间存在着动宾关系。
依存句法分析作为底层技术,可直接用于提升其他NLP任务的效果,这些任务包括语义角色标注、语义匹配、事件抽取等。
项目介绍
此部分见作者github中
环境依赖安装+功能使用
1. 安装
依赖环境:
- python :>= 3.6.0
- paddlepaddle:1.8.2 百度深度学习框架
- LAC:>= 0.1.4

sudo python3 -m pip install paddlepaddle
sudo python3 -m pip install ddparser
2. 功能使用
基础方法
.parse()可以输出'word'经过分词的结果,还有依存句法中的'head'和'deprel',另外著名.parse()括号中的语句支持一个列表形式的word输入,例如['百度是一家高科技公司', '他送了一本书']
>>> from ddparser import DDParser
>>> ddp = DDParser()
>>> ddp.parse("百度是一家高科技公司")
[{'word': ['百度', '是', '一家', '高科技', '公司'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB']}]
>>> ddp.parse("C罗是最佳运动员,他来自皇家马德里,他带领皇马赢得了多个冠军,被誉为21世纪的球王")
[{'word': ['C罗', '是', '最佳', '运动员', ',', '他', '来自', '皇家', '马德里', ',', '他', '带领', '皇马', '赢得', '了', '多', '个', '冠军', ',', '被', '誉为', '21世纪', '的', '球王'], 'head': [2, 0, 4, 2, 2, 7, 2, 9, 7, 7, 12, 2, 12, 12, 14, 17, 18, 14, 14, 21, 14, 24, 22, 21], 'deprel': ['SBV', 'HED', 'ATT', 'VOB', 'MT', 'SBV', 'IC', 'ATT', 'VOB', 'MT', 'SBV', 'IC', 'DBL', 'DBL', 'MT', 'ATT', 'ATT', 'VOB', 'MT', 'POB', 'VV', 'ATT', 'MT', 'VOB']}]
>>> ddp.parse(["百度是一家高科技公司", "他送了一本书"])
[{'word': ['百度', '是', '一家', '高科技', '公司'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB']}, {'word': ['他', '送', '了', '一本', '书'], 'head': [2, 0, 2, 5, 2], 'deprel': ['SBV', 'HED', 'MT', 'ATT', 'VOB']}]扩展方法
在class DDParser()中指定参数prob和use_pos,使用prob可以指定输出概率,使用use_pos可以输出词性标签(类似于'ORG','n','v'等词性标签)
>>> from ddparser import DDParser
>>> ddp = DDParser(prob=True, use_pos=True)
>>> ddp.parse(["百度是一家高科技公司"])
[{'word': ['百度', '是', '一家', '高科技', '公司'], 'postag': ['ORG', 'v', 'm', 'n', 'n'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB'], 'prob': [1.0, 1.0, 1.0, 1.0, 1.0]}]在class DDParser中指定参数buckets=True可以在数据集长度不均时处理速度更快
>>> from ddparser import DDParser
>>> ddp = DDParser(buckets=True)在已分词情况下(可能更加信赖或者希望使用别的分词方法),通过调用parse_seg()方法,可以进行依存句法树分析
>>> from ddparser import DDParser
>>> ddp = DDParser()
>>> ddp.parse_seg([['百', '度', '是', '一家', '高科技', '公司'], ['他', '送', ' 了', '一本', '书']])
[{'word': ['百', '度', '是', '一家', '高科技', '公司'], 'head': [2, 3, 0, 6, 6, 3], 'deprel': ['ATT', 'SBV', 'HED', 'ATT', 'ATT', 'VOB']}, {'word': ['他', '送', '了', '一本', '书'], 'head': [2, 0, 2, 5, 2], 'deprel': ['SBV', 'HED', 'MT', 'ATT', 'VOB']}]
3. 依存句法树可视化在线(暂未尝试)
http://spyysalo.github.io/conllu.js/tests.html















 3160
3160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









