







数据
数据下载 https://download.csdn.net/download/CyAurora/21120767
001E8CB5AB11,ASUSTek,2018-07-1214:00:57,2018-07-1214:00:57,2018-07-1214:00:57,未知,僵尸屏,0
0023242DDEB7,其他,2018-07-1214:01:04,2018-07-1214:01:04,2018-07-1214:03:04,未知,僵尸屏,120....... ......
FEC0608F30DC,其他,2018-07-1214:02:51,2018-07-1214:02:51,2018-07-1214:02:51,未知-未知,广播,0
FEDE7582DCAF,其他,2018-07-1214:01:12,2018-07-1214:01:12,2018-07-1214:01:12,未知-未知,广播,0
FEEBB23B99E6,其他,2018-07-1214:01:56,2018-07-1214:01:56,2018-07-1214:01:56,未知-未知,广播,0
statr
import org.apache.spark.sqlimport org.apache.spark.sql.functions._object Query {
val ssc = new sql.SparkSession
.Builder()
.appName("query")
.master("local[2]")
.getOrCreate()
ssc.conf.set("spark.sql.shuffle.partitions", 6)
ssc.conf.set("spark.executor.memory", "6g")
ssc.sparkContext.setLogLevel("error")def main(args:Array[String]):Unit = {//读入文件并将其转换为DF
val fileName = "file:///E:\\工作\\WifiData\\data\\" + args(0) + "visit.txt"
val df_1 = ssc.read.option("headler", "false").option("inferschema", "true").csv(fileName)
.toDF("mac", "phone_brand", "enter_time", "first_time", "last_time", "region", "screen", "stay_long")}注:在使用函数的时候最好要导入org.apache.spark.sql.functions._这个包
import ssc.implicits._(这个包在实际写sql的时候将其导入
一、混合非聚合函数(misc non-aggregate functions)
1、abs:绝对值
import ssc.implicits._
df_1.selectExpr("abs(stay_long) as res_abs").show(5)
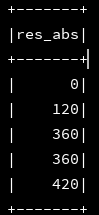
2、coalesce:返回第一列部位空的列值,源码解释如下:
/**Returns the first column that is not null, or null if all inputs are null.
* For example, `coalesce(a, b, c)` will return a if a is not null,
* or b if a is null and b is not null, or c if both a and b are null but c is not null.
import ssc.implicits._df_1.selectExpr("coalesce(mac,screen,stay_long) as res_colesce").show(5)
//手动将第一条记录的第一个字段置为空,则显示第二个字段值 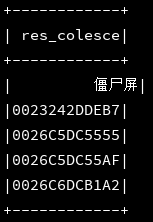
3、explode:Creates a new row for each element in the given array or map column.
3.1、有些时候我们需要使用sparksql来解析一些json文件,对于常规的无嵌套的json文件来说,比如:
|
|
val fileName = "E:\\工作\\WifiData\\data\\" + startDate + "visit.txt"
val df_numFile = ssc.read.json("file:///" + fileName)
df_numFile.select("*").show()

我们直接使用ssc.read.json("path")的方式进行读取,之后可以直接进行相关的sql进行查询。
但是对于嵌套类型的json文件,就感觉到有点吃力了,比如:
|
|
val fileName = "E:\\工作\\WifiData\\data\\" + startDate + "visit.txt"
val df_numFile = ssc.read.json("file:///" + fileName)
df_numFile.select("*").show()
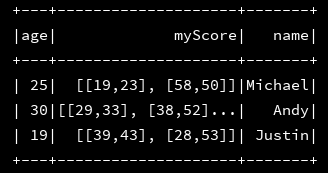
然而,这并不是我们想要的,这里explode函数有有用处了,将上面的代码修改一下
val fileName = "E:\\工作\\WifiData\\data\\" + startDate + "visit.txt"
val df_numFile = ssc.read.json("file:///" + fileName)
val df_score = df_numFile.select(df_numFile("name"),explode(df_numFile("myScore"))).toDF("name","myScore")
val dfMyScore = df_score.select("name","myScore.score1","myScore.score2")
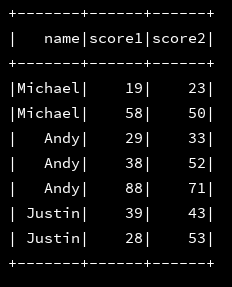
val fileName = "E:\\工作\\WifiData\\data\\" + startDate + "visit.txt"
val df_numFile = ssc.read.json("file:///" + fileName)
val df_score = df_numFile.select(df_numFile("name"),df_numFile("age"),explode(df_numFile("myScore"))).toDF("name","age","myScore")
val dfMyScore = df_score.select("name","age","myScore.score1","myScore.score2")
dfMyScore.select("*").show()<br>//再试一下...
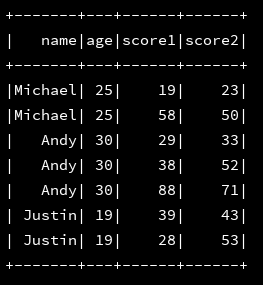
这会得到了正确的结果。
3.2、explode还可以将单列扩展成多行
参数可以是Array,可以是Map
ssc.sql(
"""
|select explode(Array("a","b","c","d"))
|from d1
""".stripMargin).show(4, false)
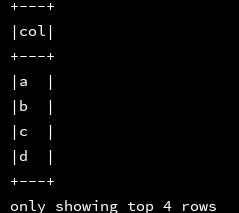
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select explode(Map("a","b"))
|from d1
""".stripMargin).show(4, false)
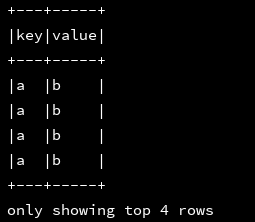
总结:explode该函数将指定 字段转换成DF的时候,是对应的整个表的列而不是该函数里面的字段对应里面的列数,这句话听起来比较绕口,把我自己都绕蒙了,还是得根据实例来理解
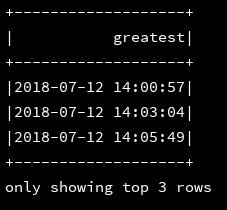
4、greatest:求列表中的最大值
源码解释:(Returns the greatest value of the list of values, skipping null values.This function takes at least 2 parameters. It will return null iff all parameters are null.)
注意:必须是同类型的才可以比较
df_1.select(greatest("enter_time","first_time","last_time") as("greatest")).show(3)
5、if:用于条件判断
源码解释:Returns valueTrue when testCondition is true, returns valueFalseOrNull otherwise.
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select enter_time,first_time,last_time,if(stay_long = 0,'x','y') as type from d1
""".stripMargin).show(3)
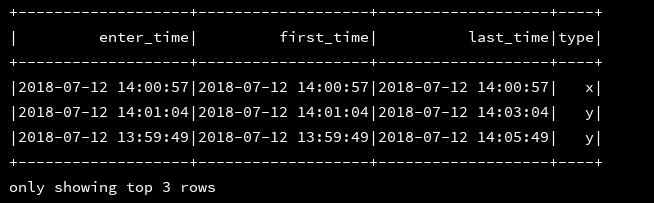
6、inline:
7、isnan:判断字段值是否为空
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select isnan(screen) as isnull,first_time,last_time,if(isnan(mac),1,2) as type from d1
""".stripMargin).show(3
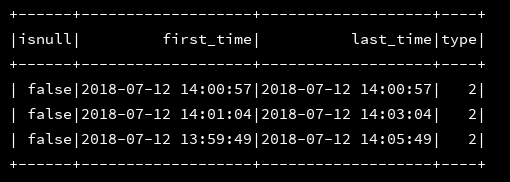
8、json_tuple():获取json中指定字段的值
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,json_tuple('{"a":"lihua","b":"wangming"}','a','b')
|from d1
|
""".stripMargin).show(4, false)如果需要对查询出的结果起别名,可以使用嵌套外层循环即可
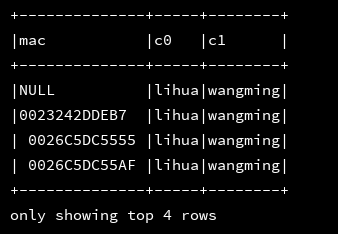
9、get_json_object():获取指定json路径的指定字符串的值,使用$.的方式
[JSON Path介绍](http://blog.csdn.net/koflance/article/details/63262484)
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,get_json_object('{"a":"lihua","b":"wangming"}','$.a') as valueOfJson
|from d1
|
""".stripMargin).show(4, false)
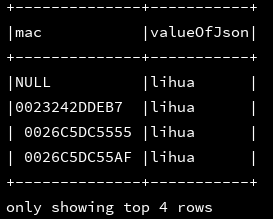
10、from_json:解析json字符串为StructType或ArrayType
二、字符函数
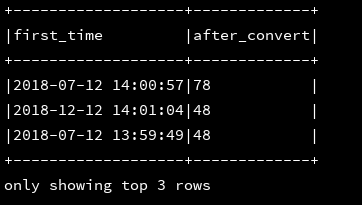
1、ascii(string str):返回str中第一个字符的ascii值
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,ascii(mac) as after_convert
|from d1
""".stripMargin).show(3, false)
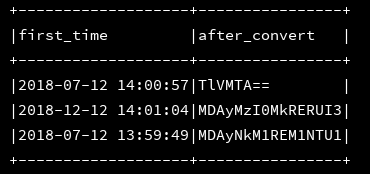
2、base64(column str):将str列进行base64编码作为字符串返回,与unbase64对应
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,base64(mac) as after_convert
|from d1
""".stripMargin).show(3, false)
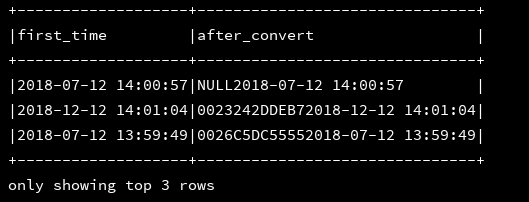
3、concat(string str1,string str2...):将多个字符串拼接为一个字符串
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,concat(mac,first_time) as after_convert
|from d1
""".stripMargin).show(3, false)
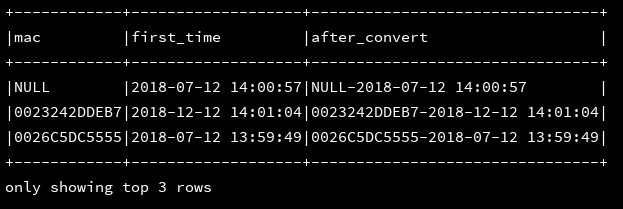
4、concat_ws:使用指定的连接符将多个字符拼接为一个字符
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,first_time,concat_ws('-',mac,first_time) as after_convert
|from d1
""".stripMargin).show(3, false)
5、encode(value:column,charset:string):转码,character支持的格式有:US-ASCII,ISO-8859-1,UTF-8,UTF-16BE,UTF-16LE,UTF-16
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,first_time,encode(mac,'ISO-8859-1') as after_convert
|from d1
""".stripMargin).show(3, false)
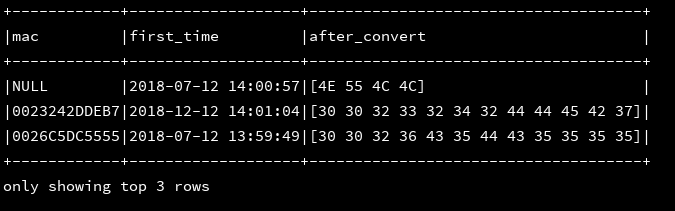
6、decode(value:column,charset:string):使用charset编码格式进行解码,支持的格式有:US-ASCII,ISO-8859-1,UTF-8,UTF-16BE,UTF-16LE,UTF-16
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,first_time,decode(encode(mac,'iso-8859-1'),'iso-8859-1') as after_convert
|from d1
""".stripMargin).show(3, false)
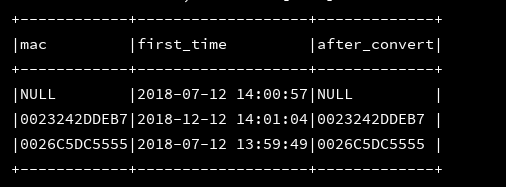
7、format_number(value:column,Int:d):实现对数字进行格式化,例如四舍五入保留d位小数,column必须是数组,不能是字符串
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,format_number(3.1415926,3) as after_convert
|from d1
""".stripMargin).show(3, false)

8、format_string(format:string,argument:column*):将column按照format进行格式化
目前我还不知道有么用处
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,format_string('%s',mac) as after_convert
|from d1
""".stripMargin).show(3, false)
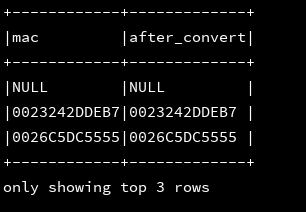
9、get_json_object():
10、initcap(column:str):将str字段的首个字母大写
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,initcap('asdfSDFcasdfASDf') as after_convert
|from d1
""".stripMargin).show(3, false)
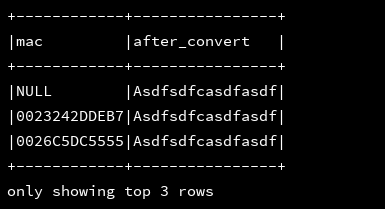
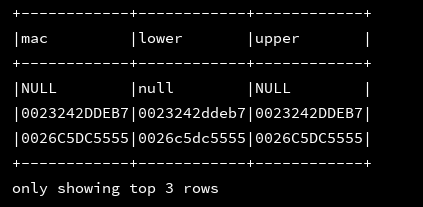
11、lower,upper:转大写,转小写
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,lower(mac) as lower,upper(mac) as upper
|from d1
""".stripMargin).show(3, false)
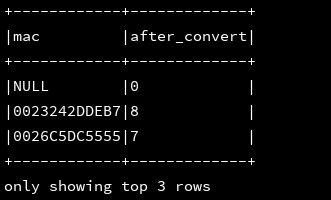
12、instr(str:column,substring:String):返回substring在str中第一次出现的位置(索引从1开始)
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,instr(mac,'D') as after_convert
|from d1
""".stripMargin).show(3, false)
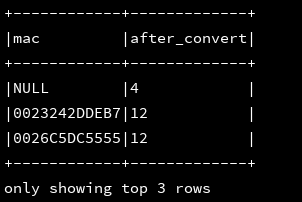
13、length:返回字符串的长度
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,length(mac) as after_convert
|from d1
""".stripMargin).show(3, false)
14、 levenshtein(l:column,r:column):计算两个字符串之间的编辑距离
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,first_time,levenshtein(mac,first_time) as after_convert
|from d1
""".stripMargin).show(3, false)

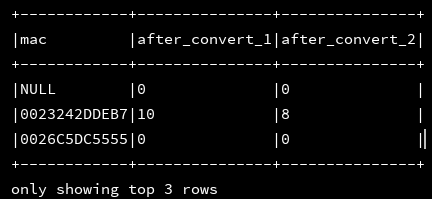
15、locate(substr:string,str:column,pos:Int):
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,first_time,locate('E',mac) as after_convert_1,locate('D',mac,8) as after_convert_2
|from d1
""".stripMargin).show(3, false)
16、lpad:左补齐
rpad:右补齐
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,lpad(mac,20,'--') as left,rpad(mac,20,'--') as right
|from d1
""".stripMargin).show(3, false)
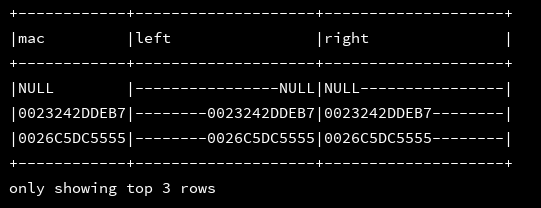
17、ltrim、ltrim、trim:去除做空格,去除有空格,去除左右两边的空格
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,ltrim(mac) as ltrim,trim(mac) as rtrim,trim(mac) as trim
|from d1
""".stripMargin).show(4, false)
18、json_tuple():
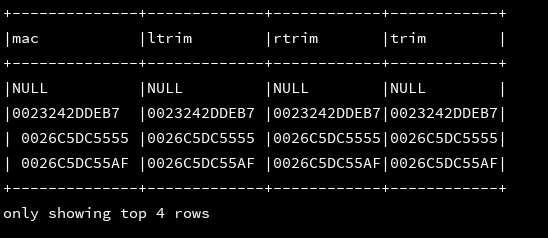
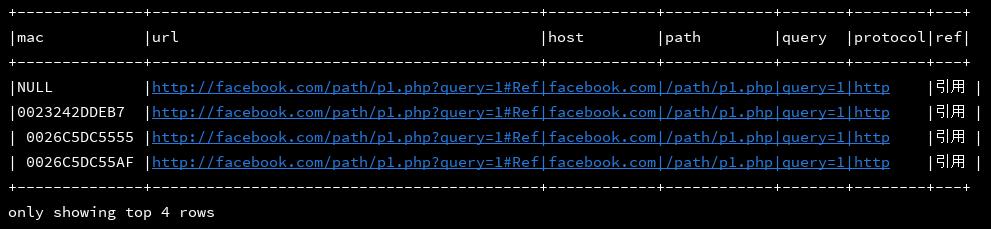
19、parse_url(string url,string par):按照par规则抽取url中的字段
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select mac,'http://facebook.com/path/p1.php?query=1#Ref' as url,
|parse_url('http://facebook.com/path/p1.php?query=1#Ref','HOST') as host,
|parse_url('http://facebook.com/path/p1.php?query=1#Ref','PATH') as path,
|parse_url('http://facebook.com/path/p1.php?query=1#Ref','QUERY') as query,
|parse_url('http://facebook.com/path/p1.php?query=1#Ref','PROTOCOL') as protocol,
|parse_url('http://facebook.com/path/p1.php?query=1#引用','REF') as ref
|from d1
""".stripMargin).show(4, false)
20、repeat(column str,int n):将str重复n次
reverse(column str):将str反转打印
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,reverse(mac) as reverse,repeat(mac,2) as repeat_mac
|from d1
""".stripMargin).show(4, false)

21、regextp_extract(column:col,exp:string,groupId:int):正则提取匹配的组
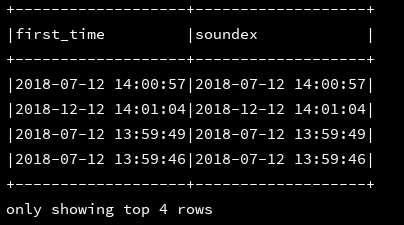
22、soundex (column:col):计算桑迪克斯代码(soundex code)PS:用于按英语发音来索引姓名,发音相同但拼写不同的单词,会映射成同一个码。
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,(first_time) as soundex
|from d1
""".stripMargin).show(4, false)
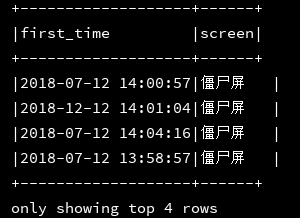
23、rlike:可以通过正则进行where条件匹配
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,screen
|from d1 where screen rlike '僵.*'
""".stripMargin).show(4, false)
24、sentence():
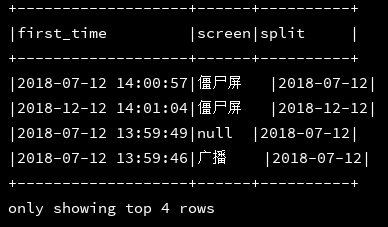
25、split(column:col,string:str):按照str作为分隔符对col进行分割
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,screen,split(first_time,' ')[0] as split
|from d1
""".stripMargin).show(4, false)
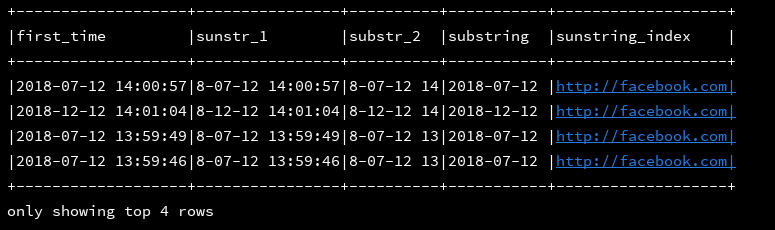
26、substr(column:col,start:int,end:int):截取col中[start,end]之间的字符
substr(column:col,stat:int):截取start开始到结尾的字符
substring(column:col,pos:int,len:int):从col的第pos个字符开始截取长度为len个字符,注意,索引从1开始
substring_index(column:col,delimit:string,count:int):对col使用delimit进行分割,返回分割后count个元素,如果count>0,则从左->右开始算起,如果count<0 则从右—>左开始算起,并拼接起来
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,
|substr(first_time,4) as sunstr_1,
|substr(first_time,4,10) as substr_2,
|substring(first_time,1,11) as substring,
|substring_index('http://facebook.com/path/p1.php?query=1#Ref','/','3')
|from d1
""".stripMargin).show(4, false)
27、translate(src:string,match:string,replace:string):将src中的match全部替换为replace
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,
|translate(first_time,'2018','0000') as translate
|from d1
""".stripMargin).show(4, false)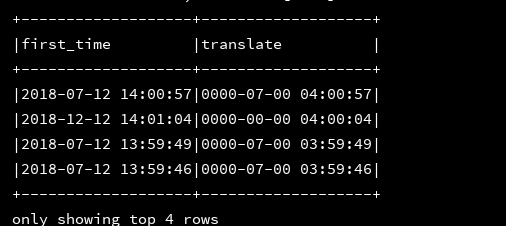
28、
三、日期函数
1、add_months:将指定时间字段的月份加指定的月份数
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,add_months(first_time,3) as after_add from d1
""".stripMargin).show(3)
2、current_date:获取当前的日期
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,current_date() as current from d1
""".stripMargin).show(3)
3、current_timestamp:获取当前的时间
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,current_timestamp() as current_time from d1
""".stripMargin).show(3,false)
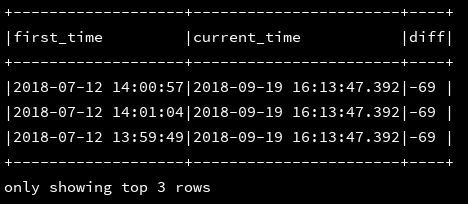
4、datediff(a,b):返回日期a与日期b的时间差,结果是天数
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,current_timestamp() as current_time,datediff(first_time,current_timestamp) as diff from d1
""".stripMargin).show(3,false)
5、date_add:指定天数之后的某几天
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,date_add(first_time,3) as after_add from d1
""".stripMargin).show(3,false)
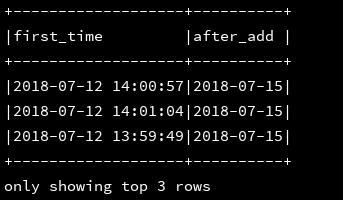
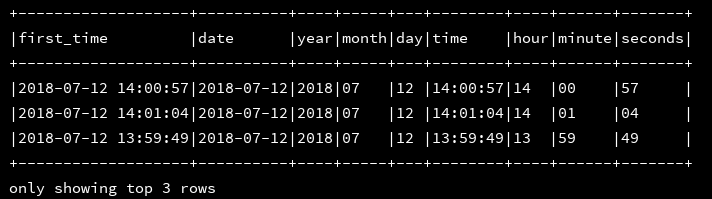
6、date_format:将日期字段(timestamp类型)格式化为想要的格式
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,
|date_format(first_time,'yyyy-MM-dd') as date,
|date_format(first_time,'yyyy') as year,
|date_format(first_time,'MM') as month,
|date_format(first_time,'dd') as day,
|date_format(first_time,'HH:mm:ss') as time,
|date_format(first_time,'HH') as hour,
|date_format(first_time,'mm') as minute,
|date_format(first_time,'ss') as seconds
|from d1
""".stripMargin).show(3,false)
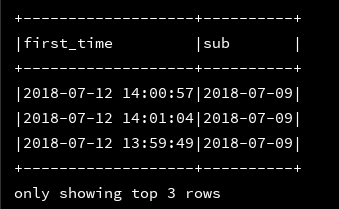
7、date_sub:返回日期的前几天
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,date_sub(first_time,3) as sub
|from d1
""".stripMargin).show(3,false)
8、day:返回日期中的天
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,date_sub(first_time,3) as sub
|from d1
""".stripMargin).show(3,false)
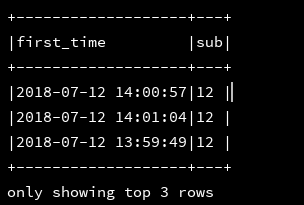
9、dayofyear:返回给定时间中day是这一年中的第几天,返回一个数字
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,dayofyear(first_time) as day
|from d1
""".stripMargin).show(3,false)
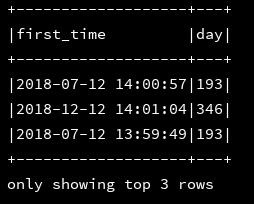
10、dayofmonth:返回给定时间中的天是该月的第几天
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,dayofmonth(first_time) as month
|from d1
""".stripMargin).show(3,false)
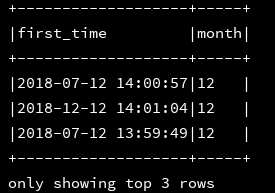
11、from_unixtime:
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,from_unixtime(tm,'yyyy-MM-dd HH:mm:ss') as after_convert
|from d1
""".stripMargin).show(3,false)注:这里的tm必须是时间秒数,例如(1250111000)
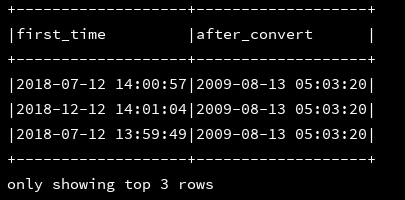
12、from_utc_timestamp :如果给定的时间戳并非UTC,则将其转化成指定时区下的时间戳
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,from_utc_timestamp(first_time,'PST') as after_convert //将first_time(默认是UTC时区时间)转换为PST时区的时间戳
|from d1
""".stripMargin).show(3,false)
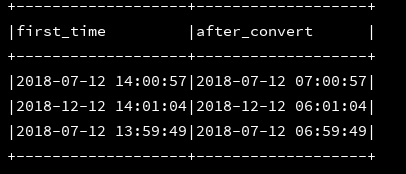
13、hour:返回指定时间戳的小时
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,hour(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
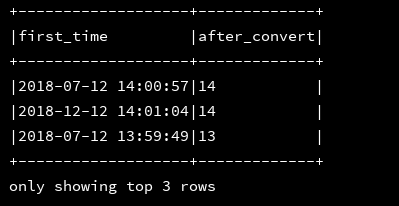
14、last_day:返回给定时间戳的当月的最后一天的日期
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,last_day(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
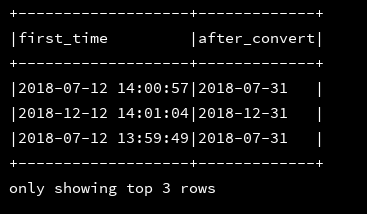
15、minute:返回指定时间戳的分钟数
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,minute(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
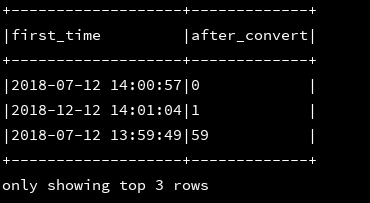
16、month:返回指定时间戳的月
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,month(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
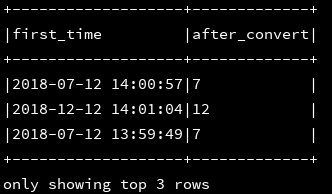
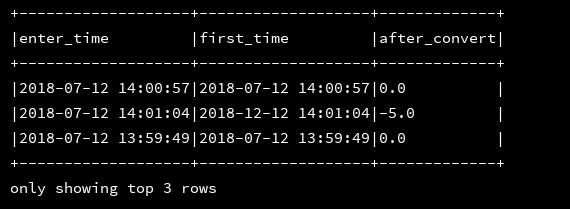
17、months_between:返回两个时间戳月份的时间差
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select enter_time,first_time,months_between(enter_time,first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
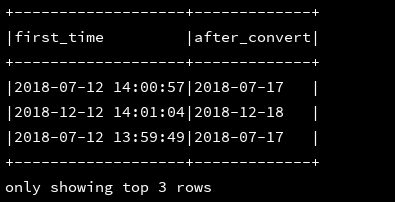
18、next_day:返回指定时间戳的一周之后的这天
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,next_day(first_time,,'TU') as after_convert //返回first_time开始,下周的星期二的日期
|from d1
""".stripMargin).show(3,false)
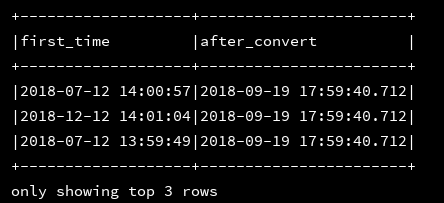
19、now:放回当前的时间戳
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,now() as after_convert
|from d1
""".stripMargin).show(3,false)
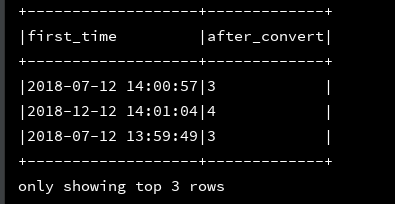
20、quarter:返回指定时间戳是在该年中的第几个季度
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,quarter(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
21、second:返回给定时间戳的秒数
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,second(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
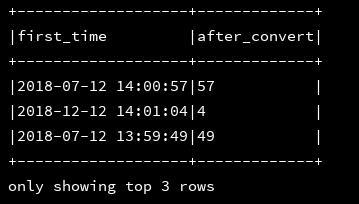
22、to_date:返回时间字符串的日期部分
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,to_date(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
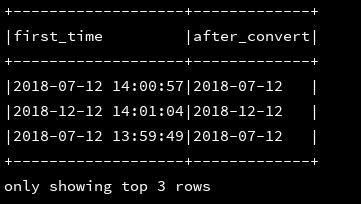
23、to_unix_timestamp:根据提供的字符串格式转换成Unix时间
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,to_unix_timestamp('16/Mar/2017:12:25:01 +0800','dd/MMM/yyyy:HH:mm:ss Z') as after_convert
|from d1
""".stripMargin).show(3,false)
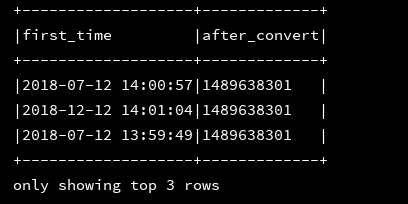
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,to_unix_timestamp(first_time,'yyyy-MM-dd HH:mm:ss') as after_convert
|from d1
""".stripMargin).show(3,false)

24、to_utc_timestamp:将指定的时间戳转换为UTC下的时间戳
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,to_utc_timestamp(first_time,'yyyy-MM-dd HH:mm:ss') as after_convert
|from d1
""".stripMargin).show(3,false)

25、trunc:返回指定时间最开始的年份或是月份(只支持MONTH/MON/MM,YEAR/YYYY/YY)
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,trunc(first_time,'MM') as after_convert
|from d1
""".stripMargin).show(3,false)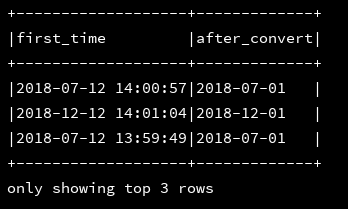
26、unix_timestamp:转换时间字符串格式yyyy-MM-dd HH:mm:dd 到unix时间(秒),如果不加参数的话,则获取的是当前的时间的unix时间
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,unix_timestamp(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
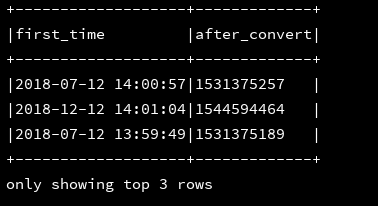
27、weekofyear:返回指定的时间戳是该年中第几周
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,weekofyear(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)
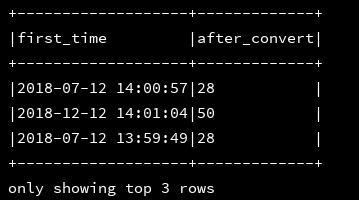
28、year:返回指定时间戳中的年
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select first_time,year(first_time) as after_convert
|from d1
""".stripMargin).show(3,false)四、聚合函数(尽量结合分组函数group/groupBy使用)
1、count():求总条数
avg():求平均值
sum():累加求和
mean():求平均值
max():求最大值
min():求最小值
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select phone_brand,
|count(phone_brand) as count,
|avg(stay_long) as avg,
|mean(stay_long) as mean,
|min(stay_long) as min,
|max(stay_long) as max,
|sum(stay_long) as sum
|from d1 group by phone_brand
""".stripMargin).show(4, false)

2、var_pop:求总体方差(方差:)
stddev_pop:求总体的标准差(标准差:方差开方既得)
skenwness:偏度
kurtosis:峰态值
df_1.createOrReplaceTempView("d1")
ssc.sql(
"""
|select phone_brand,
|var_pop(stay_long) as fc,
|stddev_pop(stay_long) as bzc,
|skewness(stay_long) as pd,
|kurtosis(stay_long) as ftz
|from d1 group by phone_brand
""".stripMargin).show(4, false)















 2031
2031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









